One of the primary draws to virtualization is the resilient nature of virtual machines. They can be transported across hosts without downtime. The files for a backed up virtual machines can be used on any host running the same hypervisor as the original. When combined with Microsoft Failover Clustering, Hyper-V can use a multi-host strategy to increase this resiliency even further.
Understanding High Availability
Despite widespread usage in the infrastructure technology industry, many people do not quite understand what the term “high availability” means. It is not a technology or a group of technologies. In the strictest sense, it’s not really even a class of technologies. “High availability” is an arbitrary target metric.
If a single server is running an application that isn’t offline for more than a total of five minutes in a calendar year, then it has a 99.999% uptime rating (known as 5 nines) and would, therefore, qualify as being “highly available” by most standards. The fact that it isn’t using anything normally recognized as a “high availability” technology does not matter. Only the time that it is available is important.
It is up to each organization to create its own definition of “high availability”. Sometimes, these are formal metrics. A hosting company may enter into a contractual agreement with its customers to provide a solution and guarantee a certain level of availability; such an agreements is typically known as a Service Level Agreement (SLA).
An IT department can also make similar agreements with other business units within the same organization; these are often called Operational Level Agreements (OLA). Agreements will vary in their scope and complexity. Some agreements only count unexpected down time against the metric where others count any down time. Some specify monetary reimbursement, some provide for services compensation, others provide for no remuneration at all.
Not everyone will formalize their agreements. This would simply be known as “best effort” high availability. This is common in smaller organizations where the goal isn’t necessarily the ability to measure success but to ensure that systems are architected with availability as a priority.
A term often confused with high availability is “fault tolerance”. Fault tolerance is a feature of some software and hardware components that allow them to continue operating even when there is a failure in a subsystem. For instance, a RAID array continues operation when a member fails is considered “fault tolerant”.
Hyper-V and Fault Tolerance
Hyper-V itself has no true fault tolerance capability. It is built on the Windows Server kernel which can compensate for some hardware failures, but overall, it relies on hardware features to provide true fault tolerance. The main thing to note is that Hyper-V has no ability to continue running a virtual machine on a host that crashes without interruption to the virtual machine.
Hyper-V and High Availability
Failover Clustering is a technology that Microsoft developed to protect a variety of applications, including third party software and even custom scripts. Hyper-V is one of the applications that is natively supported. As with most other technologies, Failover Clustering provides Hyper-V with a “single active node, one or more passive nodes” protection scheme. However, it provides this protection at the virtual machine level. Any particular virtual machine can only be running on a single node at any given time, but every node in a failover cluster can actively run virtual machines simultaneously.
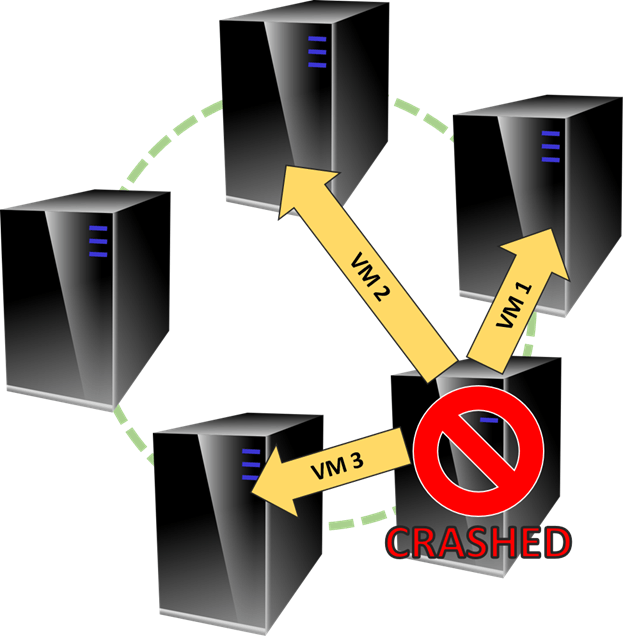
Failover clustering contributes to high availability by reducing the impact of host down time on guests. If a non-clustered Hyper-V host fails, its guests are offline until the host can be recovered or its contents restored to a replacement system. If a clustered host fails and there is sufficient capacity across the surviving nodes, all guests are re-activated within seconds. This cuts the unexpected downtime of a virtual machine to a fraction of the expectation of a physical system.
