Save to My DOJO
Table of contents
- Included in this Article
- Not Included in this Article
- What is Nagios Core?
- Isn’t Nagios Core Difficult?
- What is NSClient++?
- Prerequisites for Installing Nagios and NSClient++
- Software Versions in this Document
- Downloading Nagios Core and Transferring it to the Target System
- Prepare CentOS for Nagios
- Install or Upgrade Nagios on CentOS
- Install or Upgrade Nagios Plugins on CentOS
- Security and the NRPE Plugin
- Connecting Apache to Nagios on CentOS
- Configuring Apache to Use Nagios as the Default Site
- Configure Nagios to Send E-mail on CentOS
- Nagios Is Installed!
- Installing NSClient++
- Configuring NSClient++ to Work with PowerShell
- That’s It!
- Controlling Nagios
- An Introduction to Nagios Configuration Files
- Nagios Objects and Their Uses
- Useful Nagios Objects Documentation
- Dealing with Problems Reported by Nagios
- Nagios Availability Reports
- User Management for Nagios
- Using Nagios to Monitor Hyper-V – The real fun stuff starts here!
Are you monitoring your systems yet? I’m fairly certain that I make a big deal about that every few articles, don’t I? Last year, I wrote an article showing how to install and configure Nagios on Ubuntu Server. I’ve learned a few things in the interim. I also realize that not everyone wants to use Ubuntu Server. So, I set out on a mission to deploy Nagios on another popular distribution: CentOS. I’m here to share the procedure with you. Follow along to learn how to create your own monitoring system with no out-of-pocket cost. If you’re new to CentOS Linux on Hyper-V we suggest you check out the post.
Included in this Article
This article is very long because I believe in detailed instructions that help the reader understand why they’re typing something. It looks much worse than it is. I’ll cover:
- A brief description of Nagios Core, the monitoring system
- A brief description of NSClient++, the agent that operates on Windows/Hyper-V Servers to enable monitoring
- Configuring a CentOS system to operate Nagios
- Acquiring and installing the Linux packages
- A discussion on the security of the NRPE plugin. Take time to skip down to this section and read it. The NSClient++/NRPE configuration that I will demonstrate in this article presents a real security concern. I believe that the risk is worthwhile and manageable, but you and/or your security team may disagree. Decide before you start this project, not halfway through.
- Acquiring and installing the Windows packages
- Configuring basic Nagios monitoring
- Nagios usage
Not Included in this Article
While comprehensive, this article isn’t entirely all-encompassing. I am going to get you started on configuring monitoring, but you’re going to need to do some tinkering and investigation on your own. Building an optimal Nagios system requires practice more than rote instruction and memorization.
I have designed several monitoring scripts specifically for Hyper-V and failover clusters. These can be found in our subscriber’s area. Currently, the list includes:
- Checking the free space of a Cluster Shared Volume
- Checking the status of a Cluster Shared Volume (Redirected Access, etc.)
- Checking the age of checkpoints
- Checking the expansion percentage of dynamically-expanding VHD/Xs
- Checking the health of a quorum witness
Since Nagios will alert you if any of these resources get into trouble, you can begin using those features without fear that they’ll break something while you’re not paying attention. Some of those monitors are shown in this grab of Nagios’ web interface:

Nagios Sample Data
What is Nagios Core?
Nagios Core is an open source software tool that can be used to monitor network-connected systems and devices. It processes data from sensors and separates the results into categories. By name, these categories are OK, Warning, and Critical. By default, Nagios Core sends a repeating e-mail when a sensor is in a persistent Warning or Critical state and a single “Recovery” e-mail when it has returned to the OK state.
Sensors collect data by “active” and/or “passive” checks. Nagios Core initiates active checks by periodically triggering plug-ins. Passive checks are when remote processes “call home” to the Nagios Core system to report status to a plug-in. The plug-in then delivers the sensor data to Nagios Core.
These plug-ins give Nagios Core its flexibility. Several plugins ship alongside Nagios Core. The Nagios community makes others available separately. Some are only included with the paid Nagios XI, which I will not cover. A plug-in is simply a Linux executable that collects information in accordance with its programming and returns data in a format that Nagios can parse.
