Save to My DOJO
Table of contents
- 1. Document Everything
- 2. Automate
- 3. Monitor Everything
- 4. Use the Provided Auditing Tools
- 5. Avoid Geographically Dispersed Hyper-V Clusters
- 6. Strive for Node Homogeneity
- 7. Use Computer-Based Group Policies with Caution
- 8. Develop Patterns and Practices that Prevent Migration Failures
- 9. Use Multiple Shared Storage Locations
- 10. Use at Least Two Distinct Cluster Networks, Preferably More
- 11. Minimize the Number of Network Adapter Teams
- 12. Do Not Starve Virtual Machines to Benefit Live Migration or Anything Else
- 13. Only Configure QoS After You’ve Determined that You Need QoS
- 14. Always be Mindful of Licensing
- 15. Keep in Mind that Resources Exhaust Differently in a Cluster
- 16. Do Not Cluster Virtual Machines that Don’t Need It
- 17. Don’t Put Non-HA Machines on Cluster Shared Volumes
- 18. Minimize the Use of non-HA VMs in a Cluster
- 19. Ask Somebody
It’s not difficult to find all sorts of lists and discussions of best practices for Hyper-V. There’s the 42 best practices for Balanced Hyper-V systems article that I wrote. There is the TechNet blog article by Roger Osborne. Best practices lists are a bit tougher to find for failover clustering, but there are a few if you look. What I’m going to do in this article is focus in on the overlapping portion of the Hyper-V/failover clustering Venn diagram. Items that apply only to Hyper-V will be trimmed away and items that would not apply in a failover cluster of roles other than Hyper-V will not be included. What’s also not going to be included is a lot of how-to, otherwise this document would grow to an unmanageable length. I’ll provide links where I can.
As with any proper list of best practices, these are not rules. These are simply solid and tested practices that produce predictable, reproducible results that are known to result in lower cost and effort in deployment and/or maintenance. It’s OK to stray from them as long as you have a defensible reason.
1. Document Everything
Failover clustering is always a precarious configuration of a messy business. There are a lot of moving parts that are neither independent nor inter-dependent. Most things that go wrong will do so without world-stopping consequences up until the point where their cumulative effect is catastrophic. The ease of working with cluster resources masks a complex underpinning that could easily come apart. It is imperative that you keep a log of things that change for your own record and for anyone that will ever need to assist or replace you. Track:
- Virtual machine adds, removes, and changes
- Node adds, removes, and changes
- Storage adds, removes, and changes
- Updates to firmware and patches
- All non-standard settings, such as possible/preferred owner restrictions
- Errors, crashes, and other problems
- Performance trends
- Variations from expected performance trends
For human actions taken upon a cluster, what is very important is to track why something was done. Patches are obvious. Why was a firmware update applied? Why was a node added?
For cluster problems, keep track of them. Don’t simply look at a log full of warnings and say, “Oh, I understand them all” and then clear it. You’d be amazed at how useful these histories are. Even if they are benign, what happens if you get a new IT Manager who says, “You’ve known about these errors and you’ve just been deleting them?” Even if you have a good reason, the question is inherently designed to make you look like a fool whether or not that’s the questioner’s intent. You want to answer, “I am keeping a record and continuing to monitor the situation.” Furthermore, if those messages turn out to be not as benign as you thought, you have that record. You can authoritatively say, “This began on…”
2. Automate
Even in a small cluster, automation is vital. For starters, it clears up your time from tedious chores. All of those things that you know that you should be doing but aren’t doing become a whole lot less painful. Start with Cluster-Aware Updating. If you want to get a record of all of those warnings and errors that we were talking about in point #1, how does this suit you?:
Get-WinEvent -LogName "*failoverclustering*", "*hyper-v*" -FilterXPath '*[System[Level=2 or Level=3]]' | select LogName, LevelDisplayName, Id, Message | Export-Csv -Path "C:temp$($env:ComputerName)-$($(Get-Date).ToLongDateString())-ClusterLogs.csv" -NoTypeInformation
Be aware that the above script can take quite a while to process, especially if you have a lot of problems and/or haven’t cleared your logs in a while, but it is very thorough. Be aware that this should be run against every node. The various Hyper-V logs will be different on each system. While many of the failover clustering logs should be the same, there will be discrepancies. For no more difficult than this script is to run and for no more space than it will require to store, it’s better to just have them all.
