Save to My DOJO

Storing data is a “killer application” for the public cloud and it was one of the services adopted early by many businesses. For your unstructured data such as documents, video/audio files, and the like, Azure Blob storage is a very good solution.
In this article, we’ll look at what Blob Storage is, how it works, how to design resiliency and data protection based on your business scenarios, and how to recover from outages and disasters.
Azure Storage Overview
It all starts with a storage account, inside of which you can have one or more containers, each of which can store one or more blobs (Binary Large Objects). The names of accounts and containers need to be in lowercase and they’re reachable through a URL by default and thus need to be unique globally. Blobs can be Block blobs for text and binary data and each one can be up to 4.75 TiB, with the new limit of 190.7 TiB in preview. Append blobs are similar to block blobs but are optimized for append/logging operations. Page blobs are used to store random access files up to 8 TiB and are used for virtual hard drive (VHD) files for VMs. In this article, we’re focusing on block and append blobs.
Throughout this article and in Azure’s documentation Microsoft uses TebiByte (TiB), which is equivalent to 240 or 1,099,511,627,776 bytes, whereas a TeraByte (TB) is 1012 bytes or 1,000,000,000,000 bytes. You know that fresh 4 TB drive that you just bought and formatted and only got 3.6 TB of usable storage from? This is why these newer names (kibi, mebi, gibi, pebi, exbi, zebibytes) are more accurate.
Storage accounts also provide Azure Files, think Platform as a Service managed file shares in the cloud, and Azure File Sync which lets you connect your on-premises file servers to Azure and keep only frequently used files locally and sync cold data to Azure. Both of these fantastic solutions are not the topic of this article.
There are two generations of storage accounts, general purpose V1 and V2. In most scenarios, V2 is preferred as it has many more features.
To get your data from on-premises to the cloud over the network you can use AzCopy, Azure Data Factory, Storage Explorer (an excellent free, cross-platform tool for managing Azure storage), and Blobfuse for Linux. For offline disk transfers, there is Azure Data Box, -Disk, and -Heavy, along with Azure Import/Export where you supply your own disks.
