Save to My DOJO

Azure archive storage is cloud-based storage. That sounds like a simple statement, however, consider cloud-based storage like a set of hard drives at the end of a wire. Since there’s some distance involved between you and that hard drive, there are things that you cannot achieve like direct block-based access, however, there are unlockable storage capabilities that are far beyond what we’re able to achieve by ourselves. One of those capabilities is to present itself as Archive Storage as part of a scalable object store. In this post, we will explore what Azure Archive Storage is and to do that we will take a detour through the basics and then head on towards how to start using it.
Before we dive into the depths of archive storage and what we can do with it, we will start with the very basics.

We cannot provision Azure Archive Storage without requiring an Azure Storage account. When we create one of these we are able to configure several parameters, one of which is what type of account we need.
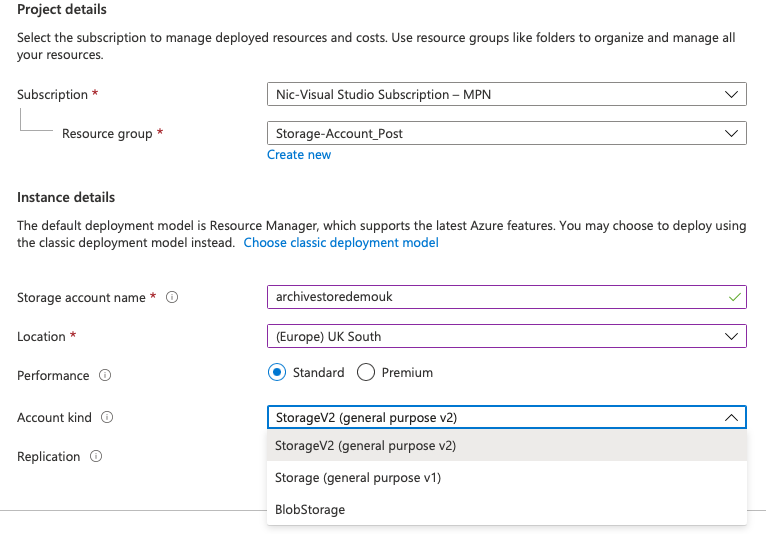
Unless we need to be restrictive about what we are doing we would use a General-purpose V2 storage account type, which supports 6 different services including Blob, File, Queue, Table, Disk, and Data Lake Gen2. For the sake of storage tiering, we require both blob storage as well as a general-purpose V2 account.
How many Azure Archive Storage copies are enough?
As we think through our storage requirements, we need to consider how many copies of our data we need, where those copies are, as well as what kind of availability Service Level Agreement (SLA) is associated with the various choices.
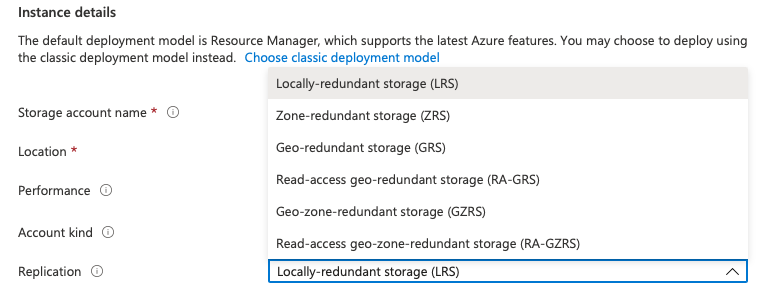
I’ll summarize these for us below:
Locally-redundant storage (LRS) contains 3 copies of your data within a single physical location or datacenter, with a durability of 11 nines, that is 99.999999999%. Choose this option if you don’t require any special storage recoverability outside of the chosen Azure region
Zone-redundant storage (ZRS), contains the 3 copies across the Azure availability zones in the chosen region. Availability zones are physically separate locations which don’t share power, cooling or networking, with a durability of 12 nines, that is 99.9999999999%. Choose this option:
- to safeguard against a single Azure datacenter or physical location failure that could be caused by a fire, flood or natural disaster
- create redundancy within the geography or chosen country
Geo-Redundant Storage (GRS) contains 3 copies of your data within a single physical location or datacenter, as well as another copy to another location which is hundreds of miles away using LRS. That means 6 copies over two distinct geographies with a durability of 16 nines, that is 99.99999999999999%.
