Save to My DOJO

For your high-availability strategy to be successful, your infrastructure needs to not only be resilient to quick planned and unplanned outages but also long-term failures. Windows Server Failover Clustering (WSFC) is the standard solution when comes to providing high-availability (HA) for Hyper-V virtual machines (VMs) and other Microsoft workloads. The cluster can even be stretched across different physical locations to provide a disaster recovery (DR) solution in the event that there is a datacenter-wide outage, allowing these services to automatically move to a different site. But one of the fundamental challenges is that this solution was originally designed to sustain short-term failures of a few minutes or hours. But what happens if there is a natural disaster and the outage may last for days or even be permanent? The latest releases of Windows Server have added features to specifically address these scenarios. This article will review dynamic quorum in clusters so that you can now automatically adjust how many nodes need to stay online to keep your workloads running.
Introduction to Quorum
The first concept you need to understand is quorum, which is a membership algorithm that determines which nodes stay online and which remain dormant if they cannot communicate with each other. This is important to avoid a “split-brain” scenario, where you have a partition between cluster nodes and they cannot determine which hosts should run which workloads. Having a consistent and global view of the cluster is critical as only one node should run each VM or workload. If two hosts are trying to run the same VM at the same time, then they will be writing to the same shared storage disk in an uncoordinated fashion, which can cause corruption. To avoid this, a majority (51% or more) of nodes or voting disks (the “disk witness”) must be online, in communication with each other, and see the consistent view of the cluster. This group of nodes which “has quorum” will run all the workloads. The isolated node(s) will not attempt to host workloads until they communicate with a quorum of nodes. Since this blog will look at some of the more advanced scenarios, any readers who are unfamiliar with quorum are encouraged to review the Altaro blog series on Quorum and Cloud File Share Witness.
Forcing Quorum in a Failover Cluster
Over 90% of all businesses are running a 2-node cluster with one voting disk witness (3 total votes) to minimize their hardware costs. But what if this disk fails and cannot quickly be recovered because you need to wait for your storage administrator to repair it? This means that both nodes need to stay online for the cluster to maintain quorum with 2 of 3 votes. Any planned or unplanned failure on either node will cause the cluster to lose quorum with only 1 of 3 votes, and all workload will stay offline.
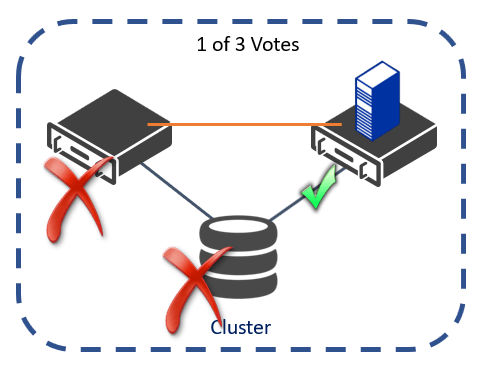
Forcing Quorum with a Single Node in a Failover Cluster
Microsoft has provided a switch to allow you to “fix quorum” and force workloads to start on a specific cluster node (or set of nodes) so that your critical applications can still run without having a majority of nodes online. This is done using the -FixQuorum switch when starting a cluster node with PowerShell:
PS C:> Start-ClusterNode -FixQuorum
Keep in mind that if some of your nodes are offline and you run all of your production workloads on the remaining one(s) that this will likely cause a performance hit. One option is to deprioritize certain VMs by disabling automatic restart so that they will remain dormant and not contend for resources with important applications. This is configured for each virtual machine by setting the properties of the Automatic Start Action to “Nothing” as showing in the figure below.
