Save to My DOJO
In this second post, we will review the different types of replication options and give you guidance on what you need to ask your storage vendor if you are considering a third-party storage replication solution.
If you want to set up a resilient disaster recovery (DR) solution for Windows Server and Hyper-V, you’ll need to understand how to configure a multi-site cluster as this also provides you with local high-availability. In the first post in this series, you learned about the best practices for planning the location, node count, quorum configuration and hardware setup. The next critical decision you have to make is how to maintain identical copies of your data at both sites, so that the same information is available to your applications, VMs, and users.
Multi-Site Cluster Storage Planning
All Windows Server Failover Clusters require some type of shared storage to allow an application to run on any host and access the same data. Multi-site clusters behave the same way, but they require multiple independent storage arrays at each site, with the data replicated between them. The data for the clustered application or virtual machine (VM) on each site should use its own local storage array, or it could have significant latency if each disk IO operation had to go to the other location.
If you are running Hyper-V VMs on your multi-site cluster, you may wish to use Cluster Shared Volumes (CSV) disks. This type of clustered storage configuration is optimized for Hyper-V and allows multiple virtual hard disks (VHDs) to reside on the same disk while allowing the VMs to run on different nodes. The challenge when using CSV in a multi-site cluster is that the VMs must make sure that they are always writing to their disk in their site, and not the replicated copy. Most storage providers offer CSV-aware solutions, and you must make sure that they explicitly support multi-site clustering scenarios. Often the vendors will force writes at the primary site by making the CSV disk at the second site read-only, to ensure that the correct disks are always being used.
Understanding Synchronous and Asynchronous Replication
As you progress in planning your multi-site cluster you will have to select how your data is copied between sites, either synchronously or asynchronously. With asynchronous replication, the application will write to the clustered disk at the primary site, then at regular intervals, the changes will be copied to the disk at the secondary site. This usually happens every few minutes or hours, but if a site fails between replication cycles, then any data from the primary site which has not yet been copied to the secondary site will be lost. This is the recommended configuration for applications that can sustain some amount of data loss, and this generally does not impose any restrictions on the distance between sites. The following image shows the asynchronous replication cycle.
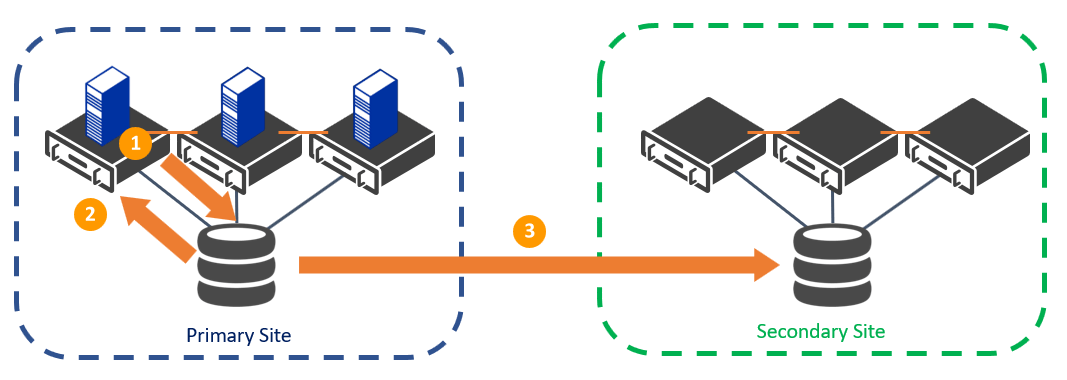
Asynchronous Replication in a Multi-Site Cluster
With synchronous replication, whenever a disk write command occurs on the primary site, it is then copied to the secondary site, and an acknowledgment is returned to both the primary and secondary storage arrays before that write is committed. Synchronous replication ensures consistency between both sites and avoids data loss in the event that there is a crash between a replication cycle. The challenge of writing to two sets of disks in different locations is that the physical distance between sites must be close or it can affect the performance of the application. Even with a high-bandwidth and low-latency connection, synchronous replication is usually recommended only for critical applications that cannot sustain any data loss, and this should be considered with the location of your secondary site. The following image shows the asynchronous replication cycle.