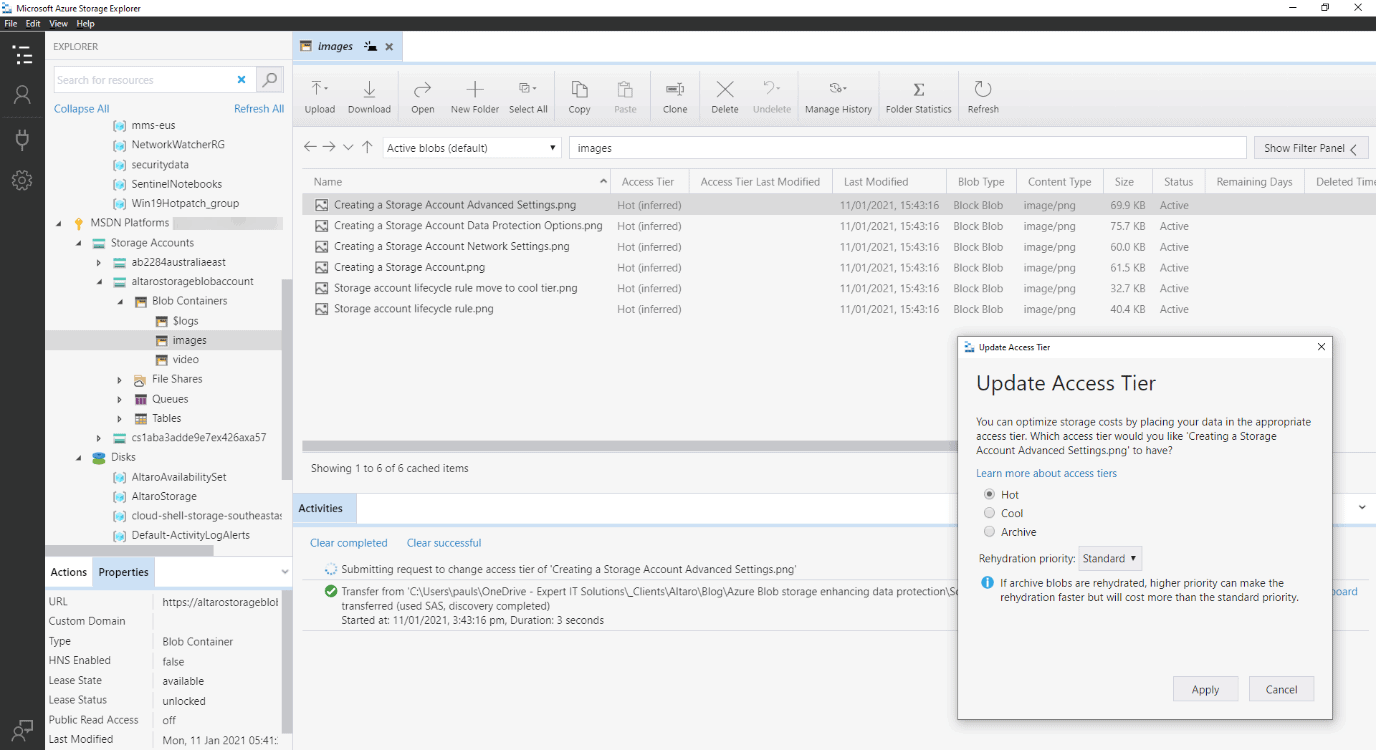
Azure Storage Explorer – manually setting access tier
Blob storage is hard-drive-based but there is an option for premium block blob storage accounts which is optimized for smaller, kilobyte-range objects and high transaction rates / low latency storage access.
Resilience
One of the best features of Azure Blob storage is that you won’t lose your data. When designing storage solutions for on-premises building high availability is challenging and requires good design, WAN or MAN replication and other costly technical solutions. In the cloud, it’s literally a few tick boxes. Picking the right level of data protection and recovery capabilities does require you to understand the options available to you and their cost implications.
Note that this article is looking at Blob storage for an application that you’re developing in-house, for VM resiliency look at this blog post on Azure Availability Sets and Zones, if you’re looking at using Blob storage for long term archiving of data look here and if you need a tutorial on setting up storage look here. You can also use Blob storage to serve images or documents directly in a browser, streaming video or audio, writing to log files, store backup, DR and archiving data or store data for Big Data analysis.
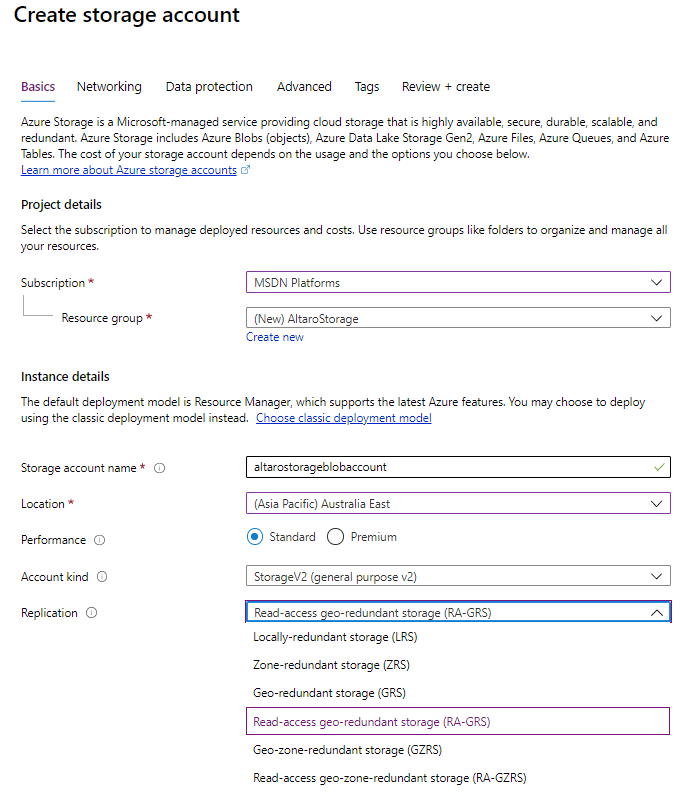
Creating Storage Account Replication options
The simplest level of data protection is Locally redundant storage (LRS) which keeps three copies of your data in a single region. Disk and network failures, as well as power outages, are transparently hidden from you and your data is available. However, a failure of a whole datacenter will render your stored data unreachable. Zone redundant storage (ZRS) will spread your three copies across different datacenters in the same region and all three copies have to be written for the write to be acknowledged. Since each datacenter has separate power, cooling, and network connections, your data is more resilient to failures. This is reflected in the guaranteed durability, LRS gives you 99.999999999% (11 nines) over a given year, whereas ZRS gives you 99.9999999999% (12 9’s). Not all regions support zones and ZRS yet. In the event of a large-scale natural disaster taking out all datacenters in an entire region however you need even better protection.