Geo-zone-redundant storage (GZRS) copies your data across three Azure availability zones in the chosen region and replicates it to a second geography. The durability of GRS and GZRS is the same; 16 nines. Choose this option as your belts and braces storage option should you be concerned that your country could fail or disappear and you still need a copy of your data.
Choosing your Tier of Storage
If you’re testing and you’re not massively concerned about the availability of your data then LRS will do. As the criticality of your data or your requirement to recover from data increases, consider moving from LRS to GRS. As of the time of writing ZRS, GZRS or RA-GZRS (that is globally zone redundant with an additional read-only copy) is not supported for Azure storage archive tiers.
NOTE: some fine print applies here in terms of when your data is available after it has been written and replicated. The following has been extracted from the SLA for Storage Accounts which may shape your decision-making process based on the definition of the terminology and replication times:

SLA definitions are an important part of our storage planning, as well as understanding which options are available.
As you create the storage account you have the option to define a default Blob access tier, as either Hot or Cool, but not Archive. Archive Storage tiering for specific items is set after the creation of the storage account, but more on that later.
Putting your Data on ice
For the sake of this article, I have created a storage account, in which I have created a blob container and uploaded a small text document. I can change the storage tiering for this document within the Storage Explorer GUI by right-clicking on the file and choosing the Change Access Tier option.
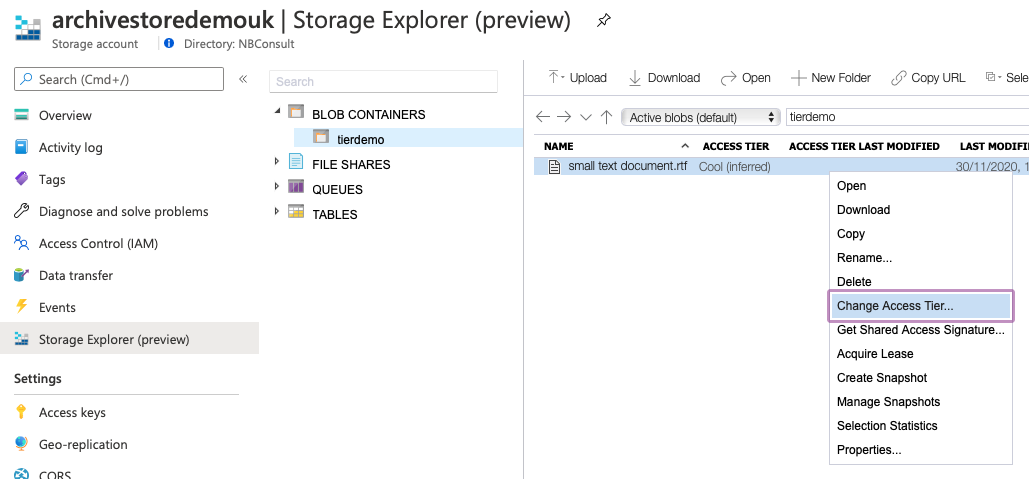
Note the option to change from Hot to Cool, but not to Archive
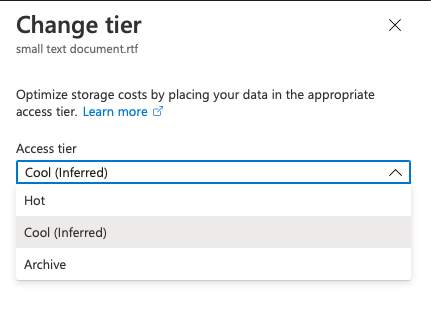
Changing the storage tier presents us with a warning that our blog will be inaccessible until we rehydrate it to another storage tier, i.e. Cool or Hot
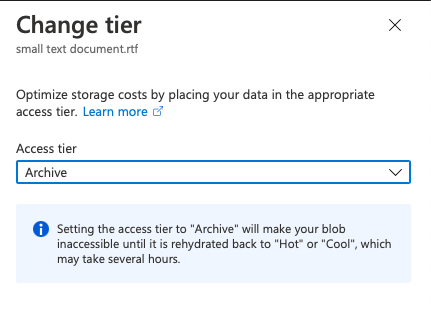
The Access Tier status reflects in the GUI immediately
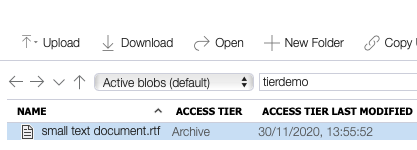
Once the tier is changed, we cannot interact with the file any longer. Attempting to download the file in Storage Explorer leads to the following error message.