Nagios Core provides multiple configurable options. One that we will be using is its web interface — a tiny snippet is shown in the screenshot above. This interface is not required, but grants you the ability to visually scan your environment from an overview level down to the individual sensor level. It also gives you other abilities, such as “Acknowledging” a Warning or Critical state and re-scheduling pending checks to make the next one occur very quickly(for testing) or much later (for repairs).
Isn’t Nagios Core Difficult?
Nagios Core has a reputation for being difficult to use, which I don’t think is appropriate. I believe that it got that reputation because you configure it with text files instead of in some flowery GUI. Nagios XI adds simpler configuration, but many will find that the cost jump from Core to XI makes editing text files more attractive.
Fortunately, the default installation include templates that not only show you exactly what you need to do, but also give you the ability to set things up via copy/paste and only a bit of typing. Personally, I found the learning curve to be very steep but also very short. Overall, I find Nagios Core much easier to use than the monitoring component of Microsoft’s full-blown Systems Center Operations Manager.
From here on out, I’m only going to use “Nagios” to mean “Nagios Core”.
What is NSClient++?
NSClient++ is a small service application that resides on Windows systems and interacts with a remote Nagios system. Since Nagios runs on Linux, it cannot perform a number of common Windows tasks. NSClient++ bridges the gap. Of its many features, we will be using it as a target for the “check_nt” and “check_nrpe” Nagios plug-ins. Upon receiving active check queries from these two plug-ins, it performs the requested checks and returns the data to those plug-ins.
Prerequisites for Installing Nagios and NSClient++
I’ve done my best to make this a one-stop experience. You’ll need to bring these things for an optimal experience:
- One installation of CentOS. You can use a virtual machine, with these guidelines:
- 2 vCPU, 512MB startup RAM, 256MB minimum RAM, 1GB maximum RAM, and a 40GB disk. Mine uses around 600MB of RAM in production, a negligible amount of CPU, and the VHDX has remained under 2GB.
- Assign a static IP or use a DHCP reservation. You will be configuring NSClient++ to restrict queries to that IP.
- If you only have one Hyper-V host, find some piece of hardware to use for Nagios. If you don’t have anything handy, check Goodwill or garage sales. You don’t want your monitoring system to be dependent on your only Hyper-V system.
- I recommend against clustering the virtual machine that holds your Nagios installation. The less it depends upon, the better. In a 2-node Hyper-V cluster, I configure one Nagios system on internal storage on one node and a second Nagios system on the second node that does nothing but monitor the first.
- Refer to my prior article if you need assistance installing CentOS. Includes instructions for running it in Hyper-V.
- Download NSClient++ for the Windows/Hyper-V Servers to monitor. If you only have a few systems, the MSI will be the easiest to work with. If you have many, you might want to get the ZIP for Robocopy distribution.
- Note: If using the ZIP, install the latest VC++ redistributable on target systems. Without the necessary DLLs, the NSClient service will not run and does not have the ability to throw any errors to explain why it won’t run.
- NRPE (Nagios Remote Plugin Executor). This will run on the Nagios system.
- WinSCP (optional). You can get by without WinSCP, but it makes Nagios administration much easier. See my previously linked article on CentOS for a WinSCP primer.
- PuTTY (optional). You could also get by without PuTTY, if you absolutely had to. I wouldn’t try it. The linked CentOS article includes a primer for PuTTY as well.
- Download Nagios Core and the Nagios plugins from nagios.org to your management computer. More detailed instructions follow.
Software Versions in this Document
This article was written using the following software versions:
- Nagios Core 4.3.1
- Nagios Plugins 2.2.1
- NSClient++ 0.5.0.62
- NRPE 3.1.0. For our purposes, a 2.x version would be fine as well because v3.x needs to downgrade its packets to talk to NSClient++ anyway.
Downloading Nagios Core and Transferring it to the Target System
Start on Nagios.org. I’ll give step-by-step instructions that worked for me. Seeing as how this is the Internet, things might be different by the time you read these words. Your goal is to download Nagios Core and the Nagios Plugins.
- From the Nagios home page, hover over Downloads at the top right of the menu. Click Nagios Core.
- You’ll be taken to the editions page. Under the Core column, click Download.
