Save to My DOJO
Table of contents
- What are Hyper-V Checkpoints?
- How Can I Use Hyper-V Checkpoints as Backups?
- How are the Apply, Delete, and Revert Checkpoints Functions Used?
- What is the Difference Between Standard and Production Hyper-V Checkpoints?
- When Should I Use Checkpoints?
- Should I Use Standard or Production Checkpoints?
- Use Cases for Production Checkpoints
- Are There Any Situations in Which All Checkpoints Should be Avoided?
- How Do I Configure Checkpoints in Hyper-V 2016?
- Classification Confusion for Checkpoints in 2016
Checkpoints are one of the oldest features found in almost all hypervisors. Despite its ubiquity, there is a lot of confusion around this technology. What is it? When is it appropriate to use it? Where should it not be used? Why do so many people say not to use it? The 2016 release of Hyper-V muddied the waters further by adding a new type of checkpoint, oddly called “production checkpoints”, even though they are no more or less suited to production environments than the “standard” checkpoint. They do add a greater range of valid use cases to the checkpoint mechanism, though. To use checkpoints appropriately, you need to understand them.
What are Hyper-V Checkpoints?
A Hyper-V checkpoint is an unchanging point in the lifespan of a virtual machine. The virtual machine can still be used as normal, but the checkpoint is protected from any changes that are made to the virtual machine. Such “changes” are generally understood to refer to data within attached virtual hard disks. That’s only part of the story. No change to the virtual machine affects the checkpoint; it is also isolated from dis/connection of virtual hard disks, network topology changes, memory re-assignments, and almost anything else about a virtual machine that can be modified.
The checkpointing process is straightforward, but the results are somewhat contradictory and therefore confusing. The following is a generic description that applies to both standard and production checkpoints with the differentiating details left out.
- The checkpointing service creates copies of the virtual machine’s configuration files and places them in the in the virtual machine’s configured Checkpoint File Location.
- The checkpointing service creates a differencing disk for every VHD[X] file connected to the virtual machine. These differencing disks are always placed in the same folder as their parent VHD[X] files.
- Checkpoint creation ignores pass-through disks entirely.
- The virtual machine continues to operate from the original configuration files, and continues reading unchanged data from the original VHD[X] file(s).
That part seems simple enough. The confusion arises from the way that Hyper-V treats these files for changes.
- Hyper-V assigns changes for the virtual machine configuration to its original configuration files (that would be the XML in versions 2012 R2 and earlier and a VMCX in 2016). Hyper-V will not make any changes to the copies of the configuration files that the checkpointing service created in step 1 above.
- Hyper-V writes changes for data in the virtual machine’s attached virtual hard disks to the AVHD[X] file(s). Hyper-V will not make any changes to the original VHD[X] file(s).
- Hyper-V writes changes for data in pass-through disks directly to the pass-through disks.
It’s important to understand all of this, because I see a great deal of confusion around checkpointing behavior. People are copying out and tinkering with the AVHD[X] files thinking that they are somehow manipulating the checkpoint. In truth, they are working with the active virtual machine. We often use terminology like “the AVHDX files that belong to this checkpoint…” when in truth, the checkpoint does not have anything to with AVHDX files (a checkpoint at a nested layer in a checkpoint tree does, but for now let’s just think about a virtual machine with a single checkpoint).