Geo-redundant storage (GRS) keeps three copies in your primary region and also copies them asynchronously to a single location in a secondary, paired region. In regions where zones are supported, you can use Geo-zone-redundant storage (GZRS) instead, which uses ZRS in your primary region and again copies it asynchronously to a single location in the secondary region. There’s no guaranteed SLA for the replication but “Azure Storage typically has an RPO of less than 15 minutes”. Both GRS and GZRS gives you 99.99999999999999% (16 9’s) durability of objects over a given year. This provides excellent protection against a region failing but what if you’d like to do something with the replicated data such as periodic backups, analysis, or reporting?
To be able to do this, you need to choose read-access geo-redundant storage (RA-GRS) or read-access geo-zone-redundant storage (RA-GZRS). This provides the same durability as GRS/GZRS with the addition of the ability to read the replicated data. Predictably the cost of storage increases as you pick more resilient options. Unless Microsoft declares a region outage you have to manually fail over a storage account, see below.
Providing Access
As mentioned, each storage account has a URL but data isn’t public and you need to set up authentication correctly to ensure that the right people have access to the appropriate data, and no one else. When you create a Storage account you can set up which networks it can be accessed from. You can pick from a public endpoint – all networks (suitable if you must provide access to users from the internet), public endpoint – selected networks (pick vNet(s) in your subscription that can access the account), or a private endpoint.
Each HTTPS request to a storage account must be authorized and there are several options for controlling access. You can use a Shared Key, each storage account has a primary and a secondary key, the problem with this approach is that the access is very broad and until you rotate the key, anyone with the key has access to the data. Another, older method, is Shared access signatures (SAS) which provides very specific access at the container or blob level, including time-limited access. The problem is again that someone else could obtain the SAS and use it to access data. The recommended method today is to use Azure Active Directory (AAD) to control access. For blob storage, you can also provide anonymous public read access which of course is only suitable for a few business scenarios.
Tiering
Blob storage accounts let you tier your data to match the lifecycle that most data go through. In most cases, data is accessed frequently when it’s just created and for some time after that, after which access decreases as it ages. Some data is just dumped in the cloud and rarely accessed, whereas other data is modified frequently over its entire lifetime.
These three tiers are hot, cool, and archive. The cool tier is the same hard disk-based storage as the hot tier, but you pay less for storing data at this tier, provided you don’t access it frequently. An example would be relatively recent backup data, you’re unlikely to access it unless you need to do a restore. The archive tier on the other hand is tape-based and rehydrating/retrieving the data can take up to 15 hours, but it is the cheapest storage tier.
