Save to My DOJO

Table of contents
- Disaster Recovery Time in a Nutshell
- Challenges Against Short RTOs and RPOs
- Outlining Organizational Desires
- Considering the Availability and Impact of Solutions
- Using Multiple RTOs and RPOs
- Leveraging Rotation and Retention Policies
- Recovery Time Actual (RTA) and Recovery Point Actual (RPA)
- Certifications and Regulatory Compliance in Highly Regulated Industries
- Coalescing into a Disaster Recovery Plan
You will focus much of your disaster recovery planning (and rightly so) on the data that you need to capture. The best way to find out if your current strategy does this properly is to try our acid test. However, backup coverage only accounts for part of a proper overall plan. Your larger design must include a thorough model of recovery goals, specifically Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Ideally, a restore process would contain absolutely everything. Practically, expect that to never happen. This article explains the risks and options of when and how quickly operations can and should resume following systems failure.
Table of Contents
Disaster Recovery Time in a Nutshell
What is Recovery Time Objective?
What is Recovery Point Objective?
Challenges Against Short RTOs and RPOs
Outlining Organizational Desires
Considering the Availability and Impact of Solutions
Short Interval Data Replication
Ransomware Considerations for Replication
Ransomware Considerations for Backup
Leveraging Rotation and Retention Policies
Coalescing into a Disaster Recovery Plan
Disaster Recovery Time in a Nutshell
If a catastrophe strikes that requires recovery from backup media, most people will first ask: “How long until we can get up and running?” That’s an important question, but not the only time-oriented problem that you face. Additionally, and perhaps more importantly, you must ask: “How much already-completed operational time can we afford to lose?” The business-continuity industry represents the answers to those questions in the acronyms RTO and RPO, respectively.
What is Recovery Time Objective?
Your Recovery Time Objective (RTO) sets the expectation for the answer to, “How long until we can get going again?” Just break the words out into a longer sentence: “It is the objective for the amount of time between the data loss event and recovery.”

Of course, we would like to make all of our recovery times instant. But, we also know that will not happen. So, you need to decide in advance how much downtime you can tolerate, and strategize accordingly. Do not wait until the midst of a calamity to declare, “We need to get online NOW!” By that point, it will be too late. Your organization needs to build up those objectives in advance. Budgets and capabilities will define the boundaries of your plan. Before we investigate that further, let’s consider the other time-based recovery metric.
What is Recovery Point Objective?
We don’t just want to minimize the time that we lose; we also want to minimize the amount of data that we lose. Often, we frame that in terms of retention policies — how far back in time we need to be able to access. However, failures usually cause a loss of systems during run time. Unless all of your systems continually duplicate data as it enters the system, you will lose something. Because backups generally operate on a timer of some sort, you can often describe that potential loss in a time unit, just as you can with recovery times. We refer to the maximum total acceptable amount of lost time as a Recovery Point Objective (RPO).

As with RTOs, shorter RPOs are better. The shorter the amount of time since a recovery point, the less overall data lost. Unfortunately, reduced RPOs take a heavier toll on resources. You will need to balance what you can achieve against what your business units want. Allow plenty of time for discussions on this subject.
Challenges Against Short RTOs and RPOs
First, you need to understand what will prevent you from achieving instant RTOs and RPOs. More importantly, you need to ensure that the critical stakeholders in your organization understand it. These objectives mean setting reasonable expectations for your managers and users at least as much as they mean setting goals for your IT staff.
RTO Challenges
We can define a handful of generic obstacles to quick recovery times:
- Time to acquire, configure, and deploy replacement hardware
- Effort and time to move into new buildings
- Need to retrieve or connect to backup media and sources
- Personnel effort
- Vendor engagement
You may also face some barriers specific to your organization, such as:
- Prerequisite procedures
- Involvement of key personnel
- Regulatory reporting
Make sure to clearly document all known conditions that add time to recovery efforts. They can help you to establish a recovery checklist. When someone requests a progress report during an outage, you can indicate the current point in the documentation. That will save time and reduce frustration.
RPO Challenges
We could create a similar list for RPO challenges as we did for RTO challenges. Instead, we will use one sentence to summarize them all: “The backup frequency establishes the minimum RPO”. In order to take more frequent backups, you need a fast backup system with adequate amounts of storage. So, your ability to bring resources to bear on the problem directly affects RPO length. You have a variety of solutions to choose from that can help.