Let’s look at a visualization of a virtual machine with a checkpoint:
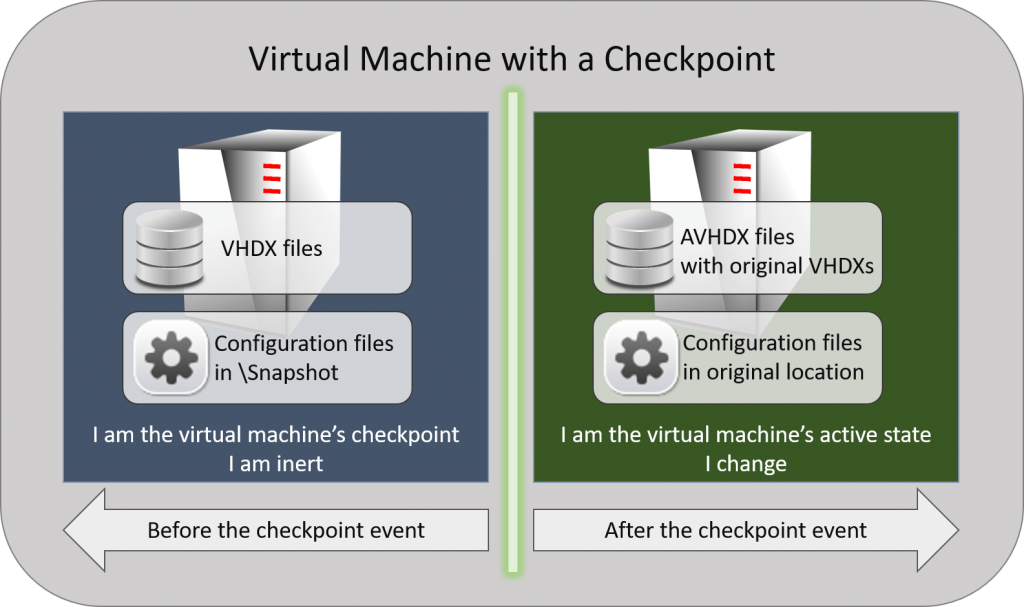
Checkpoint Illustration
If you plan to do anything with the files, then it is critical that you understand what part of the virtual machine’s states own each file. If you aren’t planning to take it to that level, then the most important thing to understand is that the virtual machine is the sum of all of these parts. The inert portion of the virtual machine can technically stand alone, but changing any part of it causes anything that happened in the active state to become invalid.
What about “Snapshots”? How Do They Relate to Checkpoints?
Most other hypervisors, including older versions of Hyper-V, call this technology “snapshots”. Virtual Server, the forerunner to Hyper-V, called them “Checkpoints. System Center Virtual Machine Manager has always used that terminology. To bring everything into synchronization, Microsoft has begun gradually shifting toward calling them “checkpoints”, but you will still see many references to “snapshots”. One obvious location is the folder where they’re kept.
There are other technologies called “snapshots”. Most notable is the Volume Shadow Copy Service (VSS) snapshot. That’s a very important part of the new Production Checkpoint, so we’ll expand on it in that section.
How Can I Use Hyper-V Checkpoints as Backups?
The short answer is: you cannot use Hyper-V checkpoints as backups. By definition, a backup is a duplication of data. Checkpoints do not duplicate data.
What you can do is export a checkpoint. This creates a duplicate of the data, and would therefore qualify as a backup. It’s not as efficient as using a dedicated backup application, but it will do if you haven’t got anything better.
However, checkpoint exports confuse many people. They have been told that AVHDX files belong to checkpoints. So, they naturally assume that exporting a checkpoint will capture all of the changed data in the AVHDX. Unfortunately, the premise is incorrect. The AVHDX does not belong to the checkpoint; it belongs to the active virtual machine. If you export the checkpoint, you get everything that happened up to the point that the checkpoint was taken, but nothing after. If you want an export of things that occurred after the checkpoint, then you need to either export the active state of the virtual machine or you take another checkpoint and export that. Hyper-V can export live virtual machines, so take advantage of that.
If you want only the changed data, then you’ll need to dig into the API. These changes are represented by raw data blocks, so you’re going to need some programming skills to make any use of them. I think, though, that most people just don’t really understand that these changes are not complete files.
The most important thing to take away from this section is that checkpoints are not backups.
How are the Apply, Delete, and Revert Checkpoints Functions Used?
After a checkpoint is created, there are three operations that you can use to manage it.
Apply a Checkpoint
The “Apply” operation is the most aptly named. When you “apply” a checkpoint, it becomes the active state of the virtual machine. When you use the GUI to apply a checkpoint, you are given an opportunity to capture the current active state in another checkpoint. If you decline, everything that occurred between the latest checkpoint and the active state of the virtual machine is permanently lost. We have written directions for checkpoint application in an earlier article.
Apply has two primary uses:
- You want to work with the virtual machine as it was when a particular checkpoint was taken. With this usage, you are encouraged to take another checkpoint when prompted.
- You do not like the current state of the virtual machine and would like to use a different state. With this usage, the encouragement to take another checkpoint is not as strong.
Depending on your situation, you might prefer the Revert operation.
Revert a Checkpoint
“Revert” is also an appropriate name, although it does not tell the entire story. “Revert” is exactly like “Apply” except:
- You cannot choose the checkpoint. Revert always applies the most recent checkpoint.