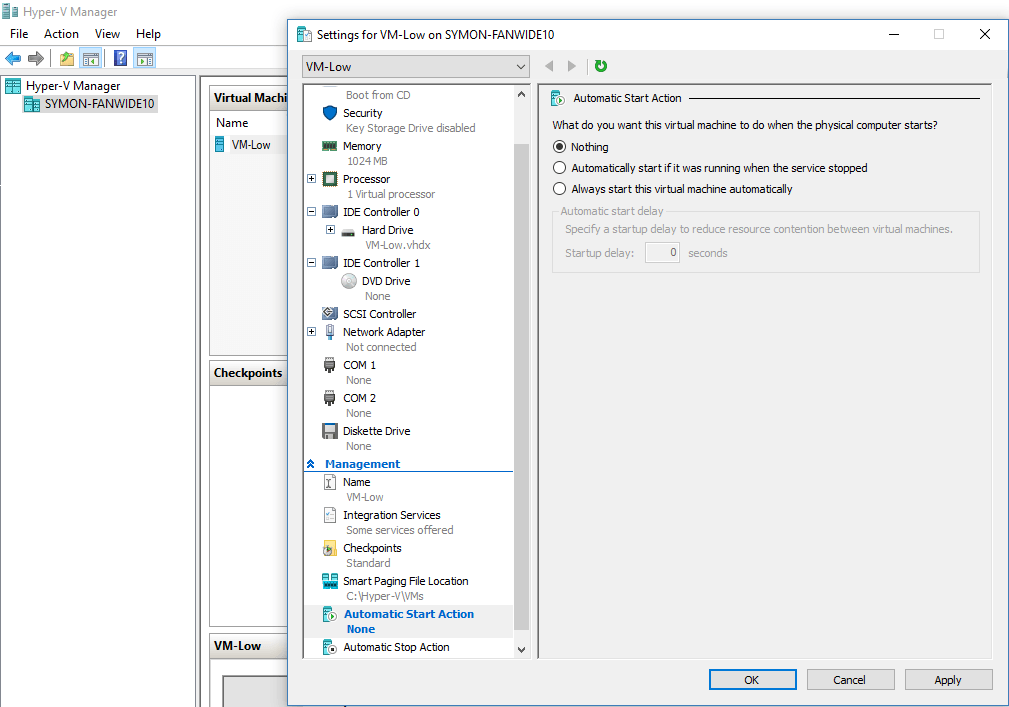
Disabling Automatic Start Action for a Hyper-V VM
Forcing Quorum in a Multi-Site Cluster
In a multi-site cluster, partitions usually happen between the sites. This could be a temporary outage due to a network partition, or one datacenter has a full outage. A recommendation when designing a multi-site cluster is to have an identical configuration at each site, which means the same number of cluster nodes. In this case, you will generally use a Cloud Witness Disk in Microsoft Azure as your extra vote, which is a voting disk hosted in Azure. However, if your datacenter cannot access either your secondary site nor this extra voting disk, then you will lose quorum as shown in the following figure. In this case, you will want to force quorum on your primary site to bring your services only, even though you do not have a majority of votes (3 of 7).
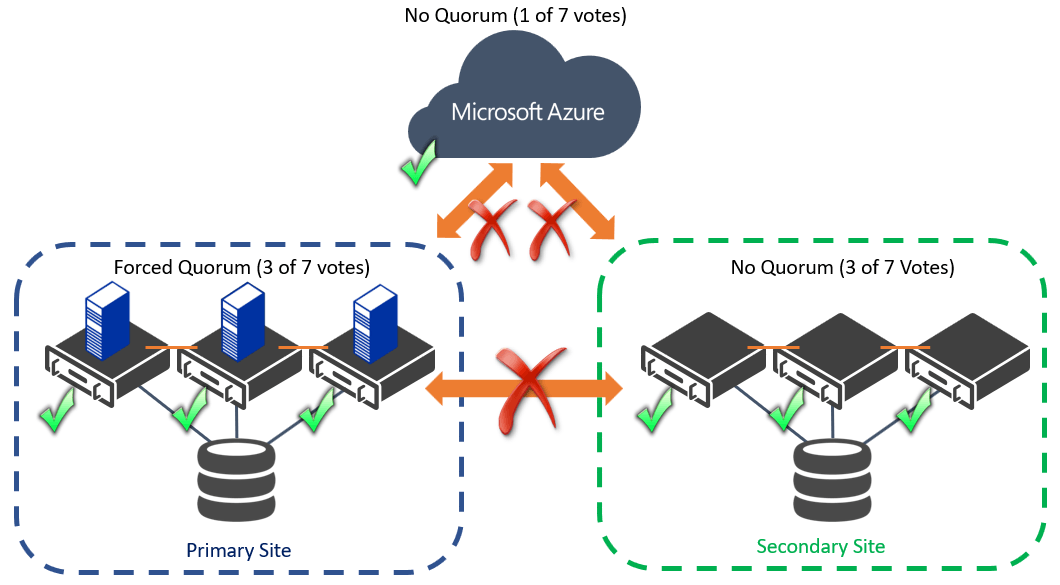
Forcing Quorum with a Partition in a Balanced Multi-Site Cluster
Forcing quorum can also be useful if you have an unbalanced multi-site cluster, which is a deployment option for organizations that may not have the hardware to deploy a balanced cluster. In this type of configuration, the primary site will be able to host all the workloads, but if a disaster happens only critical services should run in the secondary site. This secondary site is unlikely to ever achieve quorum, so it may need to be forced online in a disaster recovery scenario, as shown in the figure below.