- If you want to fill in your information, go ahead. Otherwise, there’s a Skip to download link.
- You should now be looking at a table with the latest release and the release immediately prior. At the far right of the table are the download links. For reference, the version that I downloaded said nagios-4.3.1.tar.gz. Click the link to begin the download. Don’t close this window.
- After, or while, the main package is downloading, you can download the plugins. You can hover over Downloads and click Nagios Plugins, or you can scroll down on the main package download screen to Step 2 where you’ll find a link that takes you to the same page.
- You should now be looking at a similar table that has a single entry with the latest version of Nagios tools. The link is at the far right of this table; the one that I acquired was nagios-plugins-2.2.1.tar.gz. Download the current version.
- If you didn’t already download NRPE, do so now.
- Connect to your target system in WinSCP (or whatever other tool that you like) and transfer the files to your user’s home folder. I tend to create a Downloads folder (keep in mind that Linux is case-sensitive), but it doesn’t really matter if you create a folder or what you call it as long as you can navigate the system well enough to find the files.

Note: You could use the wget application to download directly to your CentOS system. I never download anything from the Internet directly to a server.
Prepare CentOS for Nagios
Nagios depends on a number of other packages in order for its installation and operation. These steps were tested on a standard deployment of CentOS, but should also work on a minimal build.
Download and install prerequisite packages:
sudo yum install -y deltarpm automake epel-release sudo yum install -y httpd php gcc glibc glibc-common gd gd-devel perl unzip gettext sudo yum install –y openssl-devel net-snmp net-snmp-utils perl-Net-SNMP bind-utils
Then, we’ll create a user for operating Nagios.
sudo useradd -m -s /bin/bash nagios sudo passwd nagios
Upon entering the passwd command, you’ll be asked to provide a password. I don’t want to tell you what to do, but you should probably keep note of it.
Next, we’ll create a security group responsible for managing Nagios and populate it with that new “nagios” user group and the account that Apache runs under.
sudo groupadd nagcmd sudo usermod -aG nagcmd nagios sudo usermod -aG nagcmd apache
Install or Upgrade Nagios on CentOS
Now we’re ready to compile and install Nagios.
First, you need to extract the files.
Note:I am not using sudo for the extraction! If you run the extraction with sudo, then you will always need to use sudo to manipulate the extracted files.
Note: I am using the directory structure and versions from my WinSCP screenshot earlier. If you placed your files elsewhere or have newer versions, this is an example instead of something you can copy/paste.
cd ~/Downloads tar xzf ./nagios-4.3.1.tar.gz
Execute the following to build and install Nagios.
Note: If upgrading, STOP after sudo make install or your config files will be renamed and replaced with the new defaults!
Note: Do not copy/paste this entire block at once. Run each line individually and watch for errors in the output.
cd ~/Downloads/nagios-4.3.1/ sudo ./configure --with-command-group=nagcmd sudo make all sudo make install sudo make install-init sudo make install-config sudo make install-commandmode sudo make install-webconf
Only if new install. Set Nagios to start automatically when the system starts.
sudo chkconfig --add nagios sudo chkconfig nagios on
Only if upgrading. Instruct CentOS to refresh its daemons and restart the newly replaced Nagios executable.
sudo systemctl daemon-reload sudo service nagios checkconfig sudo service nagios restart
Install or Upgrade Nagios Plugins on CentOS
The plugin installation process is similar to the Nagios installation process, but shorter and easier.
Unpack the files first. The same notes from the Nagios section are applicable.
cd ~/Downloads/ tar xzf nagios-plugins-2.2.1.tar.gz
Compile and install the plugins. The same notes from the Nagios section are applicable, especially the bit about taking this one line at a time.
cd ~/Downloads/nagios-plugins-2.2.1/ sudo ./configure --with-nagios-user=nagios --with-nagios-group=nagios --with-openssl sudo make all sudo make install
You’ve just installed several plugins for Nagios, most of which I’m not going to show you how to use. If you’d like to take a look, navigate to /usr/local/nagios/libexec:
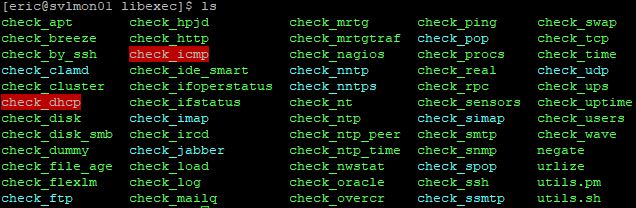
Most of them have built-in help that you can access with a -h or –help:
./check_nt --help
You can also search on the Internet for assistance and examples.