- You are not given an option to checkpoint the current state. It is permanently lost.
Revert has one use:
- You do not like the current state of the virtual machine and want to go back to the previous checkpoint.
When the immediately preceding checkpoint is where you want to be and you don’t care to keep the current state, Revert is superior to Apply.
Delete a Checkpoint
If you literally deleted a checkpoint, then it would destroy everything to the left of the dividing line in the visualization diagram above. Changed data would be orphaned and useless. However, it does literally delete the files in the Snapshot folder that represent any configuration differences, so the verb does retain some applicability. I would say that “merge” does a far better job of describing what happens when you “delete” a checkpoint. Data in the source VHDX and AVHDX files are combined back into the source VHDX files. No data is deleted. Only original virtual machine configuration information is lost in favor of the current configuration (ex. Dynamic Memory settings). We have written directions for deleting checkpoints in an earlier article.
What is the Difference Between Standard and Production Hyper-V Checkpoints?
Historically, virtual machines are mostly a black box from the hypervisor’s perspective. That means that the hypervisor knows something is going on in there because of all that CPU and memory and I/O activity, but it doesn’t really know what that “something” is. So, snapshots/checkpoints essentially freeze the virtual machine’s activity at a certain point in time… just like the photographic snapshot that they are named after. Anything that happens after the snapshot is not captured in the snapshot… just like the photographic snapshot that they are named after. Because the hypervisor doesn’t know what’s happening inside the virtual machine, it just locks these resources as they were at that time. This is a “standard” checkpoint.