One of the things that I got in the habit of doing is periodically changing the ownership of all Cluster Shared Volumes. While the problem may have since been fixed, I had issues under 2008 R2 with nodes silently losing connectivity to iSCSI targets that they didn’t have live virtual machines on, which later caused problems when an owning node rebooted or crashed and the remaining node could not take over. Having a background script occasionally shuffling ownership served the dual purpose of keeping CSV connectivity alive and allowing the cluster to log errors without bringing the CSV offline. The command is Move-ClusterSharedVolume.
Always be on the lookout for new things to automate. There’s a pretty good rule of thumb for that: if it’s not fun and you have to do it once, you can pretty much guarantee that you’ll have to do it again, so it’s better to figure out how to get the computer to do it for you.
3. Monitor Everything
If monitoring a Hyper-V host is important, monitoring a cluster of Hyper-V hosts is doubly so. Not only does a host need to be able to handle its own load, it also needs to be able to handle at least some of the load of at least one other node at any given moment. That means that you need to be keeping an eye on overall cluster resource utilization. In the event that a node fails, you certainly want to know about that immediately. By leveraging some of the advanced capabilities of Performance Monitor, you can, with what I find to be a significant amount of effort, have a cluster that monitors itself and can use e-mail to notify you of issues. If your cellular provider has an e-mail-to-text gateway or you have access to an SMS conversion provider, you can even get hosts to text or page you so that you get urgent notifications quickly. However, if your resources are important enough that you built a failover cluster to protect them, they’re also important enough for you to acquire a proper monitoring solution. This solution should involve at least one system that is not otherwise related to the cluster so that complete outages are also caught.
Even just taking a few minutes here and there to click through the various sections of Failover Cluster Manager can be beneficial. You might not even know that a CSV is in Redirected Access Mode if you don’t look.
4. Use the Provided Auditing Tools
A quick and easy way to locate obvious problems is to let the system look for them.
It’s almost imperative to use the Cluster Validation Wizard. For one thing, Microsoft will not obligate itself to provide support for any cluster that has not passed validation. For another, it can uncover a lot of problems that you might otherwise not ever be aware of. Remember your validation report must be kept up-to-date. Get a new one if you add or remove any nodes or storage. Technically, you should also update it if you update firmware or drivers as well, although that’s substantially less critical. Reports are saved in C:WindowsClusterReports on every node for easy viewing later. This wizard does cause Cluster Shared Volumes to be briefly taken offline, so only run this tool on existing clusters during scheduled maintenance windows.
Don’t forget about the Best Practices Analyzer. The analyzer for Hyper-V is now rolled into Server Manager. If you combine all the hosts for a given cluster into one Server Manager display, you can run the BPA against them all at once. If you’re accustomed to writing off Server Manager because it was not so useful in previous editions, consider giving it another look. At additional hosts using the second option on the first page:
Adding other hosts in Server Manager
I don’t want to spend a lot of time on the Best Practices Analyzer in this post, but I will say that the quality of its output is more questionable than a lot of other tools. I’m not saying that it isn’t useful, but I wouldn’t trust everything that it says.
5. Avoid Geographically Dispersed Hyper-V Clusters
Geographically-dispersed clusters, also known as “stretched” clusters or “geo-clusters”, are a wonderful thing for a lot of roles, and can really amp up your “cool” factor and buzzword-compliance, but Hyper-V is really not the best application. If you have an application that requires real-time geographical resilience, then it is incumbent upon the application to provide the technology to enable that level of high availability. The primary limiting factor is storage; Hyper-V is simply not designed around the idea of real-time replicated storage, even using third-party solutions. It can be made to work, but doing so typically requires a great deal of architectural and maintenance overhead.