Outlining Organizational Desires
Before expending much effort figuring out what you can do, find out what you must do. Unless you happen to run everything, you will need input from others. Start broadly with the same type of questions that we asked above: “How long can you tolerate downtime during recovery?” and “How far back from a catastrophic event can you re-enter data?” Explain RTOs and RPOs. Ensure that everyone understands that RPO means recent a loss of recent data, not long-term historical data.
These discussions may require a fair bit of time and multiple meetings. Suggest that managers work with their staff on what-if scenarios. They can even simulate operations without access to systems. For your part, you might need to discover the costs associated with solutions that can meet different RPO and RTO levels. You do not need to provide exact figures, but you should be ready and able to answer ballpark questions. You should also know the options available at different spend levels.
Considering the Availability and Impact of Solutions
To some degree, the amount that you spend controls the length of your RTOs and RPOs. That has limits; not all vendors provide the same value per dollar spent. But, some institutions set out to spend as close to nothing as possible on backup. While most backup software vendors do offer a free level of their product, none of them make their best features available at no charge. Organizations that try to spend nothing on their backup software will have high RTOs and RPOs and may encounter unexpected barriers. Even if you find a free solution that does what you need, no one makes storage space and equipment available for free. You need to find a balance between cost and capability that your company can accept.
To help you understand your choices, we will consider different tiers of data protection.
Instant Data Replication
For the lowest RPO, only real-time replication will suffice. In real-time replication, every write to live storage is also written to backup storage. You can achieve this in many ways, but the most reliable involves dedicated hardware. You will spend a lot, but you can reduce your RPO effectively to zero. Even a real-time replication system can drop active transactions, so never expect a complete shield against data loss.
Real-time replication systems have a very high associated cost. For the most reliable protection, they will need to span geography as well. If you just replicate to another room down the hall and a fire destroys the entire building, your replication system will not save you. So, you will need multiple locations, very high speed interconnects, and capable storage systems.
Short Interval Data Replication
If you can sustain a few minutes of lost information, then you usually find much lower price tags for short-interval replication technology. Unlike real-time replication, software can handle the load of delayed replication, so you will find more solutions. As an example, Altaro VM Backup offers Continuous Data Protection (CDP), which cuts your RPO to as low as five minutes.
As with instant replication, you want your short-interval replication to span geographic locations if possible. But, you might not need to spend as much on networking, as the delays in transmission give transfers more time to complete.
Ransomware Considerations for Replication
You always need to worry about data corruption in replication. Ransomware adds a new twist but presents the same basic problem. Something damages your real-time data. None-the-wiser, your replication system makes a faithful copy of that corrupted data. The corruption or ransomware has turned both your live data and your replicated data into useless jumbles of bits.
Anti-malware and safe computing practices present your strongest front-line protection against ransomware. However, you cannot rely on them alone. The upshot: you cannot rely on replication systems alone for backup. A secondary implication: even though replication provides very short RPOs, you cannot guarantee them.
Short Interval Backup
You can use most traditional backup software in short intervals. Sometimes, those intervals can be just, or nearly, as short as short-term replication intervals. The real difference between replication and backup is the number of possible copies of duplicated data. Replication usually provides only one copy of live data — perhaps two or three at the most — and no historical copies. Backup programs differ in how many unique simultaneous copies that they will make, but all will make multiple historical copies. Even better, historical copies can usually exist offline.
You do not need to set a goal of only a few minutes for short interval backups. To balance protection and costs, you might space them out in terms of hours. You can also leverage delta, incremental, and differential backups to reduce total space usage. Sometimes, your technologies have built-in solutions that can help. As an example, SQL administrators commonly use transaction log backups on a short rotation to make short backups to a local disk. They perform a full backup each night that their regular backup system captures. If a failure occurs during the day that does not wipe out storage, they can restore the previous night’s full backup and replay the available transaction log backups.
Long Interval Backup
At the “lowest” tier, we find the oldest solution: the reliable nightly backup. This usually costs the least in terms of software licenses and hardware. Perhaps counter-intuitively, it also provides the most resilient solution. With longer intervals, you also get longer term storage choices. You get three major benefits from these backups: historical data preservation, protection against data corruption, and offline storage. We will explore each in the upcoming sections.