The new, so-called “production” checkpoints rely on not-so-recent advances in hypervisor technology. Most, including Hyper-V, now have some technique for reaching into the “black box” and interacting with specially-designed components running inside. For Hyper-V, these are called “Integration Services” for Windows and “Integration Components” for Linux. One of those services is the Backup (volume shadow copy) service, which in turn interacts with the Volume Shadow Copy Service, which most of us know simply as “VSS”.
Many articles could (and have been) written about VSS. At its core, it is a gateway between backup applications and the operating system. VSS exists to address the fact that data can and does change while backups are being taken. We already have an article set that covers the terms and mechanisms related to VSS and backup. The most important thing to know about VSS is that it provides the ability for applications to cease all I/O and flush outstanding data and operations from memory to disk so that the backup doesn’t miss anything. The most important thing to know about VSS’s place in the universe is that not all applications take advantage of it. That is where we draw the distinction between “standard” and “production” checkpoints.
What are the Characteristics of Standard Checkpoints?
Start with the initial “What are Checkpoints” section. Everything there applies to standard checkpoints. Additionally, standard checkpoints capture:
- The active state of the virtual machine’s CPU activity
- The active state of the virtual machine’s memory
The short form definition of a standard checkpoint is: the virtual machine exactly as it was when the checkpoint was taken.
Let’s see it in action. Inside a virtual machine, I created a new text file on the desktop, opened it up in notepad, typed some text, and took a checkpoint without saving the file:
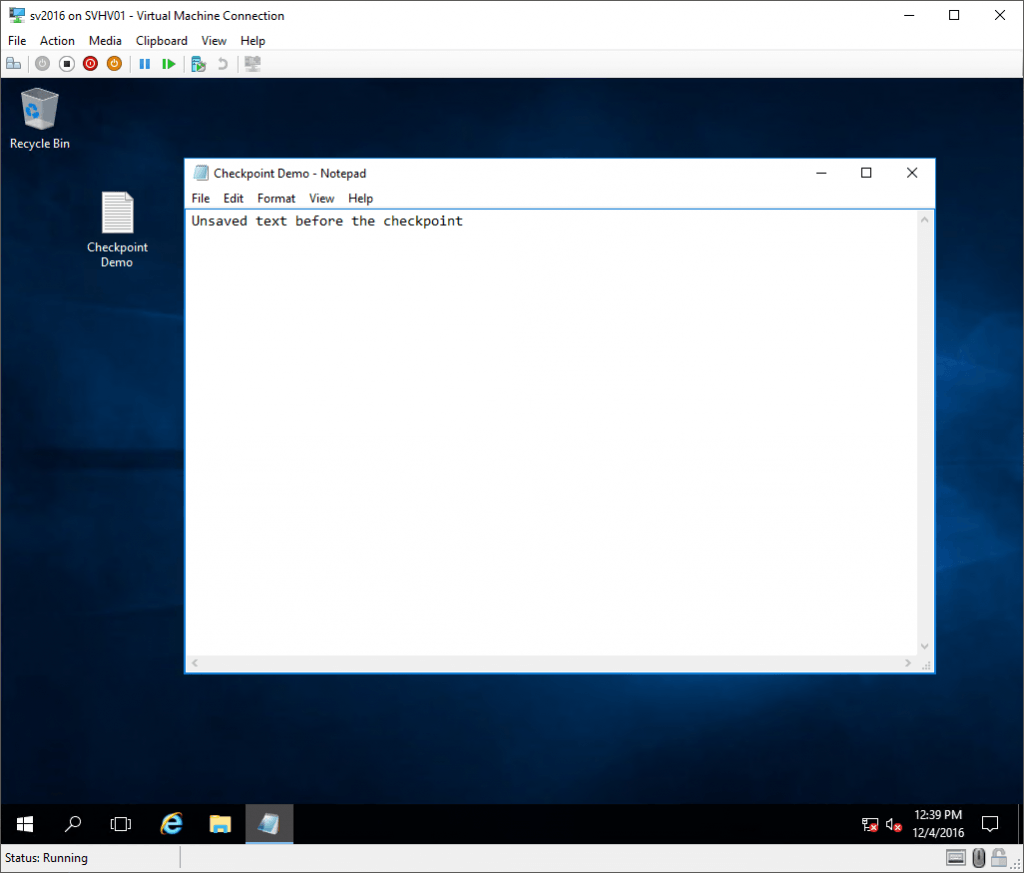
Unsaved Data Pre-Checkpoint
Next, I made some changes:
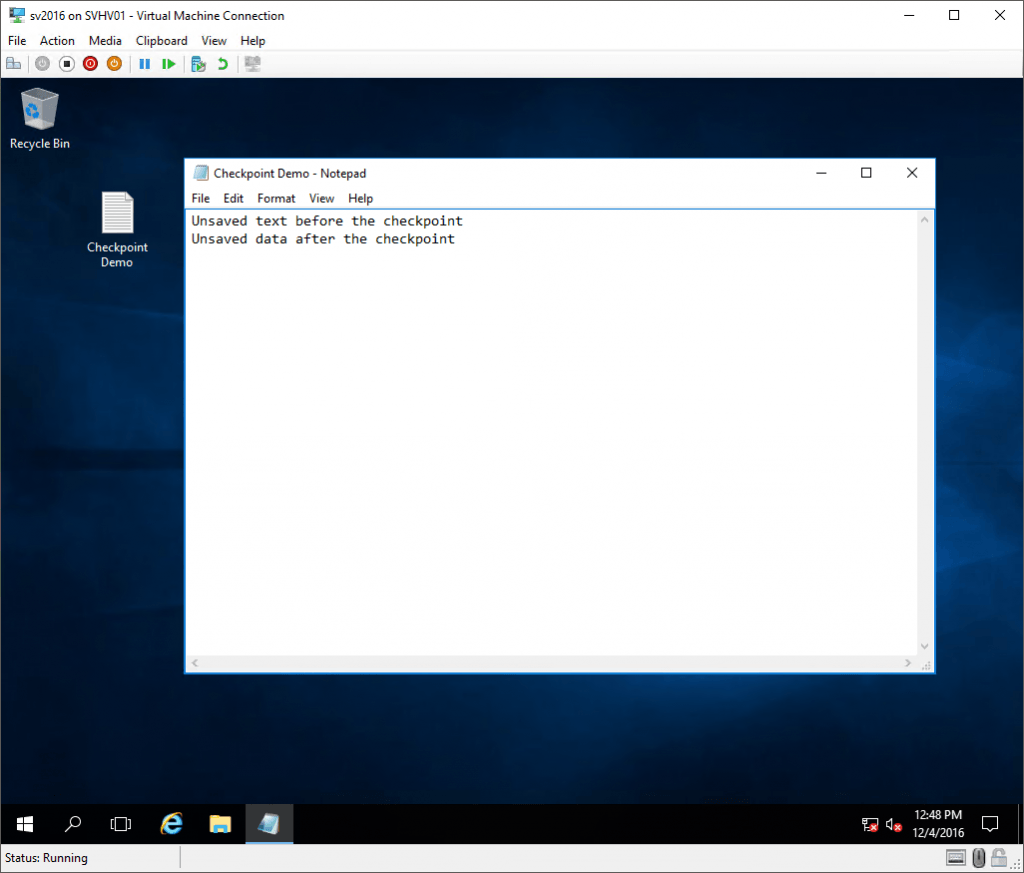
Post-Standard Checkpoint Changes
And then I reverted it (remember that this causes everything that I did after the checkpoint to be lost):
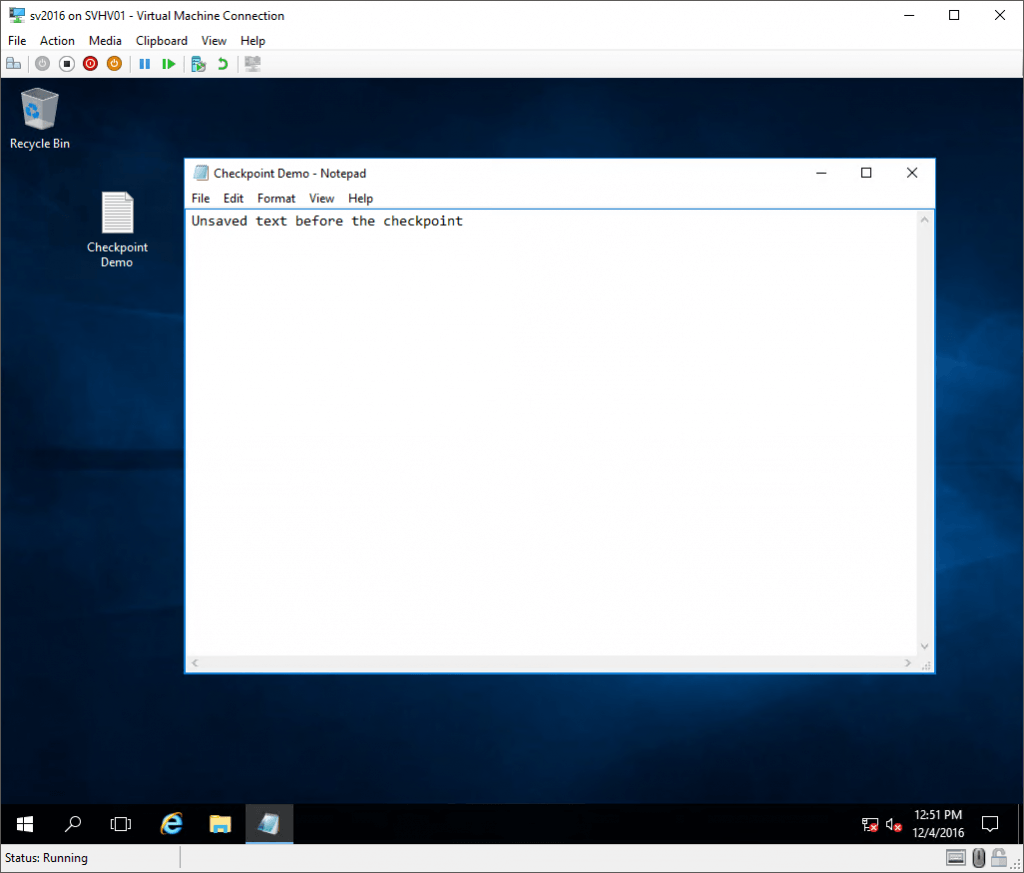
Reverted Standard Checkpoint
So, at this point, what of that Notepad content lives in the VM’s VHDX? Nothing, that’s what. I never saved anything. But, all of the text that was in the in-memory version of the document is still there because the state of memory was saved. The checkpoint represents the virtual machine as it was at the exact moment that the checkpoint was taken. Notepad doesn’t know that anything happened. The only thing anywhere in the virtual machine that realizes that anything is different is the time service. I do have the Time Synchronization service enabled, so the clock was updated immediately.
What are the Characteristics of Production Checkpoints?
Start with the initial “What are Checkpoints” section. Everything there applies to production checkpoints. Unlike standard checkpoints, production checkpoints do not capture anything else. Instead, they trigger VSS in the guest. Any application operating within that has registered a VSS writer will then carry out whatever operations the writer is designed to perform. For example, Microsoft Exchange will commit its logs to the store. Windows will also stop in-flight I/Os from occurring and flush file system queues.