If an application does not provide the necessary features and you can afford some downtime in the event of a site being lost or disconnected, Hyper-V Replica is the preferred choice. Build the application to operate in a single site and replicate it to another cluster in another location. If the primary site is lost, you can quickly fail over to the secondary site. A few moments of data will be lost and there will be some downtime, but the amount of effort to build and maintain such a deployment is a fraction of what it would take to operate a comparable geo-cluster.
Of course, “never say never” wins the day. If you must build such a solution, remember to leverage features such as Possible Owners. Take care with your quorum configuration, and make doubly certain that absolutely everything is documented.
6. Strive for Node Homogeneity
Microsoft does not strictly require that all of the nodes in a cluster have the same hardware, but you should make it your goal. Documentation is much easier when you can say, “5 nodes of this” rather than maintain a lot of different build forms with the required differential notation.
This is a bigger deal for Hyper-V than for most other clustered roles. There aren’t any others that I’m aware of that have any noticeable issues when cluster nodes have different CPUs, beyond the expected performance differentials. Hyper-V, on the other hand, requires virtual machines to be placed in CPU compatibility mode or they will not Live Migrate. They won’t even Quick Migrate unless turned off. The end effects of CPU compatibility mode are not documented in an easy-to-understand fashion , but it is absolutely certain that the full capabilities of your CPU are not made available to any virtual machine in compatibility mode. The effective impact depends entirely upon what CPU instructions are expected by the applications on the guests in your Hyper-V cluster, and I don’t know that any software manufacturer publishes that information.
Realistically, I don’t expect that setting CPU compatibility mode for most typical server applications will be an issue. However, better safe than sorry.
7. Use Computer-Based Group Policies with Caution
Configurations that don’t present any issues on stand-alone systems can cause problems when those same systems are clustered. A notorious right that causes Live Migration problems when tampered with is “Create Symbolic Links”. It’s best to either avoid computer-scoped policies or only use those that are known and tested to work with Hyper-V clustering. For example, the GPO templates that ship with the Microsoft Baseline Security Analyzer will not cause problems with only one potential exception: they disable the iSCSI service. Otherwise, use them as-is.
8. Develop Patterns and Practices that Prevent Migration Failures
Using dissimilar CPUs and bad GPOs aren’t the only way that a migration might fail. Accidentally creating a virtual machine with resources placed on local storage is one potential problem. A practice that will avoid this is to always change the default locations on every host to shared storage. This helps control for human errors and for the (now fixed) bug in Failover Cluster Manager where it sometimes caused some components to be placed in the default storage location when it created virtual machines. A related pattern is to discourage the use of Failover Cluster Manager to create virtual machines.
A few other migration-breakers:
- Always use consistent naming for virtual switches. A single-character difference in a virtual switch name will prevent a Live/Quick Migration.
- Avoid using multiple virtual switches in hosts to reduce the possibility that a switch naming mismatch will occur.
- Do not use private or internal virtual switches on clustered hosts. A virtual machine cannot Live Migrate if it is connected to a switch of either type, even if the same switch appears on the target node.
- Use ISO images from shared storage. If you must use an image hosted locally, remember to eject it as soon as possible.
9. Use Multiple Shared Storage Locations
The saying, “Don’t place all your eggs in one basket,” comes to mind. Even if you only have a single shared storage location, break it up into smaller partitions and/or LUNs. The benefits are:
- Logical separation of resources; examples: general use storage, SQL server storage, file server storage.
- Performance. If your storage device doesn’t use tiering, you can take advantage of two basic facts about spinning disks: performance is better for data closer to the outer edge of the spindle (where the first data is written) and data is more quickly accessed when it is physically close on the platter. While I don’t worry very much about either of these facts and have found all the FUD around them to be much ado about nothing, there’s no harm in leveraging them when you can. Following the logical separation bullet point, I would place SQL servers in the first LUNs or partitions created on new disks and general purpose file servers in the last LUNs. This limits how much fragmentation will affect either and keeps the more performance-sensitive SQL data in the optimal region of disk.
