Save to My DOJO

Table of contents
Downtime is inevitable for most enterprise services, whether for maintenance, patching, a malicious attack, a mistake, or a natural disaster. No matter the cause, you will need to recover your services as quickly as possible (RTO) while minimizing any data loss (RPO). The most common reasons for extended downtime during a VM failover are unsuccessful failure detection, poor testing, and a dependence on people.
This blog post will give you the best practices for how to configure your datacenter and applications to failover and restart as quickly as possible. However, in order to follow many of these recommendations, we will assume that you are running a highly-virtualized datacenter. Our examples will use Windows Server Hyper-V; however, these best practices are also applicable to VMware environments.
Note that we’ll be covering failover priorities from quickest recovery to least.
Automatic Monitoring and Restarting Before VM Failover
In modern datacenters, we rely on monitoring tools to let us know when there is an issue to reduce the burden on staff, so automated alerting is critical. As soon as a service goes offline, your management tools should detect that it is unavailable, log the error, notify the administrator, and automatically try to restart the service or virtual machine (VM) on that same host. Resuming a VM on the same host is fastest as resources will already have been assigned to it. Whereas a remote failover would require a remount of a disk and allocation of memory and CPU.
Local VM Failover First
Deploy a highly-available host cluster for your virtual machines so that if the application cannot start on the original host, it can still failover and restart on a different server in the same local cluster. While this process will take longer than restarting it on the same node, it provides a great level of resiliency and reduces service downtime.
Failover clusters usually have configurable settings that can adjust how quickly a failure is detected. This setting is based on an intra-cluster health check between the nodes. These settings include the frequency that a health check is run (SameSubnetDelay and CrossSubnetDelay) and how many missed health checks can occur before failover is triggered (SameSubnetThreshold and CrossSubnetThreshold). When a failure is detected, the virtual machine will move to a different node and restart from the last valid configuration saved to its shared storage.
Replicate to a Disaster Recovery Site to Enable VM Failover
This is the stage of DR and failover that many organizations take for granted sadly,
If you have tried local failover, but the entire datacenter is offline, then you need to restore your services at a second site using a disaster recovery procedure. If your organization does not have an alternative location, there are disaster recovery solutions that can use the Microsoft Azure public cloud, so many of these best practices can still be followed.
Assuming that your services need to use some type of centralized database, it is important to remember that this information needs to be available and replicated between both sites. This means that the distance between the datacenters will affect latency, copy speed, health checks, and failover time. This distance could also influence whether you are using synchronous or asynchronous replication as synchronous solutions usually limit the maximum distance between sites.
Replication could happen between storage targets at the block level or at the file level taking advantage of built-in features like Hyper-V Replica or third-party solutions that enable failover such as Altaro VM Backup. The sooner the data is available at the second site, the quicker a service can come online after a failover. Also note, that if you’re using a cross-site failover cluster be sure to consider the frequency (*SubnetDelay) and failure tolerance (*SubnetThreshold) of your health checks as you do not want to trigger a false failover because of bandwidth issues if the sites are too far apart and cannot communicate effectively.
Retain the IP Address after VM Failover If Possible
Often the most difficult part of failover. That is getting your users connected to the workload again once it’s running in the failover location. It’s best to retain the same IP. Let’s discuss why briefly.
When a VM fails over to a different host, it is recommended to keep the same IP address so that once its applications come online the end-users can immediately connect to it without reconfiguration of endpoints. This means that the application or VM should use the same subnet across all hosts so that the same IP address can be used. This is relatively easy when the cluster is in a single location, but this becomes complex if there are multiple sites.
The most common ways to keep a static IP address on the same subnet after a cross-site failover are to stretch a virtual LAN (VLAN) across sites or to use network virtualization to abstract the physical networks of both sites.