What’s important to know is that active CPU operations and the memory state are not protected in any way.
To demonstrate, I’m going to continue with the same VM as in the Standard Checkpoint section above. I merged (“deleted”) that checkpoint. I set the virtual machine to use Production checkpoints, then took a checkpoint. Once that was done, I did the same thing that I did with the Standard checkpoint: I typed some data into the notepad file. Then, I reverted the checkpoint.
The first thing to notice is that, where a reverted standard checkpoint restores the exact state of the virtual machine, the virtual machine reverted to a Production checkpoint is off once the revert completes:
Reverted Production Checkpoint
After that, I powered on the virtual machine and opened the file that I had created on the desktop. This is what it looks like:
Data Lost After Reverting a Production Checkpoint
What happened to the data? First of all, I never saved it. Those words were only in memory. Second, Notepad.exe does not have a VSS writer. When the Production checkpoint triggered VSS, Notepad.exe didn’t know what to do, so it did nothing.
When Should I Use Checkpoints?
Checkpoints should be used for short-term protection during a planned event that might cause otherwise irreparable damage to a virtual machine. This is true for both Standard and Production checkpoints. Examples of valid usages for checkpoints:
- A not-particularly-trustworthy vendor wants to upgrade their application. You want to see that application functioning properly in your environment before you permanently commit.
- Microsoft/Windows Updates, especially on systems that have been seriously broken by previous updates.
- Systems used to test in-development applications that make system-level changes.
Whatever reason you have for using a checkpoint, they are for short-term usage only. I’ve heard of people allowing checkpoints to sit for as long as a year before deciding to do anything about it. Even if they can address the situation without problems, that’s not a good usage of the technology. Personally, I don’t like checkpoints to live for more than a few hours. I suppose a deeply layered upgrade process might warrant a checkpoint that lives for a day or two. I can’t give you a hard rule, but I can give you a solid rule of thumb: never allow a checkpoint to outlive its usefulness. What I mean is, for every checkpoint that you’ve got, ask yourself: “If I revert this checkpoint, would the state of the virtual machine be useful, or would I lose too much?” If it’s not useful, merge it now.
There are some people that say, “I never use checkpoints in production” (implying that you shouldn’t either) and justify it with a litany of excuses. Some of those excuses:
- “I heard about something bad happening to someone else.” — These are all terrible reasons.
- “Differencing disks can consume a lot of space, maybe so much that my virtual machine(s) would pause.” — There is truth in this. However, differencing disks (AVHDX) only grow as rapidly as changes are made to the VM’s data. If they don’t live long, they don’t grow to unmanageable sizes. Also, you should be monitoring your space usage anyway.
- “Differencing disks hurt performance.” — There is a performance impact involved with differencing disks, but it’s very overblown. Most people don’t use nearly as many IOPS as they think they do, for starters. Also, the performance impact is minimal unless you’re already near capacity or if you’re nesting checkpoints/differencing disks. This is a manageable concern and does not even come close to being a solid excuse to “never” use checkpoints. At most, it is a reminder to use checkpoints intelligently.
- “People forget to delete checkpoints.” — Competent administrators find a way to manage. I monitor mine with Nagios (you need to sign up in order to gain access to the Hyper-V checkpoint monitor). If that’s too much, set an Outlook reminder and/or task. Run Get-VMSnapshot occasionally. This excuse has zero validity.
Should I Use Standard or Production Checkpoints?
Do not allow the term “Production Checkpoint” to imply that Standard checkpoints cannot be used in production. Standard checkpoints have always been supported in production environments. There are some cases in which they will still be the preferred option.
Use Cases for Standard Checkpoints
I’m assuming that my Notepad demonstration is not indicative of normal server operations. However, there are a great many server-based applications that don’t respond to a VSS event. A Standard checkpoint is preferable to a Production checkpoint when all of the following are true about an application that you wish to protect in the virtual machine:
- The application is not VSS-aware.
- The application actively manipulates data in VHDX owned by the virtual machine OR performs in-memory operations that must not be lost if it can be avoided. This does not apply to in-memory operations against data on remote servers, because the state of data on a reverted virtual machine will not be synchronized to any remote server.
- The application is active (running) when the checkpoint is taken.