Appropriateness and Requirements of Clustering
Not every organization should cluster Hyper-V. Compared to standalone hosts, clustering is expensive in both equipment and maintenance overhead. Most of the maintenance can be automated, but configuring and maintaining such automation presents its own burdens.
Host Hardware Requirements
It is not necessary for all of the nodes in a cluster to be identical. Windows Server/Hyper-V Server will allow you to create a cluster with any members running the same version of the management operating system; it will even allow members running different editions. However, the further you stray from a common build, the less likely you are to achieve a supportable cluster. Running in an unsupported configuration may not provide any benefits at all.
Even if the system allows a cluster, these items should be considered the gold standard for a successful cluster:
- Use equipment listed on Windows Server Catalog. Be aware that Microsoft does not specifically certify for a cluster configuration.
- Use hosts with the same processor manufacturer. You will be completely unable to Live Migrate, Quick Migrate, or resume a saved guest across systems from different manufacturers. They will need to be completely turned off first. This requirement breaks the automated failover routines.
- Use hosts with processors from the same family. There is a setting to force CPU compatibility, but this causes the guest to use the lowest common denominator of processor capabilities, reducing its run-time effectiveness simply to increase the odds of a smooth failover.
Shared Storage Requirements
A failover cluster of Hyper-V hosts requires independent shared storage. This can be iSCSI, Fibre Channel, or SMB 3+. None of the Hyper-V cluster nodes can directly provide the storage for clustered virtual machines (although they can provide storage for local, non-clustered guests).
Hyper-V Cluster Networking Requirements
A standalone Hyper-V system can work perfectly well with a single network card. A Hyper-V cluster node cannot. The introduction of converged network has greatly reduced the requirement of having at least three physical network adapters (four if iSCSI is used), but two should still be considered the absolute minimum.
Whether physical adapters or virtual adapters, a Hyper-V cluster node requires the following distinct IP networks:
- Host management
- Cluster communications
- iSCSI (if iSCSI is used to store virtual machines) and/or SMB (if SMB is used to store virtual machines)
To minimize congestion issues, especially when using 1GbE adapters, a fourth IP network for Live Migration traffic is highly recommended. In order for clustering to use them all appropriately, each separate adapter (again, physical or virtual) must exist in a distinct IP network. The clustering service will use only one adapter per IP network per physical host for any given network.
Cluster Validation
No matter what, use the Cluster Validation wizard as explained in section 4.1 to verify that your cluster meets all expectations.
How to Determine if a Cluster is an Appropriate Solution
There is no universal rule to guide whether or not you should build a cluster. The leap from internal storage to external, shared storage is not insignificant. Costs are much higher, staff may need to be trained, additional time for maintenance will be necessary, and additional monitoring capability will need to be added. Not only do you need to acquire the storage equipment, but networking capability may also need to be expanded.
In addition to storage, most clusters are expected to add some resiliency. Generally, clusters will be expected to operate in at least an N + 1 capacity, which means that you will have sufficient nodes to run all virtual machines plus an additional node to handle the failover load. While you can certainly run on all nodes when they’re operational, it’s still generally expected that the cluster can lose at least one and continue to run all guests. This extra node has its own hardware costs and incurs additional licensing for guest operating systems.
It is up to you to weigh the costs of clustering against its benefits. If you’re not certain, seek out assistance from a reputable consultant or engage Microsoft Consulting Services.