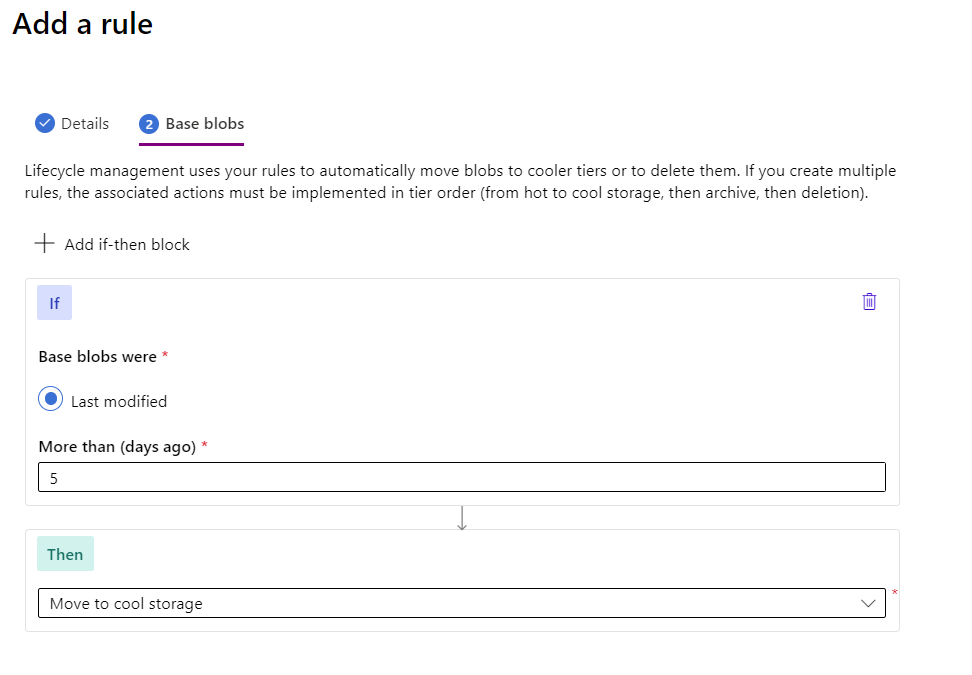
Storage account lifecycle rule move to cool tier
You can set the tier of a blob programmatically in your application or you can use lifecycle management policies. This lets you do things such as transition blobs from hot to cool, hot to archive, or cool to archive based on when it was last accessed, delete blobs and versions/snapshots at the end of their lifecycle, and apply these rules at the container level or on a subset of blobs.
Data Protection
Now that we’ve looked at the basics of storage accounts, blobs, tiering, and geographical resilience, let’s look at the plethora of features available to manage data protection.
Blob versioning is a fairly new feature (for general purpose V2 only) that creates a new version of a blob whenever it’s modified or deleted. There’s also an older feature called Blob Snapshots that also creates read-only copies of the state of a blob when it’s modified. Both features are also billed in the same way and you can use tiering with versions or snapshots, for instance keeping current data on the hot tier and the older versions on the cool tier. The main difference between the two is that snapshots is a manual process that you have to build into your application, whereas versioning is automatic once you enable the feature. Another big difference is that if you delete a blob, its versions are not deleted automatically, with snapshots you have to delete them to be able to delete a blob. There’s no limit on the number of snapshots/versions you can have but Microsoft recommends less than 1000 to minimize the latency when listing them.
To protect you against users deleting the wrong document or blob by mistake you can enable soft delete for blobs and set the retention period between 1 and 365 days. Protecting entire containers against accidental deletion is also possible, currently, it’s in preview. Note that neither of these features helps if an entire storage account is deleted – but a built-in feature in Azure called Resource locks allows you to stop accidental deletions (or changes) to any resource, including a storage account.
To keep track of every change to your blobs and blob metadata, using the change feed feature. It stores an Apache Avro formatted ordered, guaranteed, durable, immutable and read-only changelog.
If you have Soft delete, Change feed and Blob versioning enabled you can use point-in-time restore for block blobs, which is useful for in accidental deletion, corruption or data testing scenarios.