Security and the NRPE Plugin
The next step is to compile and install the NRPE plugin. Before that, we need to stop and have a serious chat about it.
You might read in some places that NRPE plugin is a security risk. That is correct. It allows one computer to tell another computer to run a script and return the results. Furthermore, we’re going to be sending arguments (essentially, parameters) to those scripts. Doing so opens the door to injection attacks. One method that has been used to combat the issue is NRPE traffic encryption. I am not going to be exploring how to encrypt NRPE communications at this time.
I have several reasons for this:
- The simplest reason is that it’s difficult to do and I’m not certain of how much value is in the effort.
- Encryption is often mistaken for data security when it is, in fact, more about data privacy. For example, if you transmit your password in encrypted format and the packet is intercepted, the attacker still has your password. The fact that it’s encrypted might be enough to put the attacker off, but any encryption can be broken with sufficient time and effort. Therefore, your password is only private in the sense that no casual observer will be able to see it. To keep it secure, you should not transmit it at all. We don’t really have that option. Because we are not encrypting, what an attacker could see is the command string and the result string. You’ll have full knowledge of what those are, so you can decide how serious that is to you. Our best approach is to ensure that the Nagios<->host communications chain only occurs on secured networks, even if we later enable SSL.
- The author of NSClient++ had the good sense to ensure that you can’t operate just any old free-form script via NRPE. Scripts must be specifically defined and can be tightly controlled. If the script itself is sufficiently well-designed, a script injection attack should be prohibitively difficult. That still leaves the door open to data snooping, so take care in what data your checks return.
- The author of NSClient++ also coded in the ability to restrict NRPE activities to specific source IP addresses. IP spoofing is possible, of course.
- Windows, Linux, and/or hardware firewalls can help enforce the source and destination IP communications. Spoofing is still a risk, of course.
- I ran a Wireshark trace on a Nagios-to-NSClient++ communications channel. Nothing was transmitted in clear text. There were changes made in NRPE 3.x that lead me to believe that it might be performing some encryption. Then again, it might just be Base64 encoding. Either way, no casual observer will be able to snoop it.
What I didn’t address in the above points is that NSClient++ could effectively authenticate the Nagios computer by only accepting traffic that was encrypted with its private key. So, yes, NRPE is a security risk and it is a higher risk without SSL. I won’t try to convince you otherwise.
I believe that, for internal systems, the risk is very manageable. If you’re going to be connecting to remote client sites, I would put the entire Nagios communications chain inside an encrypted VPN tunnel anyway because even if you encrypt NRPE, the other traffic is clear-text. The only people that I think should worry much about this are those that will be connecting Nagios to Hyper-V hosts using unsecured networks. Personally, I’m uncertain how a case could be made to do that even with SSL configured.
I’m not saying that I’ll never look into encrypting NRPE. Just not now, not in this article.
Install or Upgrade the NRPE Plugin on CentOS
For our purposes, the NRPE plugin requires little effort to install.
If you’re not already in the folder that contains the NRPE gzip file, return there. Unpack the file just like you did with the others.
cd ~/Downloads/ tar xzf nrpe-3.1.0.tar.gz
Switch to the extracted folder. Compile and install the plugin. Part of the configure process includes creating a new SSL key. It requires several minutes to complete.
cd ~/Downloads/nrpe-3.1.0 sudo ./configure sudo make check_nrpe sudo make install-plugin
Verify that the plugin was created:
ls /usr/local/nagios/libexec/check_nrpe
If CentOS responded by showing you a file, then all is well.
Connecting Apache to Nagios on CentOS
At this point, Nagios works and can begin monitoring systems. You’ll need to do some extra work to get the web interface going.
