Save to My DOJO

In the depths of Windows Server Failover Clustering (WSFC), where the graphical interface cannot reach, network traffic shaping tools await the brave administrator. Most clusters work perfectly well without tuning network parameters, but not all. If you have low-speed networking hardware or extremely tight bandwidth requirements, then prioritization might help. This article shows how to leverage these advanced controls.
If you have spent any time researching cluster network prioritization, then you likely noticed that most material dates back about a decade. This topic concerned us when networking was more primitive and unteamed gigabit connections pervaded our datacenters. Several superior alternatives have arisen in the meantime that requires less overall effort. You may not gain anything meaningful from network prioritization and you might set traps for yourself or others in the future.
Network Speed Enhancements in Windows
Windows Server versions beyond 2008 R2 provide network adapter teaming solutions. Additionally, 2012 added SMB multichannel which automatically works for all inter-node communications. These tools alone, with no special configuration, cover the bulk of network balancing problems that you can address at the host.
Speed Enhancements in Networking Hardware
For demanding loads, you have hardware-based solutions. Higher-end network adapters have significant speed-enhancing features, particularly RDMA (remote direct memory access), which comes on InfiniBand, RoCE, and iWarp. If that’s not enough, you can buy much faster hardware than 10 gigabit. These solutions solve QoS problems by providing so much bandwidth and reduced latency that contention effectively does not occur.
Software QoS Solutions
You can also configure software QoS for Windows Server and for Hyper-V virtual machines. This has similar challenges to cluster network prioritization, which we’ll discuss in the next section. Sticking with the QoS topic, networking hardware offers its own solutions. Unlike the other techniques in this article, QoS within the network extends beyond the hosts and shapes traffic as it moves between systems. Furthermore, Windows Server can directly interact with the 802.1p QoS standard that your hardware uses.
Drawbacks of WSFC Network Prioritization
Research the above options before you start down the path of cluster network shaping. This solution has a few problems that you need to know about:
-
- It only works for networking traffic that Windows Server Failover Clustering understands. Virtual machine traffic does not benefit.
-
- The use of cluster network shaping is non-obvious. It appears nowhere in any GUI or standard report. You must clearly document your configuration and ensure that anyone troubleshooting or reconfiguring knows about it.
-
- WSFC network prioritization has no effect outside the cluster, which can make it even more limited than software-only QoS solutions.
-
- WSFC network prioritization knows nothing about true QoS solutions and vice versa. Combining this technology with others leads to unknown and potentially unpredictable behavior.
-
- The most likely answer that you will receive if you ask anyone for help and support will be: “Revert network prioritization to automatic and try again.” I do not know of any problems other than the obvious (poor tuning that inappropriately restricts traffic), but I have not seen everything.
Essentially, if you still have all-gigabit hardware and QoS solutions that do not shape traffic the way you want, then WSFC network prioritization might serve as a solution. Otherwise, it will probably only provide value in edge cases that I haven’t thought of yet.
Cluster Networking Characteristics
While many of the technologies mentioned in the previous section have reduced the importance of distinct cluster networks, you still need to configure and use them properly. This section outlines what you need to configure and use for a healthy cluster.
Cluster Network Redundancy
At its core, cluster networking depends on redundancy to reduce single-point-of-failure risks. What you see here shows the legacy holdover of unteamed and non-multichannel technologies. However, even these advanced solutions cannot fully ensure the redundancy that clustering desires, nor will everyone have sufficient hardware to use them.
WSFC networks operate solely at layer 3. That means that a cluster defines networks by IP addresses and subnet masks. It does not know anything about layer 2 or layer 1. That means that it cannot understand teaming or physical network connections. In classical builds, one network card has one IP address and belongs to one Ethernet network, which might give the impression that network clustering knows more than it actually does.
When the cluster service on a host starts up or detects a network configuration change, it looks at all IP addresses and their subnet masks. It segregates distinct subnets into “cluster networks”. If one host contains multiple IP addresses in the same cluster network, then WSFC chooses one and ignores the rest. It then compares its list of cluster networks and IP addresses against the other nodes. This discovery has four possible outcomes per discovered network:
-
- The cluster finds at least one IP address on every node that belongs to the discovered network and all are reachable in a mesh. The cluster creates a cluster network to match if a known network does not already exist. It marks this network as “Up”. If a node has multiple addresses in the same network, the cluster chooses one and ignores the rest.
-
- The cluster finds an IP address on at least one, but not all nodes, that belong to the discovered network and all are reachable in a mesh. The cluster will treat this network just as it would in the first case. This allows you to design clusters with complex networking that contain disparate networks without getting an error. It also means that you can forget to assign one or more IP addresses without getting an error. Check network membership.
-
- The cluster finds an IP address on one or more nodes, but the mesh connections between them do not fully work. If the mesh pattern fails between detected addresses, the cluster marks the network as “partitioned”. This only means that the layer 3 communications failed. You usually cannot tell from this tool alone where the problem lies.
-
- The cluster fails to detect any members of a previously discovered network. Removing all the members of a network will cause WSFC to remove it from the configuration.
You can view your networks and their status in Failover Cluster Manager on the Networks tab:

In the lower part of the screen, switch to the Network Connections tab where you can see the IP addresses chosen on each node and their status within the cluster. In a two-node cluster like this one, any unreachable network member means that it marks all as unreachable. In a three+ node cluster, it might be able to detect individual node(s) as having trouble.

This article will not go into troubleshooting these problems. Understand two things:
-
- Cluster networking understands only layer 3 (TCP/IP).
-
- Cluster networking understands only cluster traffic. It works for internode communications and clustered roles with IP addresses known by the clustering service.
If you do not fully understand either of these points, stop here and perform the necessary background research. For the first, we have some introductory networking articles. I will call out some of the specific implications in the next section. For the second point, I mostly want you to know that nothing that we do here will directly impact Hyper-V virtual machine traffic. In a cluster that runs only Hyper-V virtual machines, networks marked as “Cluster Only” and “Cluster and Client” have no functional difference.
Cluster Network Roles and Uses
In pre-2012 clusters, we recommended four network roles. Depending on your hardware and configuration, you should employ at least two for complete redundancy. This section covers the different roles and concepts that you can use for optimal configuration.
Management Cluster Network
If you create only one cluster network, this will be it. It holds the endpoints of each node’s so-called “management” traffic. This network has a great deal of misunderstanding surrounding it. Even the typical “management” name fits only by usage convention. Traditionally, the IP endpoint that holds a node’s DNS name also marks its membership in this network. As a result, traffic inbound meant for the node, not a cluster role, goes to this address.
The cluster will also use the management network for its own internode purposes, although, by default, it will use all other networks marked for cluster traffic first.
Absolutely nothing except convention prevents you from creating a network, excluding cluster traffic, and using that for management. I would not consider this an efficient use of resources in most cases, but I could envision some use cases.
Cluster Communications Network
You can specify one or more networks specifically to carry cluster traffic. While some documentation suggests, or outright states, otherwise, this encompasses all types of internode traffic. Three general functions fall into this category:
-
- Node heartbeat
-
- Cluster configuration synchronization
-
- Cluster Shared Volume traffic
The most common error made with this network comes from the widespread belief that CSV traffic has some distinction from other cluster traffic that allows you to separate it onto a network away from the other cluster communication functions. It does not.
Cluster Application Networks
The relationship between clustered objects and cluster networks leads to a great deal of confusion, exacerbated by unclear documentation and third-party articles based on misunderstandings. To help clear it up, understand that while some the cluster understands networking for some applications, it does not understand all. Applications within a cluster have three different tiers:
-
- Per-role cluster IP address. You will see this for roles that fully integrate with clustering, such as SQL server. Check the properties of the role within Failover Cluster Manager. If you see an IP address, the cluster knows about it.
-
- Client network binding. When you mark a network with the “Cluster and Client” role, the cluster can utilize it for hosting simple roles, such as scripts.
-
- No cluster awareness. A cluster can host roles for which it does not control or comprehend the network configuration. Chief among these, we find virtual machines. The cluster knows nothing of virtual machine networking.
We will revisit that final point further on along with network prioritization.
Live Migration Network
The Live Migration cluster network represents something of an anomaly. It does not belong to a role and you can exclude it from carrying cluster traffic, but you control it from the cluster and it only “works” between cluster nodes.
You configure the networks that will carry internode Live Migration traffic from the Network tree item in Failover Cluster Manager:

As with any other IP endpoint, nodes can use their members of Live Migration networks for any non-cluster purpose.
Non-Cluster Communications
Everything not covered above falls outside the control of the cluster service. Individual nodes can operate their own services and functions separate from the cluster. Due to common confusion, I want to call out three well-known items that fall into this category:
-
- Virtual machine traffic
-
- Storage traffic (host-to-storage connections, not internode CSV traffic)
-
- Host-level backup traffic
The cluster knows nothing of the Hyper-V virtual switch. Furthermore, the virtual switch behaves as a layer 2 device and WSFC networking only operates at layer 3.
In fair weather, each node controls its own I/O. If a node has a problem connecting to storage and that storage is configured in one or more CSVs, then the cluster can redirect CSV traffic across the network via a node that can reach the CSV. However, the cluster classifies that traffic under the general “cluster” type.
I do not know of any backup tool that utilizes the cluster service to perform its duty. Therefore, each node handles its own backup traffic.
Once you understand what traffic the cluster cannot control, you next must understand that cluster network prioritization only impacts it indirectly and partially. The reasons will become more obvious as we investigate the implementation.
How to Discover and Interpret Cluster Network Prioritization
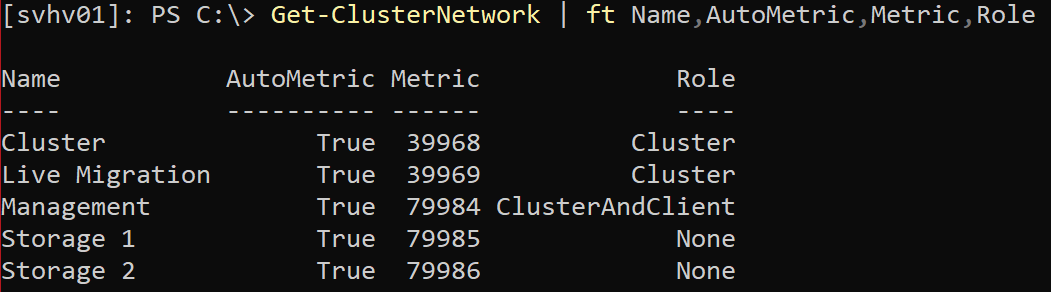
Before configuring anything, look at the decisions that the cluster made. Open a PowerShell prompt either in a remote session to a node directly on a node’s console and run:
-
- Get-ClusterNetwork | ft Name,AutoMetric,Metric,Role
This will output something like the following:

The “Name” and “Role” columns mean the same thing as you see in Failover Cluster Manager. “AutoMetric” means that the cluster has decided how to prioritize the network’s traffic. “Metric” means the currently assigned metric, whether automatic or not. Lower numbered networks receive higher priority.
To reiterate, these priorities only apply to cluster traffic. In other words, when the cluster wants to send data to another node, it starts at the lowest numbered network and works its way upward until it finds a suitable path.
Consider the real-world implications of the configuration in the screenshot above. The cluster has marked the “Management” network with the highest priority that can carry cluster traffic. The “Cluster” network has the lowest priority. The displayed cluster runs only Hyper-V virtual machines and stores them on an SMB target. It has no CSVs. Therefore, cluster traffic will consist only of heartbeat and configuration traffic. I have used Failover Cluster Manager as shown in a preceding section to prioritize Live Migration to the “Live Migration” network and set the Cluster and Management networks to allow Live Migration as second and third priorities, respectively. Therefore:
-
- Internode traffic besides Live Migration will use the Cluster network if it is available, then the Live Migration, and as a last resort, the Management network.
-
- Internode Live Migrations will prefer the Live Migration network, then the Cluster network, then the Management network.
-
- Because cluster and Live Migration traffic use the Management network as a last resort, they should leave it wide open for my backup and other traffic. Due to isolation, non-cluster traffic does not have any access to the Cluster or Live Migration networks.
-
- None of the preceding traffic types can operate on either Storage network.
The cluster automatically made the same choices that I would have, so I do not see any need to change any metrics. However, it does not make these decisions randomly. “Cluster only” networks receive higher priority than “Cluster and client” networks. Networks marked “None” appear in the list because they must, but the cluster will not use them. As for the ordering of networks with the same classification, I have not gathered sufficient data to make an authoritative statement. However, I always give my “Cluster” networks a lower IP range than my “Live Migration” networks, and the cluster always sorts them in that order (ex: 192.168.150.0/24 for the “Cluster” network and 192.168.160.0/24 for the “Live Migration” network) and my clusters always sort them in that order. But, “L” comes after “C” alphabetically, so maybe that’s why. Or, perhaps I’m just really lucky.
I want to summarize the information before I show how to make changes.
Key Points of Cluster Network Prioritization
We covered a lot of information to get to this point, and some of it might conflict with material or understanding that you picked up elsewhere. Let’s compress it to a few succinct points:
-
- Cluster network prioritization is not a quality-of-service function. When the cluster service wants to send data to another node, it uses this hierarchy to decide how to do that. That’s it. That’s the whole feature.
-
- The cluster service uses SMB to perform its functions, meaning that SMB multichannel can make this prioritization irrelevant.
-
- In the absence of redirected CSV traffic, a cluster moves so little data that this prioritization does not accomplish much.
-
- Cluster network prioritization does not “see” network adapters, virtual switches, or non-cluster traffic. It only recognizes IP addresses and only cares about the ones that carry cluster traffic.
-
- You can only use cluster network prioritization to shape non-cluster traffic via process of elimination as discussed in the real-world example. Due to the low traffic needs of typical cluster traffic, you may never see a benefit.
How to Set Cluster Network Prioritization
Hopefully, you read everything above and realized that you probably don’t need to know how to do this. That said, a promise is a promise, and I will deliver.
The supported way to manually configure cluster network priority is through PowerShell. You can also use the registry, although I won’t directly tell you how because you can wreck it that way and I’m not sure that I could help you to put it back. I think you can also use the deprecated cluster CLI, but I never learned how myself and it’s deprecated.
Unfortunately, even though PowerShell is the only supported way, the PowerShell module for Failover Clustering remains surprisingly primitive. Much like PowerShell 2.0-era snap-ins, it usually requires you to acquire an object and manipulate it. It implements very few variables beyond “Get-“, and the ones that it has do not expose much functionality. Furthermore, the module implements the extremely rare “packet privacy” setting, which means that you must carry out most of its functions directly on a node’s console or in a first-hop remote session. I believe that the underlying CIM API exposed by the cluster service imposes the packet privacy restriction, not PowerShell. I do not know what problem packet privacy solves that makes it worth the potential administrative frustration. Just know that it exists and how to satisfy it.
So, with all of the caveats out of the way, let’s change something. Again, I will work with the network list as displayed earlier:
Let’s imagine that my manager does not trust the auto-metric to keep the “Cluster” network at first priority and wants me to force it. To do that, I must manually give the “Cluster” network a metric lower than anything that the cluster might pick for itself. As you can see, the cluster uses very high numbers, so I can hit that target easily.
First, acquire an object that represents the “Cluster” network:
-
- $ClusterNetwork = Get-ClusterNetwork -Name ‘Cluster’
Second, modify the acquired object’s “Metric” value:
-
- $ClusterNetwork.Metric = 42
Third, verify:
-
- Get-ClusterNetwork | ft Name, AutoMetric, Metric
You should see something like the following:

I performed the object acquisition and parameter setting in two discrete steps for clarity. If you only want to modify the metric property, then you do not need to keep the object and can perform it all on one line. I will demonstrate this by reverting to the auto-metric setting:
-
- (Get-ClusterNetwork -Name ‘Cluster’).AutoMetric = $true
By using Get-ClusterNetwork to place the object into the $ClusterNetwork variable in the first demonstration, I could continue on to make other changes without reacquiring the object. In the second demonstration, I lose the object immediately after changing its setting and would need to acquire it again to make further changes. Also, I find the second form harder to read and understand. It might perform marginally faster, but it would cost more time to prove it than it could ever be worth.
Changes to the cluster network priority take effect immediately.
Going Forward with Cluster Network Prioritization
Ordinarily, I would wrap up the article with some real-world ideas to get you going. Really, I don’t have any for this one except, don’t. You probably have a better way to solve whatever problem you face than this. Hopefully, this article mainly serves as an explanation of how newer features have made this one obsolete and that much of the existing material gets a lot of points wrong. If you have clusters configured under the patterns from 2008 R2 and earlier, review them to see if you can successfully employ the auto-metric setting. Happy balancing!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


5 thoughts on "Network Prioritization for Modern Windows Failover Clusters"
testtest