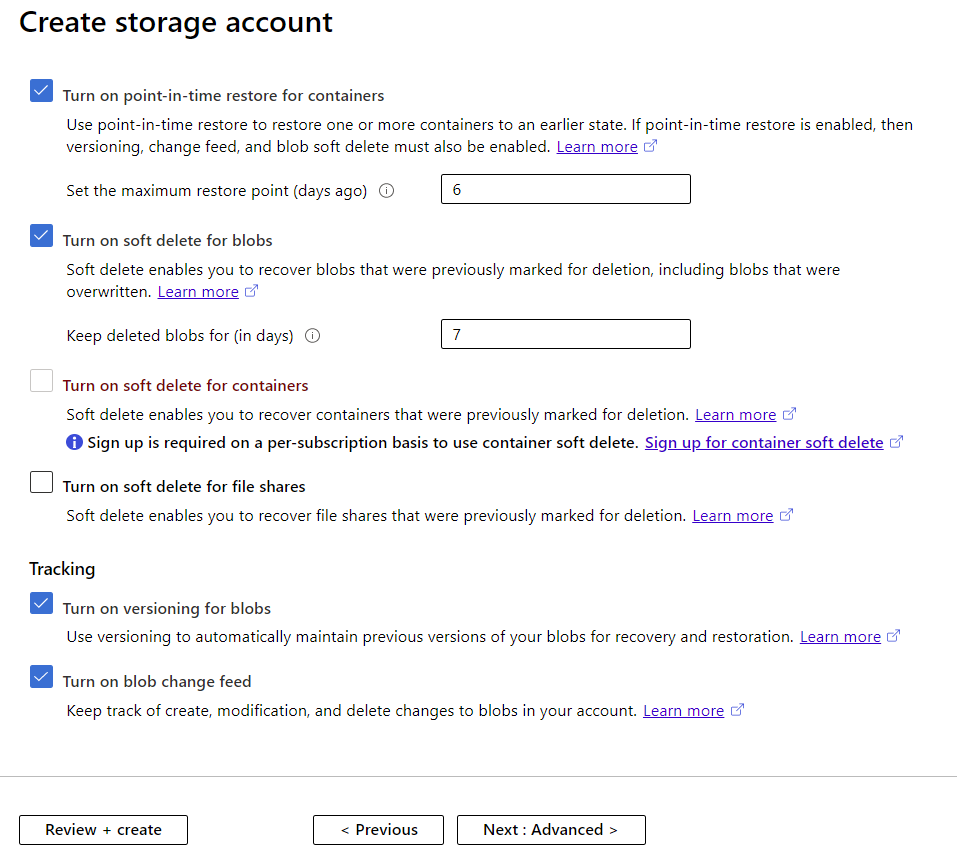
Creating a Storage Account Data Protection Options
Also for block blobs only is the Object replication feature. This lets you asynchronously copy block blobs from one storage account to another. This could be for a geo-distributed application that needs low latency access to a local copy of the blobs, or data processing where you distribute just the results of the process to several regions. It requires that Change feed and Blob versioning are enabled. The difference between this and GRS / GZRS is that this is granular as you create rules to define exactly which blobs are replicated, whereas geo-replication always covers the entire storage account. If you’re using blob snapshots be aware that they’re not replicated to the destination account.
If you have any of the geo-replicated account options, you should investigate exactly what’s involved in a manual failover that you control and include it in your Disaster Recovery plan. If there’s a full region outage and Microsoft declares it as such, they’ll do the failover but there are many other situations that might warrant you failing over, which typically takes about an hour. Be aware that storage accounts with immutable storage (see below), premium block blobs, Azure File Sync, or ADLS Gen2 cannot be failed over.
All storage (after 20th October 2017) in Azure is encrypted, you can check if you have data that’s older if it’s encrypted or not. If you have data from different sources in the same account, you can use the new Encryption scope (preview) feature to create secure boundaries between data using customer-managed encryption keys.