Ransomware Considerations for Backup
Because we use a backup to create distinct copies, it has some built-in protection against data corruption, including ransomware. As long as the ransomware has no access to a backup copy, it cannot corrupt that copy. First and foremost, that means that you need to maintain offline backups. Replication requires essentially constant continuity to its replicas, so only backup can work under this restriction. Second, it means that you need to exercise caution around restores when you execute restore procedures. Some ransomware authors have made their malware aware of several common backup applications, and they will hijack it to corrupt backups whenever possible. You can only protect your offline data copies by attaching them to known-safe systems.
Using Multiple RTOs and RPOs
You will need to structure your systems into multiple RTO and RPO categories. Some outages will not require much time to recover from. Some will require different solutions. For instance, even though we tend to think primarily in terms of data during disaster recovery planning, you must consider equipment as well. For instance, if your sales division prints its own monthly flyers and you lose a printer, then you need to establish, RTOs, RPOs, downtime procedures, and recovery processes just for those print devices.
You also need to establish multiple levels for your data, especially when you have multiple protection systems. For example, if you have both replication and backup technologies in operation, then you will set one RPO/RTO value for times when the replication works, and RTO/RPO values for when you must resort to long-term backup. That could happen due to ransomware or some other data corruption event, but it can also happen if someone accidentally deletes something important.
To start this planning, establish “Best Case” and “Worst Case” plans and processes for your individual systems.
Leveraging Rotation and Retention Policies
For your final exercise in time-based disaster recovery designs, we will look at rotation and retention policies. “Rotation” comes from the days of tape backups, when we would decide how often to overwrite old copies of data. Now that high-capacity external disks have reached a low-cost point, many businesses have moved away from tape. You may not overwrite media anymore, or at least not at the same frequency. Retention policies dictate how long you must retain at least one copy of a given piece of information. These two policies directly relate to each other.
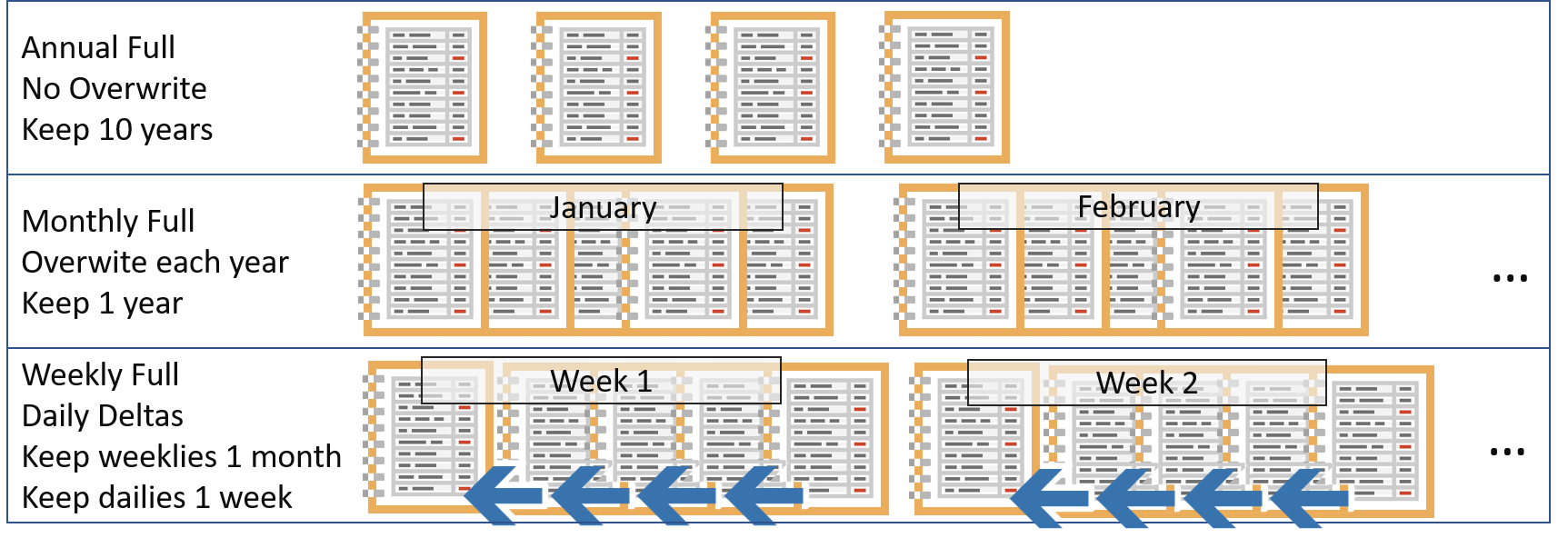
In today’s terms, think of “rotation” more in terms of unique copies of data. Backup systems have used “differential” and “incremental” backups for a very long time. The former is a complete record of changes since the last full backup; the latter is a record of changes since the last backup of any kind. Newer backup copies have “delta” and deduplication capabilities. A “delta” backup operates like a differential or incremental backup, but within files or blocks. Deduplication keeps only one copy of a block of bits, regardless of how many times it appears within an entire backup set. These technologies reduce backup time and storage space needs… at a cost.