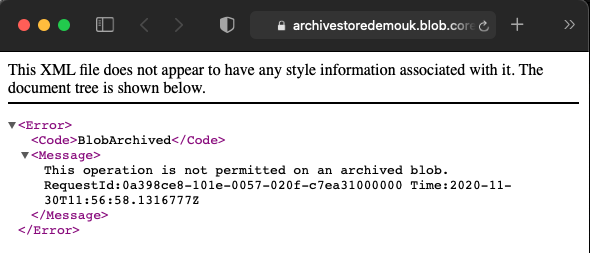
Trying to Change the tier after we have commenced the rehydration operation also results in an error:
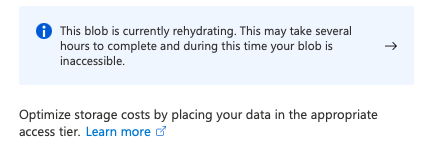
To restore access to the file, we need to Rehydrate this blog from Archive to either Hot or Cool. This operation is not quick and is something you need to plan for as the rehydrate operation can take up to 15 hours to complete.
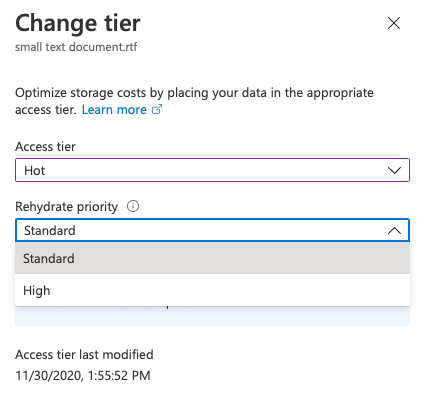
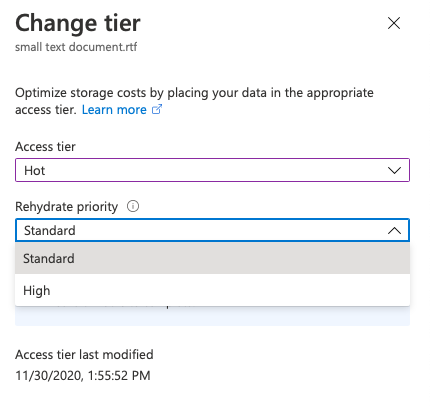
Note that we can set the Rehydrate priority for the file as well, however, the change in priority will attract significant costs. For smaller blob objects, a high priority rehydrate is able to bring the object back in under an hour.
Automating Storage Tiering
While using the GUI for a few files or a few operations is fine, it certainly doesn’t scale to hundreds, thousands, or millions of files. We can automate blog tiering using programmatic methods via API calls and/or PowerShell as well as using storage Lifecycle Management policies.
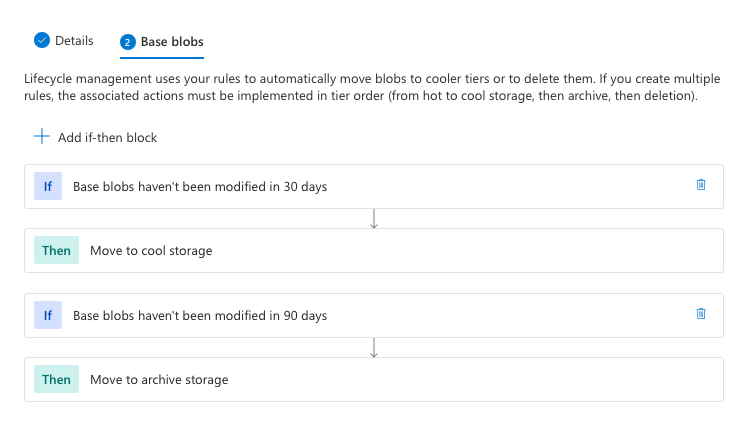
Understanding Tiering
Tiering is available in three options, Hot, Cool and Achieve. I will discuss what the minimum tier ageing is.