- An escape hatch. In the week leading up to writing this article, I encountered some very strange problems with the SMB 3 share that I host my virtual machines on. I tried for hours to figure out what it was and finally decided to give up and recreate it from scratch. Even though I only have the one system that hosts storage, it had a traditional iSCSI Clustered Shared Volume on it in addition to the SMB 3 share. I used Storage Live Migration to move all the data to the CSV, deleted and recreated the share, and used Storage Live Migration to move all the virtual machines back.
- Defragmentation. As far as I’m concerned, disk fragmentation is far and away the most overblown topic of the modern computing era. But, if you’re worried about it, using Storage Live Migration to move all of your VMs to a temporary location and then moving them all back will result in a completely defragmented storage environment with zero downtime.
10. Use at Least Two Distinct Cluster Networks, Preferably More
As you know, a cluster will define networks based on unique TCP/IP subnets. What some people don’t know is that it will create distinct TCP/IP streams for inter-node communication based on this fact. So, some people will build a team of network adapters and only use one or two cluster networks to handle everything: management, cluster communications such as heartbeating, and Live Migration. Then they’ll be surprised to discover network contention problems, such as heartbeat failures during Live Migrations. This is because, without the creation of distinct cluster networks, it might attempt to co-opt the same network stream for multiple functions. All that traffic would be bound to only one or two adapters while the others stay nearly empty. Set up multiple networks to avoid this problem. If you’re teaming, create multiple virtual network adapters on the virtual switch for the hosts to use.
11. Minimize the Number of Network Adapter Teams
In the 2008 R2 days, people would make several teams of 1GbE adapters: one for management traffic, one for cluster traffic, and one for Live Migration. Unfortunately, people are still doing that in 2012+. Please, for your own sake, stop. Converge all of these into a single team if you can. It will result in a much more efficient and resilient utilization of hardware.
12. Do Not Starve Virtual Machines to Benefit Live Migration or Anything Else
It’s really disheartening to see 35 virtual machines crammed on to a few gigabit cards and a pair of 10 GbE cards reserved for Live Migration, or worse, iSCSI. Live Migration can wait and iSCSI won’t use that kind of bandwidth often enough to be worth it. If you have two 10 GbE cards and four built-in 1GbE ports, use the gigabit ports for iSCSI and/or Live Migration. Better yet, just let them sit empty and use convergence to put everything on the 10GbE adapters. Everything will be fine. Remember that your Hyper-V cluster is supposed to be providing services to virtual machines; forcing the virtual machines to yield resources to cluster services is a backwards design.
13. Only Configure QoS After You’ve Determined that You Need QoS
I’ve seen so many people endlessly wringing their hands over “correctly” configured QoS prior to deployment that I’ve long since lost count. Just stop. Set your virtual switches to use the “Weight” mode for QoS and leave everything at defaults. If you want, set critical things to have a few guaranteed percentage points, but stop after that. Get your deployment going. Monitor the situation. If something is starved out, find out what’s starving it and address that because it’s probably a run-away condition. If you can’t address it because it’s normal, consider scaling out. If you can’t scale out, then configure QoS. You’ll have a much better idea of what the QoS settings should be when you actually have a problem to address than you ever will when nothing is wrong. The same goes for Storage QoS.
14. Always be Mindful of Licensing
I’m not going to rehash the work we’ve already done on this topic. You should know by now that every Windows instance in a virtual machine must have access to a fully licensed virtualization right on every physical host that it ever operates on. This means that, in a cluster environment, you’re going to be buying lots and lots of licenses. That part, we’ve already explained into the ground. What some people don’t consider is that this can affect the way that you scale a cluster. While Microsoft is taking steps in Windows Server 2016 licensing to increase the cost of scaling up on a single host, it’s still going to be cheaper for most people in most situations than scaling out, especially for those people that are already looking at Datacenter licenses. In either licensing scheme, keep in mind that most people are not actually driving their CPUs nearly as hard as they could. Memory is likely to be the bigger bottleneck to same-host scaling than CPU.
