Save to My DOJO

If there’s one thing that’s a lot easier to achieve in the cloud than on-premises, it’s High Availability (HA). This might sound strange given that when you move to public cloud, you give up a lot of control over your infrastructure but as we’ll show in this article – Azure Availability Sets and Azure Availability Zones are part of a plethora of technologies you can use to ensure your applications stay up.
High Availability on Premises
There are some fundamental concepts that contribute to HA in computer systems. At the server level on-premises we have redundancy built-in (dual or triple power supplies in each server, RAID for disk storage, multiple NICs connected to separate switches). Networks can be built to be redundant with multiple paths, switches and routers, eliminating single points of failure. Once we bring virtualization into the picture, clustering multiple physical servers together becomes feasible, automatically restarting VMs on other hosts if a physical server fails. And if you have particularly business-critical applications, we look to stretched clusters where nodes in a cluster are separated by some kilometres of distance. As you can appreciate, cost and complexity increase as you implement more of these technologies, with the most critical applications reserved for the really expensive solutions. Also notice that we go from guarding against a single component in a server failing, to a whole server or network, to a whole site.
That’s HA, keeping an application available for users through eliminating single points of failure and storing data in a redundant fashion, which is separate to Disaster Recovery (DR) preparedness.
DR applies similar concepts, generally by replicating data from one location to another to make it possible to restore services should a whole site fail. The main difference between HA and DR is that the latter isn’t instantaneous, and some downtime is expected. It’s tempting to get caught up in technical solutions to HA and DR as you imagine scenarios of hurricanes and floods taking out your servers but as much as this is a technical issue, it’s a people and process problem. Nearly all outages are caused by people making mistakes or processes not being thought through, not by unexpected natural disasters.
If you outsource any part of the system described above, your provider generally offers a Service Level Agreement (SLA) where they will reduce your cost if they don’t provide the agreed uptime, described in availability, generally per month, for example, 99.9% uptime equates to 43.2 minutes of downtime in a month.
The good news is that an understanding of these concepts (which most IT Pros know off by heart) transfer very well to public cloud.
High Availability in Azure
The main difference between running your workloads on-premises and Azure when planning for HA is that you don’t have access to the underlying infrastructure which means less work as well as less control. We’ll start by looking at IaaS VMs, where a single VM running on Standard HDD Managed Disk has an SLA of 95%, Standard SSD Managed Disk gives you 99.5% and a VM running on Premium / Ultra SSD gives you 99.9%. These SLAs only apply if all disks (OS and data disks) are running on the required storage type.
So, if your business has a critical application that can only run in a single VM Azure can at most provide 99.9%. Obviously, this is downtime that Microsoft has responsibility for, if your application in the VM crashes or is attacked by malware or your network infrastructure or ISP has an outage those don’t count. If the SLA is breached, and you go through the work of proving to support that it was, you’ll get service credits, which is small comfort if your business application was down for hours or days.
Just as on-premises, a single VM really isn’t enough for a proper HA strategy. Hence you need to use Availability Sets, here’s a good primer. There are two new terms to cover here, Update Domains (UD) and Fault Domains (FD). The former means that if two VMs are spread across UDs, only one host will be restarted at a time when Microsoft updates their Hyper-V hosts. Be aware that Microsoft has put in a lot of work to limit the times that hosts actually need to be rebooted for updates, mostly they can apply updates to a running OS without a reboot. An FD is a rack which has separate power and networking connections and is the smallest fault isolation in Azure.