Hot tier- Use this tier for active data with the fastest possible response time within the SLA for standard or premium storage.
Cool tier – Use this tier for data that can be classified as cool for at least 30 days. Use this for data that isn’t accessed frequently, as well as part of a tiered backup strategy.
Archive tier – as the cheapest storage tier it is also the most restrictive to use. Data needs to remain in this tier for at least 180 days. While data is in this tier, it’s offline for active use unless you rehydrate it. Think of it as the equivalent of an offsite tape backup. Bear in mind that if you rehydrate early, you will attract a charge depending on the priority of the rehydration. Use this for data that you want to park or archive as the name suggests.
Earlier in this article, we discussed various account options including LRS and GRS storage account types. I have extracted the following table which compares the availability of tiers
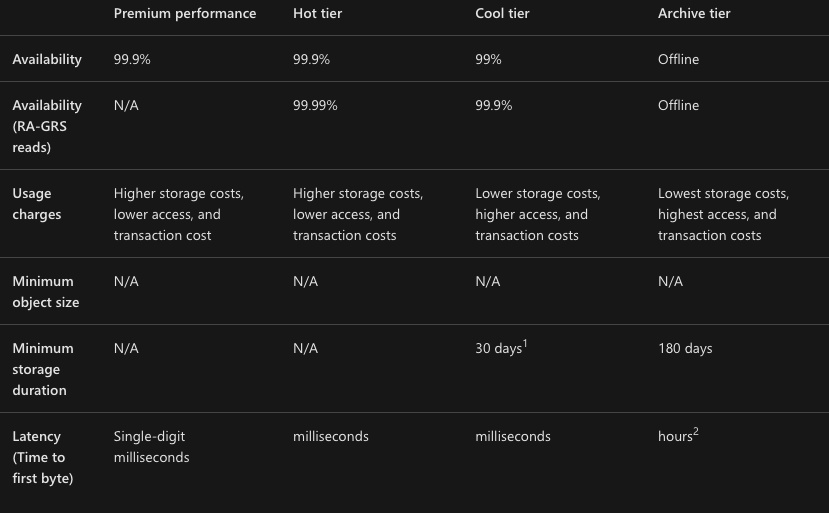
Azure Archive storage vs the rest
Azure Archive storage is relatively seamless and well-integrated as storage solution which may be consumed as part of a cloud=storage strategy or a cloud-integrated application strategy hosted completely on Azure services. While there are many other pure cloud-based storage solutions in the market like Wasabi, Backblaze B2, etc., I’m offering a brief comparison against two other global hyper-scale cloud solutions, which offer IAAS and PAAS services, including an archive equivalent class of storage.
Amazon Glacier – an S3 compliant object store which offers two storage classes, which offer a retrieval time measured from a few minutes for S3 Amazon Glacier to up to 48 hours in the case of the Amazon S3 Glacier Deep Archive storage class. Durability is offered at 11 nines or 99.999999999%.
Google Coldline – Durability is offered at 11 nines or 99.999999999%, however, latency for retrieval sets this service apart from its competitors at sub-second data retrieval, albeit at a comparatively low availability SLA of 99%
Estimating the cost of storage
Storage costs have several factors to consider. One is the pure costs of storage, the next is the cost of accessing the data once it’s stored in the cloud.