Failover Clustering Concepts
As explained in the Hyper-V virtual networking configuration and best practices article, a cluster needs a network just for cluster communications. One of the things that will occur on this network is a “heartbeat” operation. All nodes will attempt to maintain almost constant contact with every other node and, in most cases, a non-node arbiter called a quorum disk or quorum share. When communications do not work as expected, the cluster takes protective action. The exact response depends upon a number of factors.
Quorum
The central controlling feature of the cluster is quorum. Ultimately, this feature has only one purpose: to prevent a split-brain situation. Because each node in the cluster refers to virtual machines running from one or more common storage locations, it would be possible for more than one node to attempt to activate the same virtual machine. If this were to occur, the virtual machine would be said to have a split brain. Furthermore, if multiple nodes were unable to reach each other but the cluster continued to operate on all of them, the cluster itself would be considered to be in split-brain, as a cluster should be a singular unit.
There are multiple quorum modes and advanced configurations, but the most simplistic explanation is that quorum strives for a majority of nodes to be online in order for the cluster to function. By outward appearances, quorum appears to function as an agreement of active nodes. It would be somewhat more correct to say that quorum is controlled from the perspective of each node on its own. If a node is unable to contact enough other systems to achieve quorum, it voluntarily exits the cluster and places each clustered virtual machine that it owns in the state dictated by its Cluster-controlled offline action. This means that if there aren’t enough total votes for any node to maintain quorum, the entire cluster is offline and no clustered virtual machines will run without intervention.
By default, quorum is dynamically managed by the cluster and it’s recommended that you leave it in this configuration. You will need a non-node witness, which can be an iSCSI or Fibre Channel LUN or an SMB share (it can be SMB 2). In earlier versions of Hyper-V, this witness was only useful for clusters with an even number of nodes. Starting in 2012 R2, Dynamic Quorum works best when there is an independent witness regardless of node count. If you’d like to explore the various advanced options for quorum read more here.
Failover Clusters
Arguably, the greatest reason to cluster at all is clustering’s failover capability. Cluster nodes exchange information constantly in a mesh pattern. Every node communicates directly with every other node. When something changes on one node, all the others update their own local information. You can see much of this reflected in the registry under HKEY_LOCAL_MACHINE\Cluster. If a quorum disk is present, information is stored there as well.
Whereas quorum is primarily node-centric, the failover process is the opposite. When a node ceases to respond to communications, the remaining nodes that still have quorum “discuss” the situation and determine how its virtual machines will be distributed. The exact process is not documented, but the general effect is a fairly even distribution of the guests. If there are insufficient resources available across all remaining nodes, lower priority virtual machines are left off. If all virtual machines have the same priority, the selection criteria appears to be mostly random.
Guest Migrations
A cluster of Hyper-V nodes provides the ability to rapidly move virtual machines from one to another. The original migration method is known as Quick Migration. The virtual machine is placed in a saved state, ownership is transferred to another host, and the virtual machine’s operations are restored there. No data, CPU activities, or I/O operations are lost, but they are paused. Remotely connected systems will lose connectivity for the duration of the migration and any of their pending operations may time out. The time required for a Quick Migration depends on how long it takes to copy the active memory contents to disk on the source and return them to physical memory on the destination.
The more recent migration method is called Live Migration. This is a more complicated operation that does not interrupt the virtual machine. Contents of system memory are transferred to the target while operations continue at the source. Once all the latent memory is transferred, the machine is paused at the source, the remaining bits are transferred, and the machine is resumed at the destination. The pause is so brief that connected systems are rarely aware that anything occurred. Networking is one potential exception. The MAC address for the guest is either changed or transitioned to the destination host’s physical switch port. This requires a few moments to replicate through the network topology. The transition occurs well within the TCP timeout, but inbound UDP traffic is likely to be lost.
Basic Clustering Guidance
Clustering may be new to you, but it is not an overly difficult concept to learn, implement, and maintain. It offers many solid benefits that make it worthwhile for many organizations. Take the time to discover its capabilities and measure their value against your organization’s needs. The information presented in this article encompasses the major points and should be all you need to know in order to make the best decision.