Start by creating an administrative web user account. This account belongs to Apache, not CentOS. As created in this article, it will have full access to everything in the web interface.
htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
You will be prompted to enter a password for the “nagiosadmin” account. Be aware that the -c parameter causes the file to be created anew. If it already exists, it will be overwritten.
You also need to add the CentOS account that Apache uses to the security group that can access Nagios’ files:
sudo usermod -aG nagcmd apache
Next, set Apache to start when the system boots:
chkconfig httpd on
Allow port 80 through the firewall:
sudo firewall-cmd --zone=public --add-port=80/tcp --permanent sudo firewall-cmd --reload
By default, the Security-Enhanced Linux module will prevent several of Nagios’ CGI modules from operating. If you want to quickly get around that, simply disable SELinux. Since we’re not hosting an online banking website or anything, I feel that this is an appropriate solution:
sudo setenforce 0 sudo nano /etc/selinux/config
When nano opens the config file, change the line that reads SELINUX=enforcing to SELINUX=disabled. Press [CTRL]+[X] when finished, then [Y] and [Enter] to exit. I tinkered with some of the other options and mostly managed to break my system. If you’re concerned, then this article might help you.
Apache on CentOS ships with a default page that we need to disable:
cd /etc/httpd/conf.d sudo mv welcome.conf welcome.conf.disabled
Start Apache:
service httpd start
Your Nagios installation can now be viewed at http://yourserver/nagios. If you want a quick test from the local command line:
curl "http://localhost/nagios" -u nagiosadmin
If you get a 301 or a lot of HTML with an embedded message that your browser doesn’t work, that’s a good sign.
Configuring Apache to Use Nagios as the Default Site
If you don’t want to hang /nagios off of URL requests to your system, follow these directions.
Open /etc/httpd/conf.d/nagios.conf in any text editor. It’s a fairly large file, so WinSCP or Notepad++ will make the chore simpler. From nano:
sudo /etc/httpd/conf.d/nagios.conf
Add the following lines, either at the beginning or the end of the file. I’ve highlighted two lines where you’ll want to substitute your system details for mine:
<VirtualHost *:80>
ServerName nagios.siron.int
ServerAlias nagios.siron.int
ServerName nagios
ServerAlias nagios
DocumentRoot /usr/local/nagios/share
ScriptAlias /nagios/cgi-bin "/usr/local/nagios/sbin"
ScriptAlias /cgi-bin "/usr/local/nagios/sbin"
Alias /nagios /usr/local/nagios/share
<Directory "/usr/local/nagios/sbin">
Options ExecCGI
AllowOverride None
Order allow,deny
Allow from all
AuthName "Nagios Access"
AuthType Basic
AuthUserFile /usr/local/nagios/etc/htpasswd.users
Require valid-user
</Directory>
<Directory "/usr/local/nagios/share">
Options None
AllowOverride None
Order allow,deny
Allow from all
AuthName "Nagios Access"
AuthType Basic
AuthUserFile /usr/local/nagios/etc/htpasswd.users
Require valid-user
</Directory>
</VirtualHost>
Restart Apache for the settings to take effect:
sudo service httpd restart
Your Nagios installation will now appear at http://yourserver, without the need to add /nagios. If you changed those first two lines and you add matching records to your internal DNS server, the system will also respond at the specified URL.
Configure Nagios to Send E-mail on CentOS
By default, Nagios will use the /usr/bin/mail executable to send e-mail. You need to configure Postfix for that to work. There are many ways that can be done, and I have neither the time nor the systems to test them all. Fortunately, a document already exists that can help you with the most common configurations. You can also find several how-tos from the postfix documentation page. I will show you how to get started and I’ll demonstrate the two methods that I know. For anything else, you’ll need to research on your own.
Initial Postfix Configuration on CentOS
It’s easy to get started:
sudo yum install -y mailx sudo chkconfig postfix sudo service postfix start
The basic e-mail infrastructure is now on your system.
Relaying Mail Through a Friendly Mail Server
If you’ve got a mail server that will allow anonymous e-mail via port 25 connections (like an Exchange server that allows local addresses), you have very little to do.