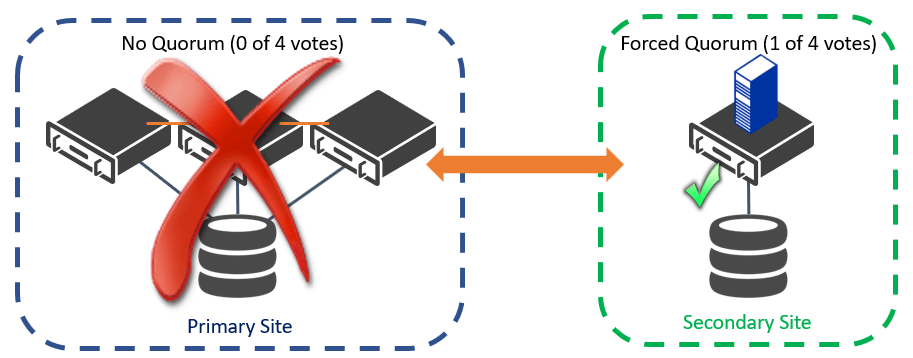
Forcing Quorum with a Partition in an Unbalanced Multi-Site Cluster
Another consideration to be aware of is the behavior of forcing quorum during transient failures. If quorum is forced, but then the cluster regains quorum because other nodes have rejoined it will no longer be in the forced quorum state. If a node then drops out of membership and the cluster loses quorum again, the cluster will remain offline and you need to force quorum once again. Although this process is not ideal, forcing quorum can be automated through PowerShell and a monitoring solution like System Center Operations Manager or Task Scheduler.
Cluster Node Vote Weight in a Failover Cluster
Instead of forcing quorum and worrying about transient failures, a better solution is to adjust the node vote weight. This means that you can manually or automatically toggle whether a particular node has 1 or 0 votes counted towards quorum membership. This allows you to keep the cluster running provided that at least one node (or vote) is online. Essentially, as cluster nodes drop out of membership, you may reduce the number of remaining votes left in the cluster. This is nicknamed the “last man standing” quorum model – so long as one voter is online, the cluster stays running. If the same node frequently crashes, then you can assign this node 0 votes so that it essentially has no impact on the rest of the cluster. However, if different nodes lose availability at different times, it is a little harder to change the quorum weight as you need a more advanced PowerShell script which can dynamically change the node vote weight for different nodes. Also, consider that if you will likely have a performance hit if you have a single node that is now hosting all the services which were previously distributed across multiple nodes. One option is to set the vote weight to 0 for every cluster node and use a witness disk (with 1 vote) as the only voter. Provided that this single disk stays online and can be accessed by any cluster node, the cluster will stay online. This is risky as losing connectivity to that disk can take down your cluster. Later in this blog, we will show you how to configure node vote weight from either Failover Cluster Manager or PowerShell.
Cluster Node Vote Weight in a Multi-Site Cluster
If you have a balanced multi-site site cluster, then adjusting the node vote weight is a practical way to increase your service availability if you lose one of your sites. Let’s say you have deployed your multi-site cluster while using the best practices of having at least three nodes in both locations (3 votes + 3 votes) and having a Cloud Witness Disk as an extra vote (7 total votes). If you have a long-term failure of one site due to a genuine disaster, then you have only 4 of 7 voters available, so you could not have any other outages at your primary site. Previously you would have to evict all the nodes from the cluster (then later add and validate them) which was a time-consuming process and may cause other configuration inconsistencies. Instead, you can just switch to node vote weight to 0 for those nodes on the faulty site without removing them from the cluster. Since you no longer need the extra vote running in Azure as the Cloud Witness, you can drop this from the quorum configuration also. This means that you only have to worry about keeping 2 of the 3 remaining votes online, allowing you to sustain the failure of any node at the healthy site as shown in the following figure.