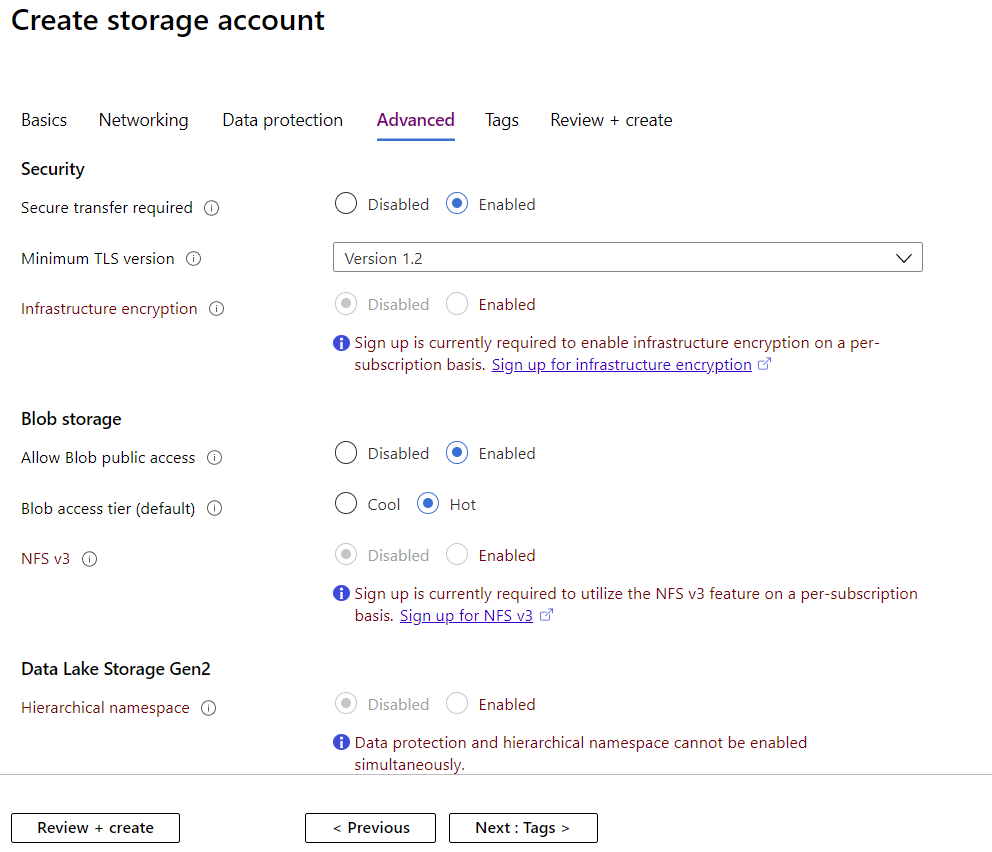
Creating a Storage Account Advanced Settings
If you have a regulatory need to provide Write Once, Read Many (WORM) or immutable storage you can create legal hold (until it’s lifted) or time based retention policies during which time no blobs can be deleted or changed, even if you have administrative privileges. It can be set at the container level and works across all access tiers (hot, cool, and archive).
It’s interesting to note that with all of these built-in data protection features for Disaster Recovery, including geographical replication, there’s no built-in backup solution for blob storage. Backup, as opposed to DR, comes into play when you have an application error for instance and data has been corrupted for some time and you need to “go back in time”. There are ways to work around this limitation.
Azure Blob Storage features
There are several other features that contribute to data protection and resiliency such as Network routing preference. Normally traffic to and from your clients on the internet are routed to the closest point of presence (POP) and then transfer on Microsoft’s global network to and from the storage account endpoint, maximizing network performance, at the cost of network traffic charges. Using this preview feature you can instead ensure that both inbound and outbound traffic is routed through the POP closest to the storage account (and not closest to the client), minimizing network transfer charges.