Open /etc/postfix/main.cf in a text editor. This is a large file and you’re going to be doing a lot of navigating, so choose your editor wisely. For nano:
sudo nano /etc/postfix/main.cf
Make these changes:
- Uncomment the #myhostname line (by removing the #). Change it to: myhostname = myserver.mydomain.mytld (Substituting your server and domain information). This is the host name that it will present to the mail server.
- Uncomment the #myorigin line. Change it to myorigin = mydomain.mytld (Substituting your domain information). E-mails sent by this server will append that domain to the user name.
- Uncomment one of the #inet_interfaces lines or add a new one. Change it to: inet_interfaces = loopback-only. This sets this server to not receive any inbound e-mail.
- After the #mydestination lines, add this: mydestination = . This will also prevent this server from accepting e-mail.
- Uncomment one of the #relayhost lines or add a new one in this format: relayhost = myrealmailserver.mydomain.mytld. Substitute the real name or IP address of the host that will relay e-mail for this server.
Restart postfix:
sudo service postfix restart
Relaying Mail Through Your ISP
Some of us don’t have our own mail server. If you’re paying for a static IP and have registered a domain name, then you could configure your new Postfix installation as a true mail server. But, most of us aren’t that lucky either. Instead, we can configure Postfix to log in to our ISP’s SMTP account and send e-mail as us. Credit to ProfitBricks.
Install the necessary security binaries:
sudo yum install -y cyrus-sasl-plain
Open /etc/postfix/main.cf in a text editor. This is a large file and you’re going to be doing a lot of navigating, so choose your editor wisely. For nano:
sudo nano /etc/postfix/main.cf
Make these changes:
- Uncomment the #myhostname line (by removing the #). Change it to: myhostname = myserver.mydomain.mytld (Substituting your server and domain information). This is the host name that it will present to the mail server.
- Uncomment one of the #relayhost lines or add a new one in this format: relayhost = smtpserver.yourisp.tld. Substitute the real name or IP address of your ISP according to their instructions for SMTP connections. If your ISP requires a different port (ex: Gmail), use brackets around the host name, a colon, and the port: relayhost = [smtp.gmail.com]:587.
- At the end of the file, add:
smtp_use_tls = yes smtp_sasl_auth_enable = yes smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd smtp_tls_CAfile = /etc/ssl/certs/ca-bundle.crt smtp_sasl_security_options = noanonymous smtp_sasl_tls_security_options = noanonymous
Create a file to hold the username and password to be used with your ISP’s mail server:
sudo nano /etc/postfix/sasl_passwd
Inside that file, you’re going to enter your information in this format: SMTP-server-exactly-as-entered-in-main.cf username:password. Two examples:
[smtp.live.com]:587 [email protected]:uselesspassword [smtp.gmail.com]:587 otherfakeuser:utterlyworthlesspassword
Generate a lookup table for Postfix to retrieve the passwords:
sudo postmap /etc/postfix/sasl_passwd
Restart postfix:
sudo service postfix restart
Remove the clear-text file containing your password:
sudo rm /etc/postfix/sasl_passwd
Nagios Is Installed!
You’ve completed all the functionality steps for the server! Walk through the web pages and check for any issues. I followed all of these same steps through and ended up with a fully functional system. If you’re having troubles, check that all of the prerequisite components installed successfully. If you have issues in one browser, try another.
You don’t have any sensors set up yet, so your displays will be very dull. We’ll rectify that in a bit. First, we need to talk about the Windows agent NSClient++.
Installing NSClient++
If you didn’t download NSClient++ before, do so now. NSClient++ has multiple deployment options. For your very first, I highly recommend one of the MSI installs. If you’ve got many systems, you might opt to grab a ZIP distribution as well. You can then mass-push pre-defined configurations via Robocopy, login scripts, or other means.
The installation screens:
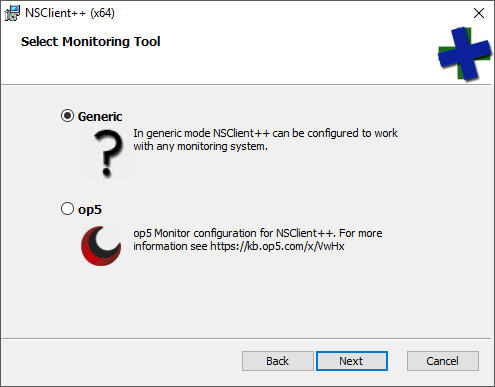
- I didn’t show the initial screen. The first that you care about asks you to select the Monitoring Tool. Choose Generic.
