Save to My DOJO
Table of contents
- What is High Availability?
- What High Availability Technologies Did Hyper-V Already Have?
- What’s New for High Availability in Hyper-V 2016?
- Site-Aware Clusters
- Workgroup and Multi-Domain Clusters
- Delayed Response to Failures
- Virtual Machine Start Order
- Clustering Virtual Machines Has Never Been a Better Choice
Hyper-V and Failover Clustering joined forces back in 2008 to increase the resilience of virtual machines. Each subsequent version of Windows Server strengthens the bond between these two components. Virtual machines benefit from ever-improving strategies to reduce the impact of outages, both planned and unplanned. Windows Server 2016 adds many exciting new features to this mix.
What is High Availability?
“High availability” is a metric. If a service is available every time that someone tries to use it, then it is highly available. If it’s down for ten seconds in one month, but a user tries to access it during those ten seconds, then it might fall short of your definition of “highly available”. You might establish a formal definition for a given service. For instance, “Users must be able to access the web payments portal 99.99% of the time”. You might take a more relaxed approach. For instance, “The employee performance review site should work most of the time.” The organization decides what “high availability” means. It is not a technology. However, you have access to several availability-boosting technologies.
What High Availability Technologies Did Hyper-V Already Have?
If you’re already accustomed to the high availability technologies of previous versions of Hyper-V, you might want to skip this section. When I’m learning about a new-to-me technology, I like to read more than just the “What’s New” lists. For those of you currently in that position, here’s a list of the high availability-enabling technologies that were already available to Hyper-V (Microsoft Failover Clustering enables most of them):
- Automatic failover of virtual machines to another physical host. This could be triggered by:
- Complete system failure (ex: power outage or blue screen)
- Loss of network connectivity for the host (indicated by an inability to contact the rest of the cluster)
- Loss of network connectivity for the guest (introduced in 2012 R2)
- Quick Migration: a controlled failover in which a virtual machine’s running state is saved to disk and it is restarted on another failover cluster node
- Live Migration: a controlled failover in which a virtual machine’s running state is transitioned to another failover cluster node without interruption (introduced in 2008 R2)
- New in 2012 R2: An orderly host shutdown will cause clustered virtual machines to be Live Migrated automatically
- Storage Live Migration: some or all of the files that belong to a virtual machine can be moved to a new location on the same or different storage without interruption
- Shared Nothing Live Migration: a controlled move of the entirety of a virtual machine, including its running state and storage, to another Hyper-V system without interruption (introduced in 2012)
- Redirected Access: if a virtual machine’s files reside on a cluster’s Cluster Shared Volume and the physical host loses direct connectivity to the underlying storage subsystem, disk I/O will be re-routed over the network through a node that can reach the storage subsystem (introduced in 2008 R2, enhanced in later versions)
- Monitored services: the cluster can monitor one or more specified services within a virtual machine. If a service repeatedly fails, the cluster can restart its containing virtual machine on another node.
That’s an impressive list in its own right. Some people will take exception to the inclusion of some of the Live Migration on this list because they are not automatic. If it helps to reduce or eliminate downtime for an operation, it belongs here. If anything, the list isn’t comprehensive enough.
Hyper-V in Windows Server 2016 greatly expands upon this list.
What’s New for High Availability in Hyper-V 2016?
Enough about the old. Let’s talk about the new!
Cloud Witness
The new Azure Cloud Witness feature belongs to Microsoft Failover Clustering, not Hyper-V. However, Hyper-V’s virtual machines benefit from it just as much as any other clustered role.
On the surface, clustering is simple: multiple computers connect to common storage, providing compute resiliency for protected roles. If you were designing such a technology from scratch, one of the first problems that you’d encounter is, “What happens if none of the nodes are down, but they don’t know that the others aren’t down? Won’t they all try to run the same role?” This is known as a “split-brain” problem.
Microsoft Failover Clustering’s anti-split-brain techniques relies on a quorum methodology. If a node cannot contact enough other nodes to maintain a quorum, it exits the cluster and won’t run any role. That works well for a cluster with an odd number of nodes. A cluster with an even node count, especially if that count is two, needs a tie-breaker. For the past several versions, we have had two options: a shared fibre channel or iSCSI LUN (called a disk witness) or an SMB share (called a share witness). With the introduction of Dynamic Quorum in Windows Server 2012, it’s now sensible to use a witness in all clusters, regardless of node count.