15. Keep in Mind that Resources Exhaust Differently in a Cluster
When everything is OK, virtual machines in a cluster really behave exactly like virtual machines scattered across separate stand-alone hosts. But, when something fails or you try to migrate something, things can get weird. A migration might fail for a virtual machine because it is currently using more RAM than is available on the target host. But, if its host failed and the destination system is recovering from a crash condition, it might succeed. That’s because the virtual machine’s Startup Dynamic RAM setting is likely to be lower than its running RAM.
Of course, that’s only talking about a single virtual machine. What about the much more probable scenario that a host has crashed and several VMs need to move? That’s when all of those priority settings come into play. If you have more than two nodes in your cluster, the cluster service will do its best job of getting everyone online wherever they fit. But, you need to have decided in advance which virtual machines were most important. If you haven’t, then the creep of virtual machine sprawl might have left you in a situation of needing to make some hard decisions to turn off healthy virtual machines in order to bring up vital crashed machines. Manual intervention defeats a lot of the purpose of clustering.
Shared storage behaves differently than local storage in more than one way. Sure, it’s remote, and that has its own issues. But, the shared part is what I’m focusing on. Remember how I said it wasn’t a good idea to put your iSCSI on 10 GbE if it would take away from virtual machines? This is why. Sure, maybe, just maybe, your storage really can supply 20 Gbps of iSCSI data. But can it simultaneously supply 60 Gbps for 3 Hyper-V hosts that each have two 10GbE NICs using MPIO? If it can, do you really only have only three hosts accessing it? (if you answered “yes” and “yes”, most admins in the world are jealous) The point here is that the size of the pipe that a host has into your storage sets the upper limit on how that host can control — and potentially dominate — that storage system’s resources. Remember that it’s really tough to get a completely clear image of the way that storage performance is being consumed in a cluster when compared to a standalone system.
16. Do Not Cluster Virtual Machines that Don’t Need It
Don’t make your virtualized domain controllers into highly available virtual machines. The powers of Hyper-V and failover clustering pale in comparison to the native resiliency features of Active Directory. If you have any other application with similar powers, don’t make it HA via Hyper-V clustering either. Remember that you have to make licenses available everywhere that a VM might run anyway. If it provides better resiliency to just create a separate VM and configure application high availability, choose that route every time.
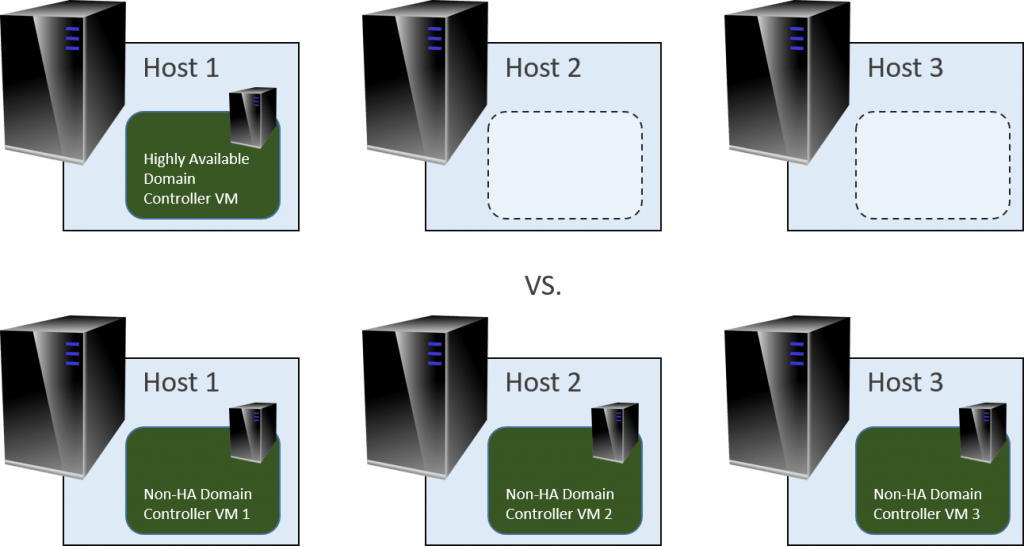
Both groups require the same licensing, but the second group is more resilient
17. Don’t Put Non-HA Machines on Cluster Shared Volumes
Storage is a confusing thing and it seems like there are no right or wrong answers sometimes, but you do need to avoid placing any non-HA VMs on a CSV. Microsoft doesn’t support it and it will cause VMM to panic. Things can get a little “off” when the node that owns the CSV isn’t the node that owns the non-HA virtual machine placed on it. It’s also confusing when you’re looking at a CSV and see more virtual machine files than you can account for in Failover Cluster Manager. Use internal space, singularly attached LUNs, or SMB 3 storage for non-HA VMs.