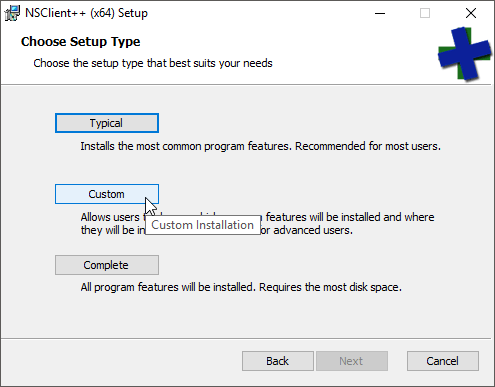
- Next, choose your installation type. I ordinarily pick Custom so that I can deselect the op5 options, but any will work.
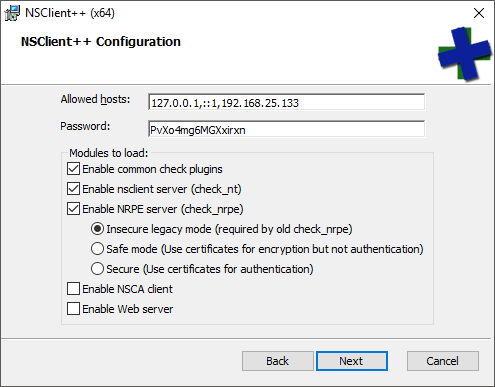
- Pay at least some attention on this screen. Everything here will be written to the NSClient++.ini file, so you can change it all later. These are the appropriate options to use with Nagios, but I’ll discuss each after the list.
- Finish the installation.
The configuration items that I instructed to choose:
- Allowed hosts: This field is required. Any source IP not in the list will be rejected by NSClient++. You can use ranges (ex: 192.168.0/24).
- Password: check_nt uses this password (-s switch). check_nrpe does not care. By default, Nagios has a single check_nt command item that you call from other sensors. If you wish to prevent password-sharing, you’ll need to duplicate the check_nt command for each separate password.
- Common check plugins: These are built-in plugins that you can use with NSClient++. I don’t do much with them, but you might.
- Enable nsclient server (check_nt): You will almost certainly use several check_nt sensors.
- Enable NRPE server (check_nrpe): My Hyper-V test scripts depend upon NRPE.
- Insecure legacy mode (required by old check_nrpe). Since we aren’t configuring certificates, this setting is required by the current check_nrpe as well.
- Enable NSCA client: I’m not using this client, so I didn’t enable it.
- Enable Web server: I just configure by text file, so I didn’t enable this, either.
Configuring NSClient++ to Work with PowerShell
You’ll need to modify NSClient++ to work with PowerShell. The installer doesn’t do that.
The ini file can be found at C:Program FilesNSClient++nsclient.ini. If you installed the 32-bit NSClient++ on 64-bit Windows, look in C:Program Files (x86). The ini file is quite a mess. The following is my nsclient.ini file, with all of the fluff stripped away and the necessary lines added for PowerShell to function. I’ve highlighted what you must add:
[/settings/default] password = PvXo4mg6MGXxirxn allowed hosts = 127.0.0.1,::1,192.168.25.133 [/settings/NRPE/server] verify mode = none insecure = true ssl options = no-sslv2,no-sslv3 allow arguments = true [/modules] CheckExternalScripts = 1 CheckHelpers = 1 CheckEventLog = 1 CheckNSCP = 1 CheckDisk = 1 CheckSystem = 1 NSClientServer = 1 NRPEServer = 1 [/settings/external scripts] allow arguments = true [/settings/external scripts/wrappings] ps1=cmd /c echo scripts%SCRIPT% %ARGS%; exit($lastexitcode) | powershell.exe -nologo -command - [/settings/external scripts/wrapped scripts] check_csvstatus=check_csvstatus.ps1 $ARG1$ $ARG2$ check_clusterquorumwitness=check_clusterquorumwitness.ps1 check_checkpointage=check_hvcheckpointage.ps1 $ARG1$ $ARG2$ check_csvspace=check_csvspace.ps1 $ARG1$ $ARG2$ $ARG3$ check_vmdyndisksize=check_hvvmdyndisksize.ps1 $ARG1$ $ARG2$ $ARG3$ $ARG4$ $ARG5$ $ARG6$
The lines afterward show how I set up the commands and parameters for my customized scripts. The script bodies themselves are not included in this article (subscriber’s area, remember?).