Examples of this type of application would be non-VSS-aware database and mail servers. I have worked with many vendors that use very old database technology (read as: the application vendors and their customers can avoid licensing fees for modern RDBMSs). These would best be served by standard checkpoints.
Use Cases for Production Checkpoints
Production checkpoints are generally best used any time that any one of the conditions that call for Standard checkpoints are not true. Let’s specify them outright. Choose Production checkpoints over Standard checkpoints when any of the conditions apply to the application that you want to protect:
- The application is VSS-aware
- The application is passive, operating in a read-only state, or serving data from a remote machine.
- The application is stopped
There are many obvious uses for Production checkpoints, so I’ll skip those. A Production checkpoint would be a good choice for something like an Apache web server that acts as a front-end for a remote SQL server. If reverted, the Apache web server will resume from an Off state, so it won’t attempt to continue any operations that were active when the checkpoint was taken. If you used a Standard checkpoint instead and a web user was trying to update a record, that could result in some data inconsistency.
Are There Any Situations in Which All Checkpoints Should be Avoided?
I clearly do not subscribe to the “never” philosophy of checkpoints. However, there are some applications whose virtual machines should never be checkpointed:
- Active Directory Domain Servers in a multiple domain controller environment. A Standard checkpoint of a domain controller in a multi-DC environment has the possibility of causing a USN rollback. Domain controllers running Windows Server 2012 or later should be immune, but USN rollbacks can be so devastating that the risk isn’t worth it. You should also technically be safe if using a Production checkpoint, but again, it’s probably not worth it. If your environment is complex enough to justify multiple domain controllers, then they should not be running anything that would justify using Hyper-V checkpoints at all. Environments with a single domain controller cannot encounter a USN rollback, but I still do not see a valid use case for checkpoints there, either.
- Cluster members. This restriction applies fairly equally to applications protected by Microsoft Failover Clusters and non-Microsoft clustering technologies. Checkpoints could cause the equivalent of USN rollbacks in those applications. When these applications synchronize to other members, those other members aren’t going to bother tracking the status of anything prior to that synchronization point. If you revert a member to a checkpoint, it won’t know what it doesn’t know, and the other members won’t understand why it doesn’t know. If you must checkpoint for some reason, stop the cluster and shut down all other members first. This has some exceptions when the cluster members are just front-ending for data and not keeping anything locally, but you must have a solid understanding of data flow in these applications.
- Applications with innate replication. I think we’re building a pattern here. If your application is doing something to synchronize local data with other applications on other servers, it’s not a good use for any checkpoints unless you ensure that a reversion does not negatively impact the other members or their data.
Production checkpoints can address some of these issues. When a virtual machine with a Production checkpoint is reverted, it is at least aware that something happened. That “something” is generally equivalent to being restored from a full backup. If you understand how your application will react in that case, then you understand how it will react to the application of a Production checkpoint.
One benefit for Production checkpoints is that they are smaller for running virtual machines than Standard checkpoints. Production virtual machines don’t need memory state, so they don’t save a copy of it. Standard checkpoints keep an on-disk copy of the exact state of the virtual machine’s memory at the moment of capture.
How Do I Configure Checkpoints in Hyper-V 2016?
The checkpoint configuration process has changed for this version. In previous versions, the only thing that you could change is where checkpoint files were placed. In 2016 (including Windows 10 Client Hyper-V), you can:
- Disable checkpoints for a virtual machine entirely.
- Choose between Standard or Production checkpoints.
- Allow a Standard checkpoint to be created when a Production checkpoint operation fails.
- Choose where to place a virtual machine’s checkpoint files (this only applies to the configuration and state information files; AVHD[X]s are always created in the same location as their VHD[X] parents.