A simple diagram showcasing this idea can be seen below:
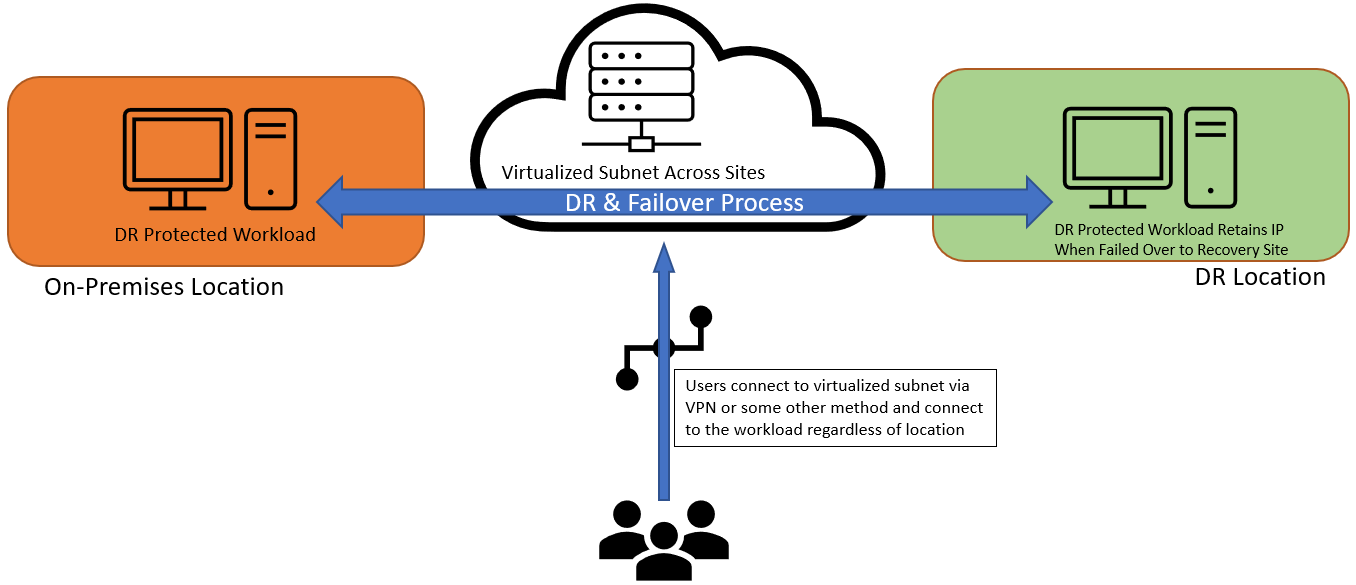
Optimize Client Reconnection Speed During VM Failover with Different IPs
If you have to change the IP address after the failover, there are a few ways to speed up the time it takes for the client to receive the new IP address, then reconnect to the VM. If you are using DHCP, then the application will likely get a new and random IP address. You can edit the HostRecordTTL cluster property of the workload to change the application’s DNS setting by reducing its Time To Live (TTL). This controls how quickly the DNS record expires, which forces the client to request a new record with the new IP address so they can try to reconnect. Most Windows Server applications have a default HostRecordTTL of 1200 seconds (20 minutes), which means that after a cross-subnet failover, it can take up to 20 minutes for the end-user to get an updated DNS record and reconnect to their application. Most critical applications will recommend TTL values of 5 minutes or shorter.
If you are using known static IP addresses at both sites then you can configure the application or VM to try to connect with either IP address. By setting the cluster property RegisterAllProvidersIP to TRUE, every IP address that DNS has used for that resource will be presented to the client who should automatically try to connect to them, iterating through the list. The IP address must have been previously registered in DNS by that workload, which means that the application must be failed over and brought online on each subnet during deployment or testing. Not all clustered workloads support the RegisterAllProvidersIP property, so verify that it can be used for your application.
Always Take Backups
Even if you have decided to replicate your data between sites, it is essential that you still regularly take backups and test the recovery process. Backup providers usually offer a broader feature set than replication and are more resilient to different types of failures. Since backups are usually stored offline, they prevent “bad” data from being replicated from the primary VM to the replica.
For example, if a virtual machine is infected with a virus or becomes corrupt, replicating it to a second site simply means that this “bad” data now exists in both locations. In this case, a healthy backup must be used in order to properly recover. So in addition to optimizing your backup recovery process, make sure that you have accessible backups at both your primary site and your disaster recovery site. Remember that backups will generally take longer to recover after a crash as the file needs to be located, mounted, restored, and tested before a service can come online. As a rule, backup restorations do take longer than a DR failover, so plan accordingly in this situation.
In Summary
When a disaster strikes, ensure that you are ready to bring your services online as fast as possible by optimizing your hardware and software as we’ve discussed above.
- By automatically monitoring VM failover within a cluster, you can bring your local services online faster.
- To prevent the loss of an entire datacenter, configuring a disaster recovery site (or use the public cloud) for replication.
- Ideally, retain the IP address after failover and help your clients reconnect quicker.
- When all else fails, make sure you have a complete backup solution for both sites.
- Most importantly, make sure that you regularly test your processes and train your staff in these best practices.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Symon Perriman