Let’s start with how to calculate the storage costs. For the sake of this article, I’m using the UK South as the region and USD as the currency. Below we can clearly see storage becoming cheaper as pricing moves from Premium class (SSD) to standard Hot, Cool and Archive tiers
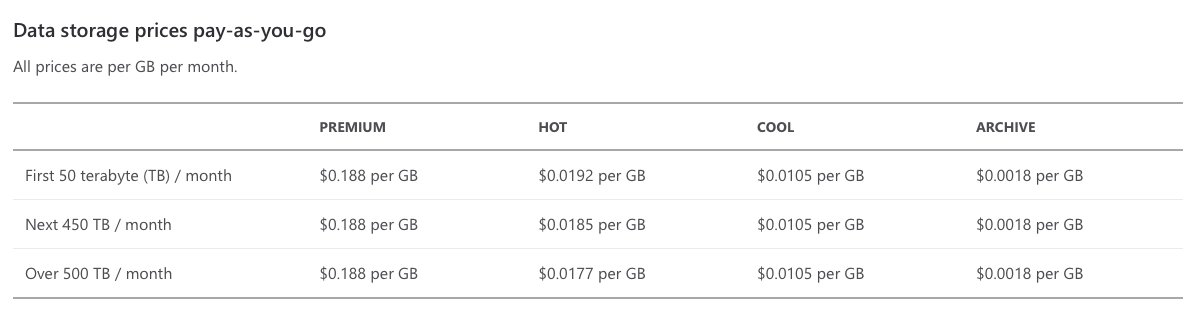
However, for cloud costing – storage costs are not the only concern. How the data is used and how often it’s accessed is the next factor. Pricing storage can be tricky if we don’t know the IOPS profile of a given application or use case, however, lifecycle management features within Azure help to smooth out the pricing of moving blobs to the Archive tier.
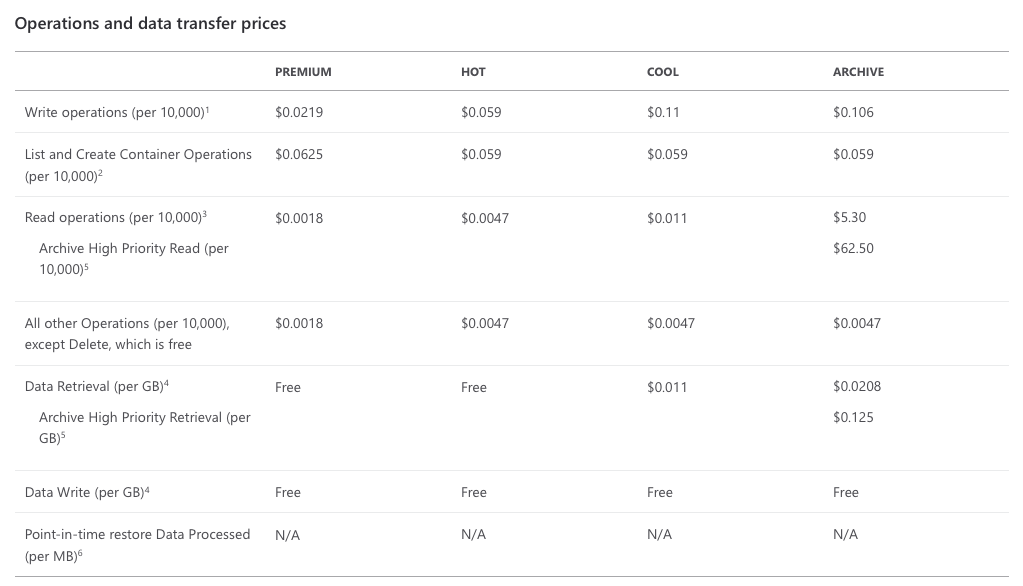
Speaking of backup
One of the natural use cases for this class of storage is backup. With that in mind, Microsoft has documented a rich partner ecosystem who are able to use Azure Archive Storage Directly.

Conclusion
Azure Archive storage is a capable, flexible, and affordable storage solution which performs within advertised SLA and data durability figures. Azure Archive storage is a natural extension to Azure Storage tiering, which includes hot, cold and archive tiers and does not require a separate storage GUI to configure. Data may be tiered using the Azure Resource Manager GUI, PowerShell, and automated lifecycle policies.
One of the primary use cases is long term backup retention and any kind of long terms storage and archiving requirement. Microsoft and its partners offer direct support for backup solutions able to write data directly to the Azure Archive storage tier.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category



More from this author


About the Author

Nicolas Blank