By default, every virtual machine is enabled for Production checkpoints with the Standard fallback. To change these settings, open the virtual machine’s settings in Hyper-V Manager and switch to the Checkpoints tab:
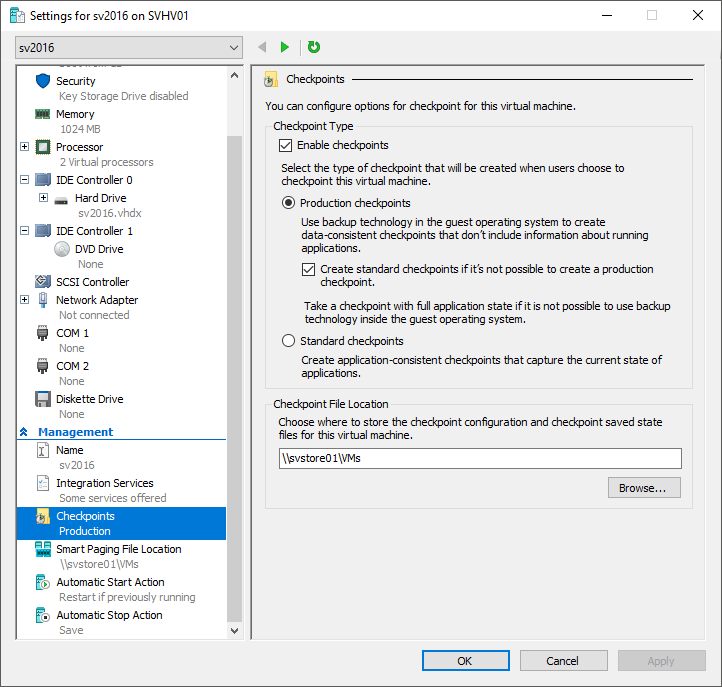
Checkpoint Settings in Hyper-V 2016
You can also use PowerShell, which is ideal for bulk operations. The cmdlet is Set-VM. The parameter selection for checkpoint type is, easily enough, -CheckpointType. It accepts values of Disabled, Standard, Production, and ProductionOnly. Use the SnapshotFileLocation parameter to tell it where it place the configuration and state information files.
Classification Confusion for Checkpoints in 2016
Get-VMSnapshot‘s output includes a SnapshotType field that you might think would help you to distinguish between a production checkpoint and a standard checkpoint. If you attempt to use it for that purpose, you’ll discover that it always indicates that a checkpoint is type “Standard”, even if it’s Production. This field is intended for use with Hyper-V Replica, not the new Production checkpoint type. I cannot find anywhere to externally determine whether a checkpoint is Production or Standard. I recommend that you name them at creation.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


20 thoughts on "Standard and Production Checkpoints in Hyper-V 2016"
Very well done article, especially for non-administrators like me.
Finally I do think to know the difference between “standard” and “production” checkpoints/snapshots and how they work.
THX a lot!
Eric,
You said to avoid snapshot usage on cluster members. But wouldn’t that imply, that any bigger Microsoft installation which most probably would run failover cluster manager and CSV on top of that with VHDXs residing there, would not be advised to use snapshots at all?
Sounds quite strange to me, but I probably just got it wrong…
Cheers
Juri
I need to reword some of that section, I think. I meant guest cluster members.
Huh, is there a reason why my previous comment was deleted????
Not deleted, just got shifted to the moderation queue. Not sure why, since you’re a regular. It’s approved now.
In your article you mention not using checkpoints on Domain controllers where there are more than one domain controller, I currently use the Altaro VM backup software and this I believe uses checkpoints, should I not be backing these up these domain controllers this way or is there something I should change on the Altaro backup?
That’s a great question and, in hindsight, probably something that I should have included in the article.
Products that utilize Hyper-V’s VSS writer (including Altaro VM Backup) are going to cause a special type of checkpoint to be created when taking backups. The purpose of that feature is to replace the VSS’s snapshot functionality with something that is better suited to Hyper-V. A backup checkpoint is neither a standard nor a production checkpoint, although it is most similar to the production checkpoint type. Its mechanisms will allow a safe capture of the state of your domain controllers. You don’t need to worry or change anything in your process at all.
Congratulations Eric, this is an amazing article.
I’m preparing for 2016 Server MCSA and time and time again I come across your articles. They provide so much insight into the technologies that I need to understand, so I just wanted to take a moment to thank you for your excellent contributions to the online knowledge pool.
Thanks for the feedback! Good luck on your exams!
You can run the following from CMD line and it will display any active checkpoints are Production or Standard (since Get-VMSnapshot does not detail this):
C:WindowsSystem32WindowsPowerShellv1.0powershell.exe -Command “(get-vm * | where-Object {$_.CheckpointType -ne ‘Disabled’ -and $_.ParentCheckpointName -ne $null} | fl VMName, CheckpointType)”
Excellent article – thanks very much for sharing.
Very useful, thank you