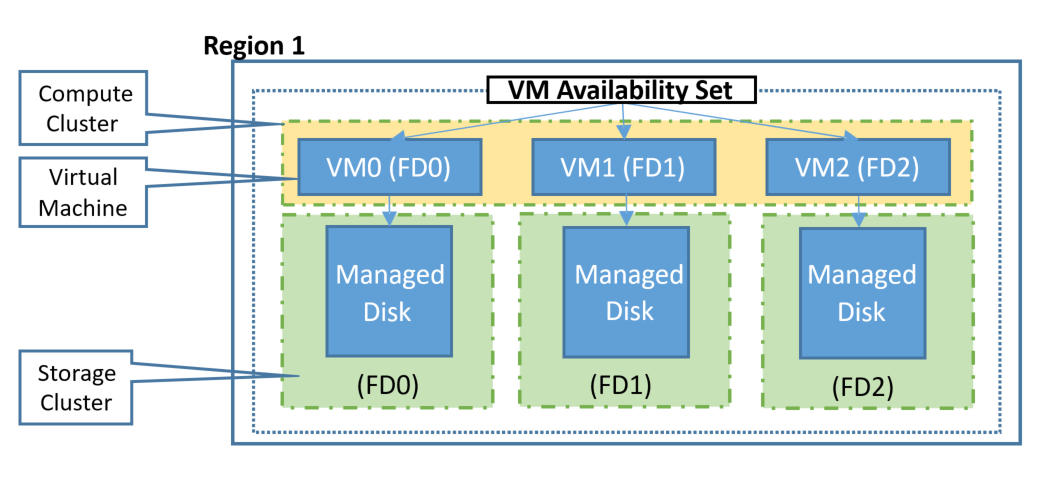
Fault and Update Domains in Azure (courtesy of Microsoft)
Take a canonical three-tier application with two web front end servers, two middle-tier application layer VMs and two backend database servers. When creating this in Azure you’d put each tier in an Azure Availability Set. This tells Azure to separate the two web VMs for instance in two distinct FDs, if a rack fails your second VM is still servicing clients as it’s running in a separate rack. Also, note that three copies of your managed disks for each VM are spread across storage infrastructure. When creating an Azure Availability Set the default number of FDs is 2 (max 3, depending on region) and UDs is 5 (max 20). VMs are spread across each FD and UD so that if you have seven VMs in an Azure Availability Set and five UDs, two of the UDs will have two VMs in it and one FD will have three VMs and the other one four. You cannot pick which VM goes in which UD or FD.
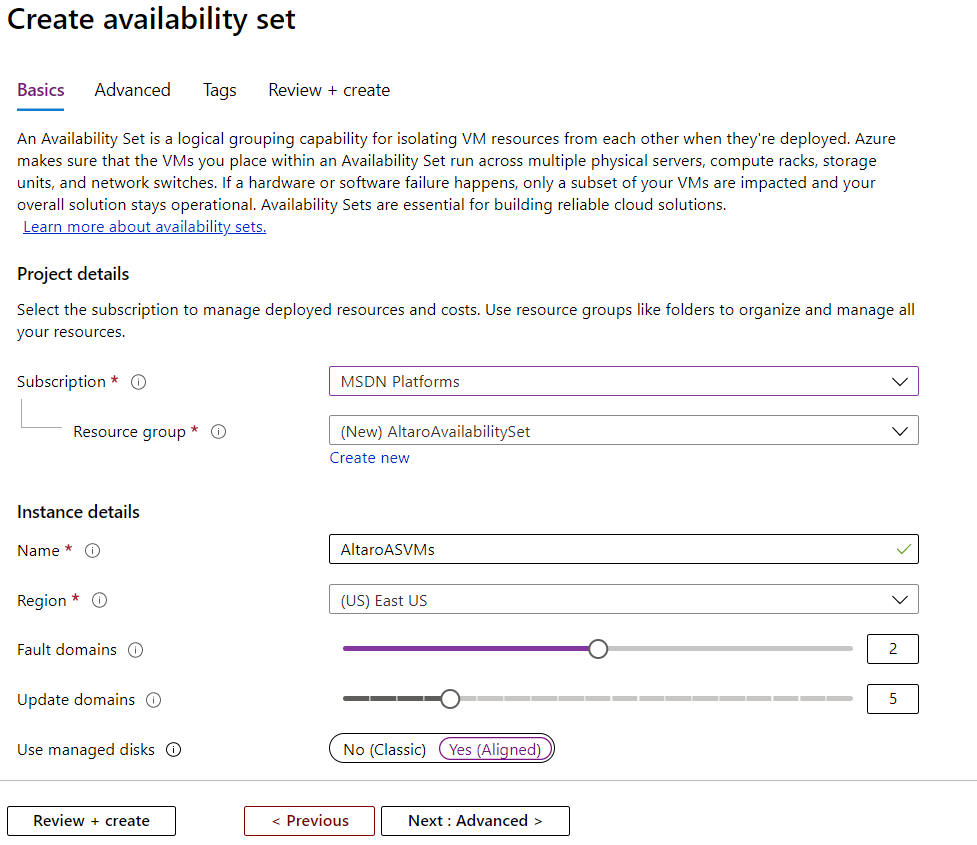
Creating an Azure Availability Set
Once you have your application deployed in one or more Azure Availability Sets, you get an SLA of 99.95% (21.6 minutes downtime). If your business has strict regulatory requirements and has opted for an Azure Dedicated Host they provide the same SLA as an Azure Availability Set.