Most administrators will simply choose to place their quorum on the same system that hosts their virtual machines. If you’re using a SAN, you probably have a disk witness. If you’re running from a SOFS or an SMB 3-capable NAS, you probably have a share witness. There is a strong relationship between the health of the cluster and the health of its storage, so that makes perfect sense. However, it’s not ideal for clusters on disjointed networks and geographically distributed (stretched) clusters. Administrators of simpler clusters might wish for another option as well.
The Azure Cloud Witness feature allows you to connect your failover clusters to your Azure account and use it for quorum witness instead of anything hosted at any of your sites:
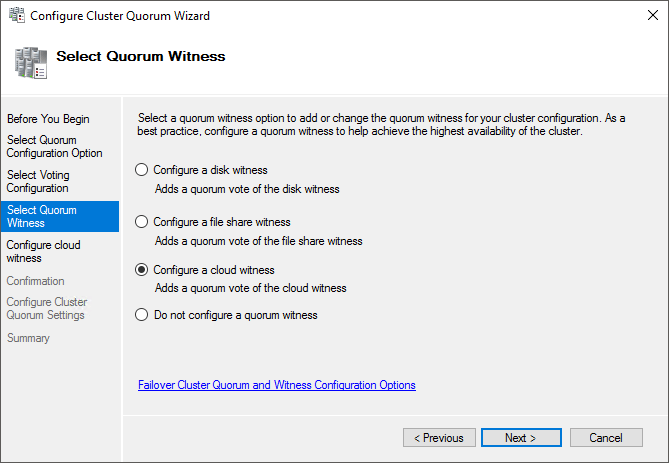
Cloud Witness
The description in the screenshot labels it as a “cloud witness”, but that’s an overly generous description. The next screen makes it very clear that you will not be connecting to any cloud service except Azure. I have not attempted to use this feature myself, but I’ve heard that it doesn’t use enough storage or generate enough traffic to reach billable levels. Even if that turns out to not be universally true, it should never cost more than a few pennies per month.
Site-Aware Clusters
Azure Witness isn’t the only feature that boosts geographically distributed clusters. 2016 grants you the ability to logically break a cluster into multiple fault domains. If you’ve never heard that term before, it means that you are partitioning a service so that a failure in one fault domain should not cause issues in other domains. I’m not entirely certain that Microsoft’s usage of that term in this context is entirely correct, but it’s close enough to get the point across.
The initial configuration is simple. First, create the fault domains. The intent is that you’ll separate fault domains by site, such as “Chicago” and “Cleveland”, but you can certainly follow any segregation method that makes sense for your architecture. After that, assign the cluster nodes to their respective fault domains. That’s all that’s required.
When a standard failover event occurs, such as a blue-screened node or an administratively drained node, failover clustering will attempt to keep all of the failing virtual machines within the same fault domain. The cluster will also attempt to keep virtual machines within the same site as the CSV that contains them.
There are two additional configurable components of this feature. You can reduce the frequency of inter-site heartbeat messages and how long a site is unreachable before a response. You can also configure “preferred sites”. The cluster will affinitize clustered roles toward this site. You can have a preferred site for the cluster, but you can also set them for cluster groups. For us Hyper-V types, the resources that belong to a virtual machine are a cluster group. So, essentially, you can instruct a virtual machine to attempt to restrict itself to a single site.
For more details on site-aware clusters and configuration instructions, head over to the Clustering and High Availability blog.
Workgroup and Multi-Domain Clusters
2016 allows you to create clusters that have no domain membership. Live Migration doesn’t work, but most other features do. I wouldn’t expect to see many advancements in this feature set for Hyper-V. The designers had SQL Server in mind when building this up. They just threw a bone to some other roles, including Hyper-V virtual machines.
If you’d like more information, there’s an article about it on the Clustering and High Availability blog.
Delayed Response to Failures
Existing failover mechanisms trigger on catastrophic failures. However, minor mishaps are often mistaken for major misfortunes. Loss of connectivity to storage might cause a system to blue screen, even if the logical pathway is rerouted over different physical connections within milliseconds. A momentarily overloaded network relay can trigger a failover of an entire node.
New in failover clustering for 2016 is the ability to ignore these conditions for a brief amount of time. Microsoft’s official documentation refers to this as “storage resiliency” and “compute resiliency”. Again, these terms are slightly skewed from dictionary definitions of their constituent words. For instance, the storage isn’t being resilient; the virtual machines that live on it are just tolerating the fact that it is briefly unavailable. “Fault tolerance” is a more apt description, but that already has a different accepted meaning. Perhaps we should call them “fault stubbornness.” Let’s look at how they work.