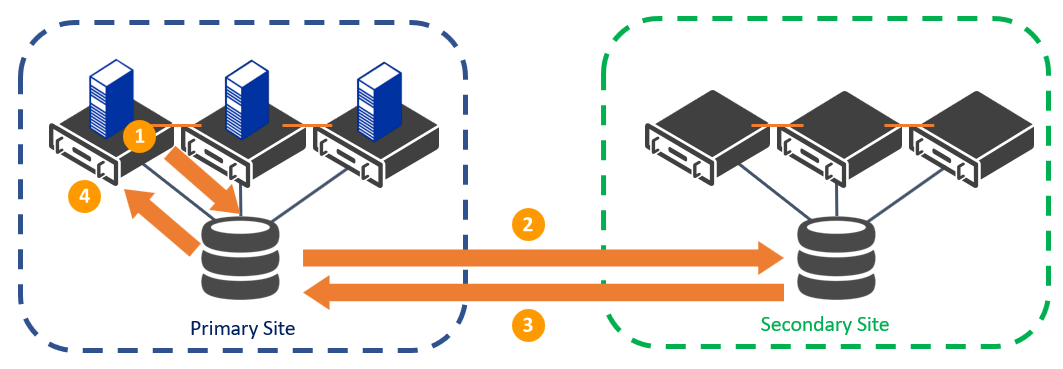
Synchronous Replication in a Multi-Site Cluster
Block-Level, File-Level or Appliance-Level Replication
As you continue to evaluate different storage vendors, you may also want to assess the granularity of their replication solution. Most of the traditional storage vendors will replicate data at the block-level, which means that they track specific segments of data on the disk which have changed since the last replication. This is usually fast and works well with larger files (like virtual hard disks or databases), as only blocks that have changed need to be copied to the secondary site. Some examples of integrated block-level solutions include HP’s Cluster Extension, Dell/EMC’s Cluster Enabler (SRDF/CE for DMX, RecoverPoint for CLARiiON), Hitachi’s Storage Cluster (HSC), NetApp’s MetroCluster, and IBM’s Storage System.
There are also some storage vendors which provide a file-based replication solution that can run on top of commodity storage hardware. These providers will keep track of individual files which have changed, and only copy those. They are often less efficient than the block-level replication solutions as larger chunks of data (full files) must be copied, however, the total cost of ownership can be much less. A few of the top file-level vendors who support multi-site clusters include Symantec’s Storage Foundation High Availability, Sanbolic’s Melio, SIOS’s Datakeeper Cluster Edition, and Vision Solutions’ Double-Take Availability.
The final class of replication providers will abstract the underlying sets of storage arrays at each site. This software manages disk access and redirection to the correct location. The more popular solutions include EMC’s VPLEX, FalconStor’s Continuous Data Protector and DataCore’s SANsymphony. Almost all of the block-level, file-level, and appliance-level providers are compatible with CSV disks, but it is best to check that they support the latest version of Windows Server if you are planning a fresh deployment.
Multi-Site Cluster Backup
By now you should have a good understanding of how you plan to configure your multi-site cluster and your replication requirements. Now you can plan your backup and recovery process. Even though the application’s data is being copied to the secondary site, which is similar to a backup, it does not replace the real thing. This is because if the VM (VHD) on one site becomes corrupted, that same error is likely going to be copied to the secondary site. You should still regularly back up any production workloads running at either site. This means that you need to deploy your cluster-aware backup software and agents in both locations and ensure that they are regularly taking backups. The backups should also be stored independently at both sites so that they can be recovered from either location if one datacenter becomes unavailable. Testing recovery from both sites is strongly recommended. Altaro’s Hyper-V Backup is a great solution for multi-site clusters and is CSV-aware, ensuring that your disaster recovery solution is resilient to all types of disasters.
If you are looking for a more affordable multi-site cluster replication solution, only have a single datacenter, or your storage provider does not support these scenarios, Microsoft offers a few solutions. This includes Hyper-V Replica and Azure Site Recovery, and we’ll explore these disaster recovery options and how they integrate with Windows Server Failover Clustering in the third part of this blog series.
Let us know if you have any questions in the comments form below!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Symon Perriman


1 thoughts on "How to Use Failover Clusters with 3rd Party Replication"
Thank you very much for your article they help me as much with altaro software than they do with understanding the way some infrasturcture work.