Note that the concept of an Azure Availability Set lets Azure know that these VMs are “related” and needs to be kept separate, it’s up to you to make sure that the applications running in the VMs are using guest clustering appropriately. For instance, if you have two VMs running as Active Directory Domain Controllers (DCs) in the same domain they’ll automatically replicate and if one of them is on an FD that fails, the other DC will still be available for other VMs to authenticate against. If you have a SQL Server backend, you’ll need to set up database clustering in a guest cluster so that your application continues to be able to access data, even if one SQL VM is unavailable.
The opposite (sort of) to Azure Availability Sets is Proximity placement groups where you have a need to keep VMs very close to each other to support latency-sensitive applications.
Azure Availability Zones
In the ongoing “battle of worlds” between Azure and AWS, Microsoft proudly proclaims that they have more regions than AWS and GCP combined, whereas AWS claims more zones per region.
Currently, there are over 60 regions in Azure, spread across 140+ countries. Each region is one or more datacenters, and in each geography (apart from Brazil) there are two regions that are paired so that you can replicate data from one region to another whilst still complying with your country’s data residency laws. Each region is separated by at least 300 miles (typically) to reduce the likelihood that a natural disaster in one region affects the other region.
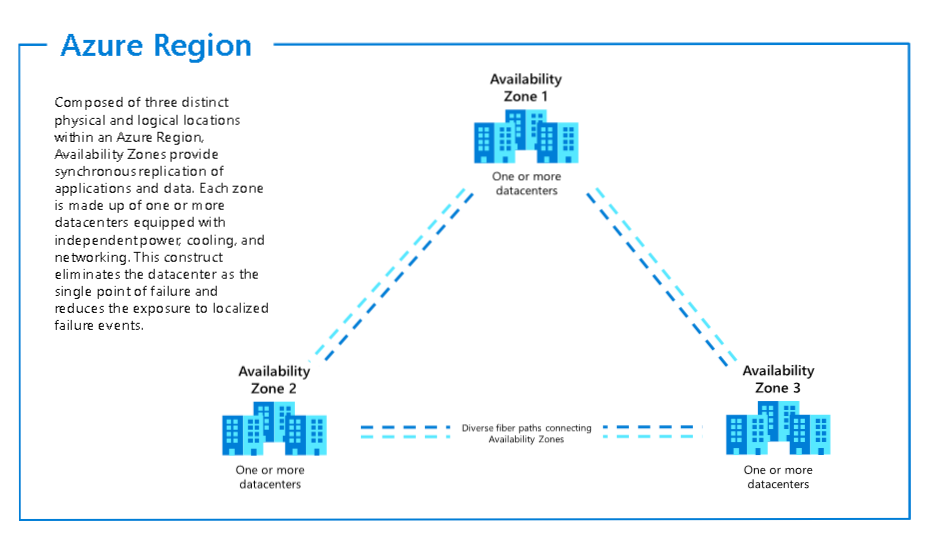
Azure Availability Zones and Regions
Within a region, there are multiple datacenters that have separate cooling, power and network infrastructure, providing isolation should an entire datacenter fail, these are known as Azure Availability Zones. For regions that provide Azure Availability Zones you can create VMs and distribute them across Azure Availability Zones which gives you a 99.99% SLA (4.3 minutes downtime per month).
At the time of writing 12 regions support Azure Availability Zones with four more coming soon.
Here I’m creating a VM in Australia East and picking zone 2 to house it.