18. Minimize the Use of non-HA VMs in a Cluster
Any time you use a non-HA VM on a clustered host, make sure that it’s documented and preferably noted right on the VM. This helps eliminate confusion later. Some helpful new admin might think you overlooked something and HA the VM for you, even though you had a really good reason not to do so. I’m not saying “never”; I do it myself in my system for my virtualized domain controllers. But, if I had extra stand-alone Hyper-V hosts, that’s where I’d put my non-HA VMs.
19. Ask Somebody
If you don’t know, start with your favorite search engine. The wheels for both Hyper-V and failover clustering are very round, and there are lots of people that have written out lots of material on both subjects.
If that fails (and please, only if that fails), ask somebody. My favorite place is the TechNet forums, but that’s only one of many. However, on behalf of myself and everyone else who writes publicly, please don’t try to contact an individual directly. There’s a reason that companies charge for support; it’s time-consuming and we’re all busy people. Try a community first.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


33 thoughts on "19 Best Practices for a Hyper-V Cluster"
Probably good content here, but seriously– light gray text on white background ???
Text is black on all my PCs and devices, but I’ll pass this on to the design controllers.
Thanks. Yeah, it was on my iPad. Win PC display is better.
And thanks for writing these– Definitely useful material.
Thank you, both for the compliment and for the information. I assume they have built a display conditional for iPads or tablets that isn’t working as expected.
Please do something about the font! Excellent information but it’s a pain to get through it all. On Google Chrome on a Mac, the font seems greyish/light black but the font-spacing is the real culprit.
And by the way, to help with documentation of Hyper-V clusters, there’s a great free tool (PowerShell based) on TechNet–
https://gallery.technet.microsoft.com/Get-HyperVInventory-Create-2c368c50
And by the way, to help with documentation of Hyper-V clusters, there’s a great free tool (PowerShell based) on TechNet–
https://gallery.technet.microsoft.com/Get-HyperVInventory-Create-2c368c50
good post. i was interested in your point about the old way of networking, and changing that too using a converged model. I still deploy plenty of clusters with just 1GBs nics, so do it the “old way”. From what i’ve read convergence is more suitable to say, a pair of 10GB ports. Would you recommened using convergence over (again for example) a server with 4x 1GBs ports?
Your wording implies that you’d have to make a choice between converging and using 1GbE networking. Why would that be the case?
Most of the literature out there is written by people that don’t have budgetary concerns and assume that everyone is dropping 1GbE. Convergence can extend the life of 1GbE.
hi,
sorry bad choice of words.
What i meant was that all the examples I have seen in technet etc of convergence and hyper-v – 10GBE are the NICs they are using.
However, for a lot of SMBs they are still buying servers with 1GBE, they cannot afford 2x10GBE switches for example.
So, i guess what I am asking is would you perform convergence with a {for example} a server with 6 x 1GBE ports or would you continue to do it the “older” 2008 method?
It’s not your choice of words at all. There is a widespread assumption among tech writers, including those that generate TechNet articles, that businesses with fewer than 1,000 employees are either irrelevant or have magic access to disproportionately large budgets. That’s why the majority of the literature on this subject looks the way that it does.