Minimizing Rotation Risks
These speed-enhancing and space-reducing improvements have one major cost: they reduce the total number of available unique backup copies. As long as nothing goes wrong with your media, then this will never cause you a problem. However, if one of the full backups suffer damage, then that invalidates all dependent partial backups. You must balance the number of full backups that you take against the amount of time and bandwidth necessary to capture them.
As one minimizing strategy, target your full backup operations to occur during your organization’s quietest periods. If you do not operate 24 hours per day, that might allow for nightly full backups. If you have low volume weekends, you might take full backups on Saturdays or Sundays. You can intersperse full backups on holidays.
Recovery Time Actual (RTA) and Recovery Point Actual (RPA)
You may encounter a pair of uncommon terms: recovery time actual (RTA) and recovery point actual (RPA). These refer to measurements taken during testing or live recovery operations. They have some value, but beware falling into a needless circular trap.
Recovery time actual matches up with recovery time objective. Your RTO establishes the acceptable amount of time to lose due to a problem. RTA measures how long it took to return to operation after a failure (whether real or for testing purposes). Similarly, recovery point actual measures how well the restoration process aligned with your RPO.
While RTA and RPA metrics provide some value, they should not feature prominently in your plan. During testing, they can help determine if you have set reasonable objectives or if you need to alter your plan. They have much less applicability after a true failure, though. You can include them in typical “post-mortem” and “lessons learned” write-ups. Beyond that, you won’t find much use.
I read one article on RTA that compares RTO to an outage with your Internet provider. The author points out that we care less about how long the provider expects an outage to last and a lot more about how long it actually lasts. While true, this analogy has no accurate comparison to a valid RTO. We will always have a desire for zero downtime and, failing that, a desire for zero recovery time. An RTO should not set the expected downtime, but the acceptable downtime. In the private consumer Internet space, we mostly suffer at the mercy of the company’s ability. When establishing RTOs for our own enterprise, we can control purchases and processes that affect the viability of short RTOs. When recovering from a failure, the nature of the problem will always impact RTA, meaning that today’s RTA may have absolutely no bearing on the next RTA.
Few other authors go into any depth on RTA or RPA. RPA has even less to talk about than RTA. Either you achieved your RPO or you did not. If you got lucky, then maybe you did not lose all the data changes between the latest backup and the failure. Maybe you can glean something valuable from the experience, but the RPA itself doesn’t mean much of anything.
When performing a recovery, whether test or real, document what you can. You will need some numbers to report afterward. Mostly, you want to measure how well you achieved your objectives and note anything that you can change in your plan for the better.
Certifications and Regulatory Compliance in Highly Regulated Industries
Most organizations can follow an internally guided process for documenting and performing their backup and disaster recovery processes. Some must meet higher external standards.
First, work with industry-focused legal counsel. Finance, healthcare, insurance, and other highly regulated businesses may need to meet certain regulatory compliance requirements. Regional rules, such as GDRP, will impact all businesses within jurisdiction regardless of size or function.
Second, consider following outside certified practice guides. These can help to ensure that you meet all legal expectations, even those that you might not know about. Two highly regarded institutions provide publications: the International Organization for Standardization’s ISO/IEC 27031, “Guidelines for information and communication technology readiness for business continuity” and the National Institute of Science and Technology’s Special Publication 800-34, “Contingency Planning Guide for Federal Information Systems”.
Coalescing into a Disaster Recovery Plan
As you design your disaster recovery plan, review the sections in this article as necessary. Remember that all operations require time, equipment, and personnel. Faster backup and restore operations always require a trade-off of expense and/or resilience. Modest lengthening of allowable RTOs and RPOs can result in major cost and effort savings. Make certain that the key members of your organization understand how all of these numbers will impact them and their operations during an outage.
If you need some help defining RTO and RPO in your organization, let me know in the comments section below and I will help you out!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron