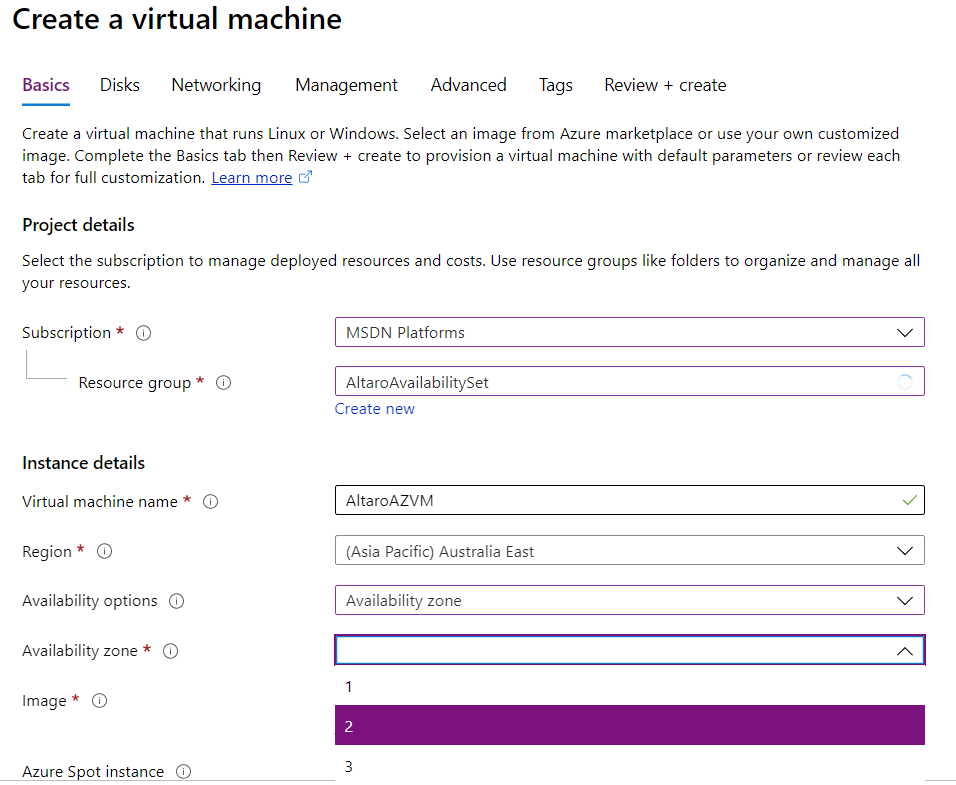
Creating a virtual machine
If you need several VMs that can be created from a single image that has your application already installed spread automatically across zones use a VM Scale Set, that spans Azure Availability Zones.
You cannot create an Azure Availability Set that spans Azure Availability Zones. For Azure Availability Zones there are some services that are Zonal, meaning each instance is “pinned” to a specific Azure Availability Zone (VMs, public IP addresses or managed disks) or Zone-redundant where Azure takes care of spreading them across zones. An example is Zone Redundant Storage (ZRS) which automatically spreads copies of your data across three zones, giving you 99.9999999999% (12 9’s) SLA for the stored data. There are also non-regional services in Azure that do not have a dependency on a particular region, making them resilient to both zone and region-wide outages. These tables list Zonal and Zone-redundant service for each region.
When it comes to DR you can use Azure Site Replication (ASR) to replicate disk writes on VM disks in one region to disks in another region. This is asynchronous replication so the copy might be slightly out of date, here’s a table showing the latency between different Azure regions but you’ll get up to date data on latency from your location to each region on this site.
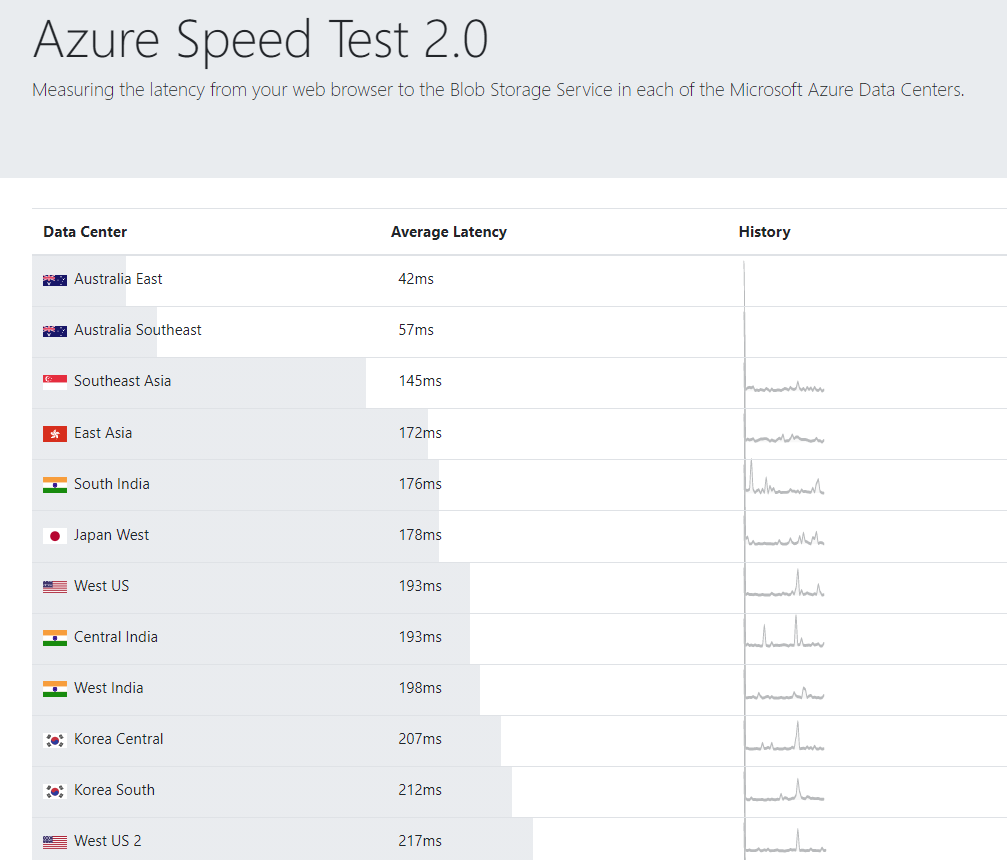
Azure Speed Test network latency results
You can also use ASR to replicate VMs from one Availability Zone to another. This has the distinct disadvantage that a natural disaster affecting several datacenters might take out all your zones but there are also benefits. Networking is much simpler as you can reuse the same virtual network, subnet, Network Security Groups (NSGs), private and public IP addresses and load balancer across zones. Latency will also be less but be aware that this feature is only available in five regions at the time of writing.
So far, we’ve been looking at IaaS VMs but ultimately, you’ll get the best cloud computing has to offer with PaaS services. Services such as Service Fabric, Data Lake, Firewall, Load Balancer, VPN Gateway, Cosmos DB, Event Hubs and Event Grid, Azure Kubernetes Services, and Azure Active Directory Domain Services all support zones today, giving you good building blocks for your HA architecture.
As you can see Azure offers many different options for building resilient applications and compared to managing multiple on-premises clusters or datacenters with redundant LAN and WAN infrastructure using what’s provided in the cloud is both easier and far more cost-effective.
Bringing Azure Availability Sets and Availability Zones together
Let’s make this real with an example application. A customer-facing, business-critical application needs to be moved to Azure and here’s an example architectural solution.
I’d pick a region to host the application, based on the lowest latency to the highest number of end-users, if this was a global application that needs to be distributed worldwide, we’d need to involve Azure Front Door and perhaps Cosmos DB but, in this scenario, let’s assume we’re looking at a single region.
If we need VMs for the front end we’d host multiple ones across each Availability Zone in a region and then use Azure Load Balancer to spread incoming traffic across each VM. As an alternative we might look to Azure App Environment (ASE, a PaaS version of web hosting) which lets us pin an ASE to a zone, we’d need at least two ASEs. Be aware that the Load Balancer as a PaaS is highly available as it’s zone aware, whilst also ensuring that the application VMs / resources are highly available.
For the application logic layer, we’d put one VM in each zone and use an Internal Load Balancer to manage the traffic coming from the web front end to this layer. Depending on the database layer used for the application today we may need to have multiple backend VMs with SQL server (again, spread across zones) in a guest cluster. Alternatively, if possible, switching to zone aware Azure SQL or Cosmos DB as PaaS database services would minimize infrastructure management.
This application is now resilient to host, networking hardware and storage failures, as well as an entire datacenter failing. To ensure timely recovery in the case of an entire region outage (DR), we’d use ASR to replicate the VMs to the paired region, and SQL or Cosmos DB to replicate the data to that region as well. In ASR we’d create (and test regularly) a Recovery Plan with all required steps to bring the application up quickly.
Conclusion
Most HA concepts that we’ve been using in IT for decades translate very well to public cloud, creating resilient applications doesn’t require relearning from scratch, rather just tweaking your thinking. Azure Availability Sets and Availability Zones give you great building blocks to lay a great foundation for your mission-critical applications.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Paul Schnackenburg