I would absolutely converge a 1GbE system with the exception of iSCSI. If iSCSI is a factor, with 6x 1GbE cards I would use 4x for convergence and 2x for iSCSI. If iSCSI is not a factor, then I would use combine all 6 into a single converged adapter.
hi,
sorry bad choice of words.
What i meant was that all the examples I have seen in technet etc of convergence and hyper-v – 10GBE are the NICs they are using.
However, for a lot of SMBs they are still buying servers with 1GBE, they cannot afford 2x10GBE switches for example.
So, i guess what I am asking is would you perform convergence with a {for example} a server with 6 x 1GBE ports or would you continue to do it the “older” 2008 method?
Thanks for taking the time to reply Eric.
Cheers
Dave
Thanks for taking the time to reply Eric.
Cheers
Dave
Can you please elaborate on convergence mentioned in point 11 & 12?
My HPV hostst have a teamed 10Gbps connection for guest traffic, and another 8 1GBps ports that are all configured in non-teamed pairs; iscsi, LM, Cluster, and a pair for management access.
What would be the benefit of moving all of these to the 10GBps connections and how would I still make sure it’s redundant?
The benefit of moving to the 10GbE is that your streams are no longer restricted to 1Gbps. I would be willing to bet that the performance chart for your 10GbE connections is nearly flat. Verification instructions: http://www.altaro.com/hyper-v/how-to-meter-track-hyper-v-networking-performance-mrtg/. I don’t think that I would move iSCSI, and I might consider leaving management on 1GbE if it’s not impeding backup, but the rest I would move without question.
Your 10GbE is teamed. That’s your redundancy. Unless, of course, you’re having problems with it and don’t trust it.
Can you please elaborate on convergence mentioned in point 11 & 12?
My HPV hostst have a teamed 10Gbps connection for guest traffic, and another 8 1GBps ports that are all configured in non-teamed pairs; iscsi, LM, Cluster, and a pair for management access.
What would be the benefit of moving all of these to the 10GBps connections and how would I still make sure it’s redundant?
The benefit of moving to the 10GbE is that your streams are no longer restricted to 1Gbps. I would be willing to bet that the performance chart for your 10GbE connections is nearly flat. Verification instructions: https://www.altaro.com/hyper-v/how-to-meter-track-hyper-v-networking-performance-mrtg/. I don’t think that I would move iSCSI, and I might consider leaving management on 1GbE if it’s not impeding backup, but the rest I would move without question.
Your 10GbE is teamed. That’s your redundancy. Unless, of course, you’re having problems with it and don’t trust it.
Great article! I’m going through all the Hyper-V cluster articles now in prep for setting this up on some off-lease hardware we’re getting to replace our even more decrepit infrastructure.
Just wanted to point out a wee oversight – in “9. Use Multiple Shared Storage Location”, in the performance section, it says that on spinning media, performance is better on tracks placed closer to the spindle – while it’s actually the opposite that’s true. Constant angular velocity and constant areal density (both true on a spinning media) will result in an increase in the number of sectors read/written per revolution (ie. per track), the further away one is from the center of the spinning media. Anyway, I’m sure the author already knows this, and it was just a simple fumble 🙂
Oh, right. It’s one of those things that I know in my brain but almost always somehow comes out backwards when it makes to my writing. We all have those things.
Great article! I’m going through all the Hyper-V cluster articles now in prep for setting this up on some off-lease hardware we’re getting to replace our even more decrepit infrastructure.
Just wanted to point out a wee oversight – in “9. Use Multiple Shared Storage Location”, in the performance section, it says that on spinning media, performance is better on tracks placed closer to the spindle – while it’s actually the opposite that’s true. Constant angular velocity and constant areal density (both true on a spinning media) will result in an increase in the number of sectors read/written per revolution (ie. per track), the further away one is from the center of the spinning media. Anyway, I’m sure the author already knows this, and it was just a simple fumble 🙂
Good tips… Thanks Eric, your post will help me a lot in my Hyper-V implementations. Congratulations