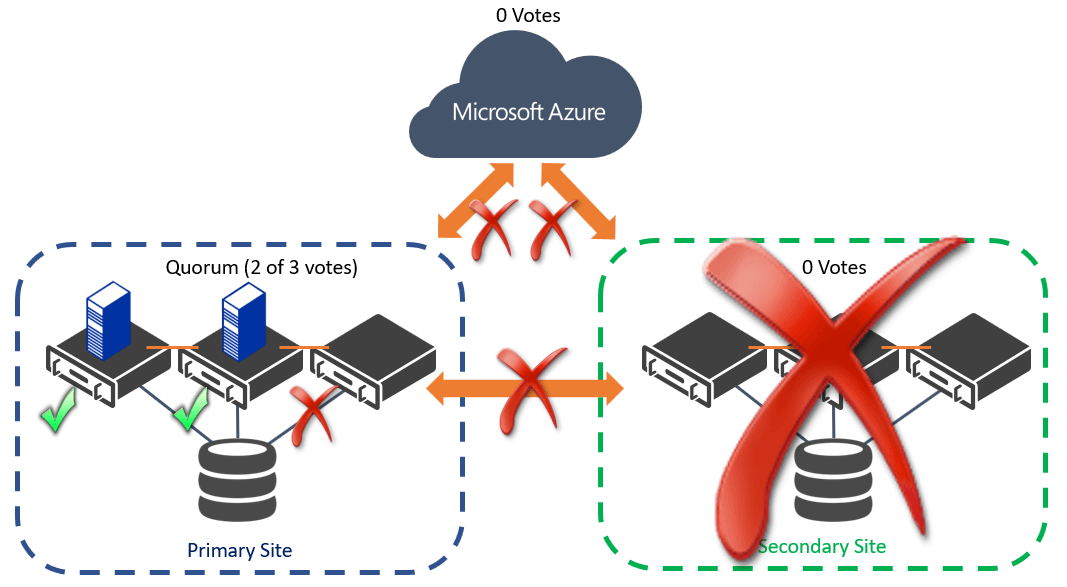
Changing the Node Vote Weight on a Multi-Site Cluster during a Long-Term Outage
How to Adjust the Node Vote Weight
Now that you understand the scenarios for adjusting the node vote weight, we’ll show you how to do it. You can adjust it through the Failover Cluster Manager interface using the Configure Cluster Quorum Wizard as shown in the following figure. Simply select which nodes have a vote and which are not counted towards quorum.
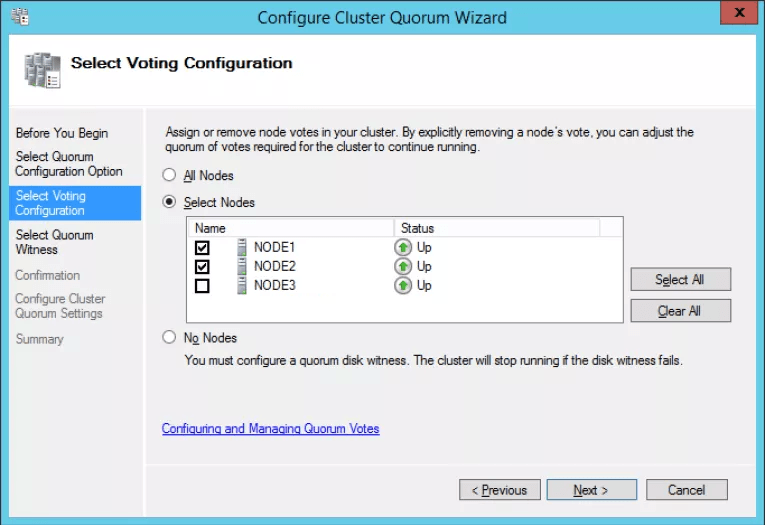
Adjusting the Node Vote Weight from Failover Cluster Manager
To automate the assignment of the node vote weight you will use PowerShell to dynamically adjust whether each node has a vote. This is useful in a real disaster when you may not able to rely on your staff. After you have verified that the site is offline you can trigger a PowerShell script from the healthy site which sets the nodes at the failed site to not have a vote. In the following example you can set the weight of nodes 4, 5, and 6 to not have a vote with the following cmdlets:
PS C:> $node4 = “ClusterNode4” PS C:> (Get-ClusterNode $node4).NodeWeight = 0 PS C:> $node5 = “ClusterNode5” PS C:> (Get-ClusterNode $node5).NodeWeight = 0 PS C:> $node6 = “ClusterNode6” PS C:> (Get-ClusterNode $node6).NodeWeight = 0
Once the other site is back online, you can automatically reset these values using similar syntax.
Wrap-Up
Dynamically adjusting the quorum in your cluster is a powerful tool to provided extras resiliency for multi-site clusters and for long-term failures, but make sure that you always remember to reset all the votes across your cluster. If you have any questions about these different scenarios or cluster quorum, feel free to post questions below and one of our cluster experts will provide you with guidance.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Symon Perriman


14 thoughts on "What is Quorum Vote Weight in a Windows Server Failover Cluster?"
how to fix in manually failover windows 2019 cluster failed….
McAfee ePO 5.10 in adserver2019
Hi Mushtaq,
Unfortunately there’s not enough information in your question to be able to give you a good answer. Are you saying that a manual failover in a Windows Server 2019 cluster failed? What kind of failover cluster? Hyper-V? And since McAfee MVISION ePO is a SaaS service I’m not sure how that relates to the failover cluster?
If you can clarify we might be able to give you an answer.
Paul Schnackenburg, Altaro DOJO Technical Editor