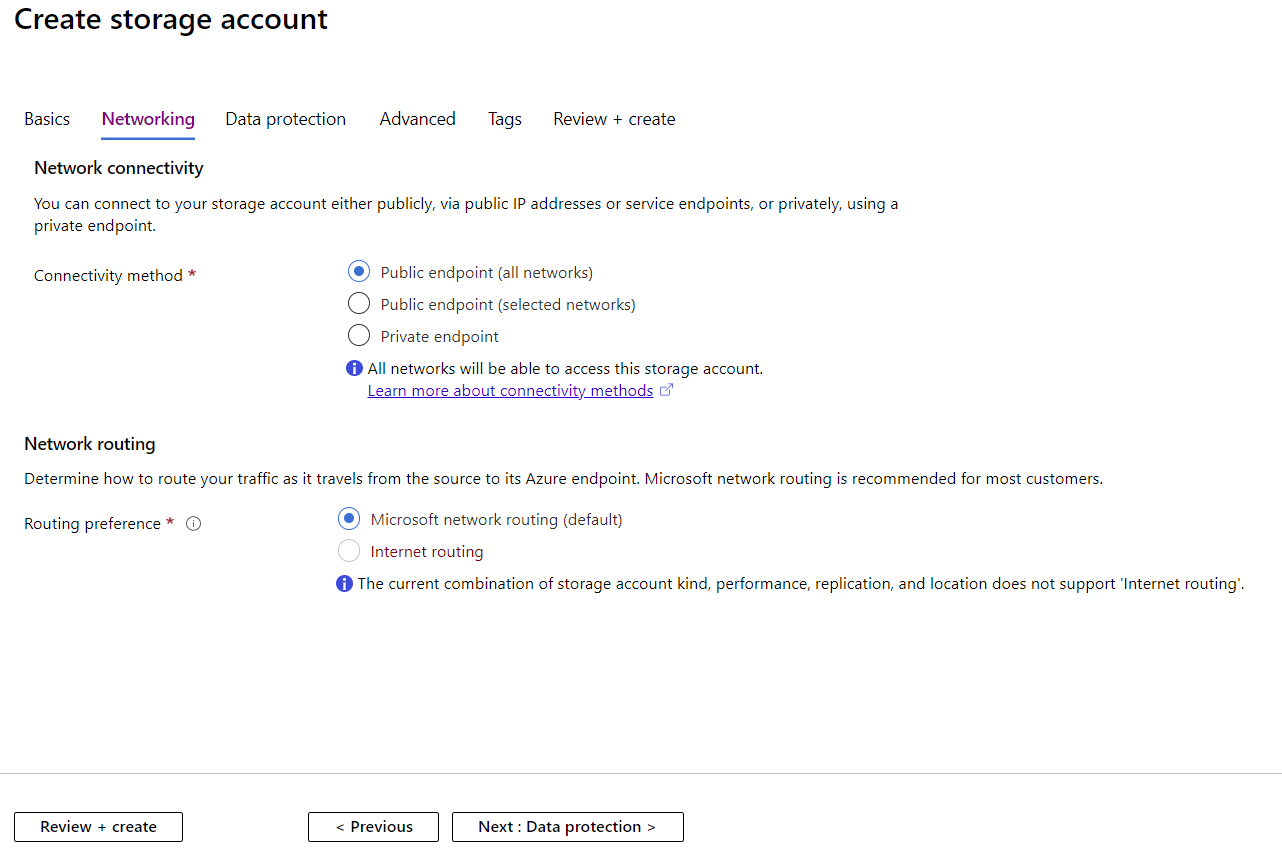
Creating a Storage Account Network Settings
If you have REALLY big files, blob storage now supports up to 190.7 TiB blobs.
To understand what data you have in your storage accounts use the new Blob inventory report preview feature to see total data size, age, encryption status, etc. Managing large amounts of blobs becomes easier with Blob index which lets you dynamically tag blobs using key-value pairs which you can then use when searching the data, or with lifecycle management to control the shifting of blobs between tiers.
Azure Data Lake Store Gen2
No conversation around Azure storage is complete without mentioning ADLS Gen2. Traditionally data lakes are optimized for big data analytics and unaware of features such as file system semantics / hierarchical namespaces and file level security. ADLS Gen2 builds on Azure Blob storage and provides these features, along with many others to provide a low cost, tier aware, highly resilient platform to build enterprise data lakes. There are some features available in Blob storage accounts that are not yet available for ADLS Gen2. To optimize your application to only retrieve exactly the required data use the new Query Acceleration feature for both Blob storage and ADLS Gen2.
Conclusion
Azure Blob storage provides a multitude of features to ensure the protection and recoverability of your data in one comprehensive platform. Good luck in designing optimized Azure Blob storage solutions for your business needs.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Paul Schnackenburg