Storage Resilience
Windows does not like to lose its storage. Growing from roots in a “Disk Operating System” can have that effect. Typically, it will hang for a few brief moments and then hard stop with a blue screen event. That’s catastrophic for a physical operating instance. You don’t need a lot of imagination to understand the problem for multiple virtual machines running from the same storage platform.
We’ve had some fairly effective ways to keep virtual machines from crashing during brief outages:
- Configure iSCSI timers on hosts and any guests that connect directly to iSCSI targets: https://blogs.msdn.microsoft.com/san/2008/07/27/microsoft-iscsi-software-initiator-and-isns-server-timers-quick-reference/. Some recommendations for use within failover clusters can be found on the initiator download page: https://technet.microsoft.com/en-us/library/dd904411(v=ws.10).aspx. These are older documents, but still applicable.
- Set the global disk timeout value with the first entry on the following page: https://technet.microsoft.com/en-us/library/dd904411(v=ws.10).aspx. Note that I said “global”. This setting impacts all the drives on a system, not just its remotely-attached storage. Using a high value can cause severe problems if local storage is sick.
- We spoke about Redirected Access above.
The first two in that list are the oldest. They wait for storage to respond within the defined time window; if it doesn’t, Windows assumes that it’s gone and takes it offline. If it’s the system disk, Windows blue screens. If that storage is hosting a virtual machine, the virtual machine crashes.
The new “storage resilience” feature combines a pre-existing capability with a new timeout setting. If you’ve ever had any virtual machine’s containing storage space fill up, then you’ve encountered a paused virtual machine before. Hyper-V halts its entire compute profile — CPU, memory, I/O — and waits for some space on the container to free up. The virtual machine is not in a saved state, because the host freezes its state in memory, not on disk. Now, with “storage resiliency”, the same thing happens when a node loses connectivity to storage. If the loss of connectivity exceeds the timeout value, then the virtual machine crashes just as it would have in previous versions.
You can configure the storage resiliency timeout value according to the directions in this article: https://blogs.technet.microsoft.com/virtualization/2015/09/08/virtual-machine-storage-resiliency-in-windows-server-2016/.
Compute Resilience
The “compute resilience” feature addresses network outages and cluster node isolation. A network drop doesn’t have any direct impact on a virtual machine’s ability to function, but it will cause its containing node to start a failover. The goal of “compute resilience” is keeping virtual machines on their owning node long enough to be sure that the network failure isn’t short-lived. There are many related considerations and settings. Read about them on the related Clustering and High Availability blog article: https://blogs.msdn.microsoft.com/clustering/2015/06/03/virtual-machine-compute-resiliency-in-windows-server-2016/.
Virtual Machine Start Order
When we build clusters, we envision “always on” holistic units, with only a minority of nodes ever offline at any given time. Every once in a while, you’ll lose a few nodes too many. Sometimes, they’ll all be offline. You’ll step in and do your duty, and then all of those guests are going to start coming back online. In versions past, that was fairly chaotic. Your only control mechanism was virtual machine start delays, but each node’s startup routine individually sets the root time for the virtual machines that it owns. There’s almost zero chance that all of the nodes will start at precisely the same time.
The new virtual machine start order feature in 2016 allows you to centralize start priority at the cluster level. Adrian Costea has already written a fantastic article explaining the feature in detail and providing instructions on its usage: https://www.altaro.com/hyper-v/configure-start-order-priority-clustered-vms/.
Clustering Virtual Machines Has Never Been a Better Choice
I know that a lot of people are holding tight to their single-host virtual machine silos. I’ve worked with enough very small organizations that I won’t pretend that a cluster is always the best choice. However, the software feature sets continue to improve while the hardware costs continue to decline. You can now build a reasonably capable cluster for the same amount of money as you would have spent for a moderate pair of separate hosts in 2005, and that’s without accounting for inflation. If you’ve been thinking about it, now is the time.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


4 thoughts on "High Availability Enhancements for Hyper-V 2016"
Nice Article!
I did not know about the Storage Resilience options available in Windows.
Hi Eric. I made a two-node SDS Cluster (2x HPE DL380G9,17xHDD,5XSSD). 2x 6TB Volumes. Failover Vaildation says all ok.
Problem when I shut down one Node volume c:clusterstorage disappear.
When both Nodes are online I see CSV in Diskmanage only on one node same time. should CSV not always show in both Nodes? I am not sure I can trust in SDS.
Thanks for any advices. Stefano
Are you talking about Storage Spaces Direct? I don’t have any meaningful experience with that yet. But I don’t think that you’re supposed to put a CSV on an S2D. I think you just use the pool directly.