Change your file to include the necessary lines and save the file. At an elevated command prompt, run:
"c:Program FilesNSClient++nscp.exe" service --stop "c:Program FilesNSClient++nscp.exe" service --start
It’s a normal Windows service with the name “nscp”, so you can also use ‘services.msc’, sc, or the PowerShell Stop-Service, Start-Service, and Restart-Service commands.
After the above, run netstat -aon | findstr LISTENING. Verify that there is a line item for 5666 (check_nrpe) and a line for 12489 (check_nt).
If this host is not configured to run unsigned PowerShell commands, run this at an elevated PowerShell prompt:
Set-ExecutionPolicy RemoteSigned
Much has been written about the execution policy and I have nothing to add. You can do an Internet search to make your own decisions, of course. None of my scripts are signed, so you’ll need RemoteSigned or looser in order to use them.
That’s It!
Your deployment is complete! Now it’s time to learn how to manage Nagios and configure sensors.
Controlling Nagios
During Nagios sensor configuration, you’ll find that you spend a great deal of time managing the Nagios service. Nagios control from the Linux command line is very simple. You’ll soon memorize these commands. Activate them in a PuTTY session or a local console.
ALWAYS Check the Nagios Configuration
After making any changes to configuration files, verify that they are valid before attempting to apply them to the running configuration:
sudo service nagios checkconfig
If there are any problems, you’ll be told what they are and where to find them in the files. As long as you don’t stop Nagios, it will continue running with the configuration that it was started with. That gives you plenty of time to fix any errors.
Restart Nagios
Restart the Nagios service (only after verifying configuration!):
sudo service nagios restart
Stop and Start Nagios
If you need to take Nagios offline for a while and bring it up later (or if you forgot to checkconfig and have to recover from a broken setup), these are the commands:
sudo service nagios stop sudo service nagios start
Verify that Nagios is Running
Usually, the ability to access the web site is a good indication of whether or not Nagios is operational. If you want to check from within the Linux environment:
sudo service nagios status
This will usually fill up the screen with information, so you’ll be given the ability to scroll up and down with the arrow keys to read all of the messages. Press [Q] when you’re finished.
An Introduction to Nagios Configuration Files
From here on out, I will be using WinSCP to manipulate the Nagios configuration files on the Linux host. Use PuTTY to issue the commands to check and restart the Nagios service after configuration file changes. You do not need to restart the Apache service.
Personally, I connect using the nagios account that we created in the beginning. WinSCP remembers the last folder that it was in per user, so it’s easier for navigation and so that you never run into any file permission problems. Just make a separate entry to the host for that account:
WinSCP Nagios Site
Work your way to /usr/local/nagios/etc. This is the root configuration folder. It mostly contains information that drives how it processes other files.
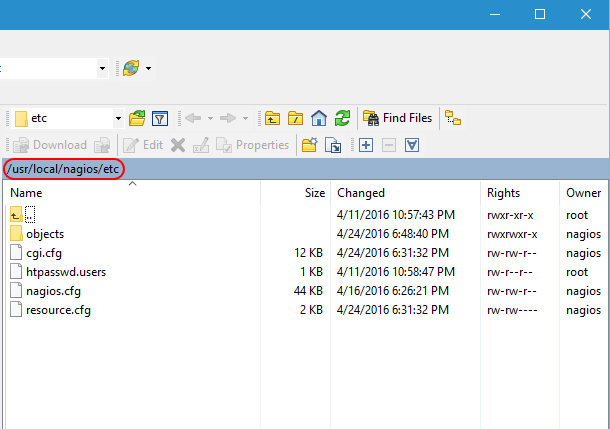
Nagios Root etc
This location contains four files. I’m not going to dive into them in great detail, but I encourage you to open them up and give their contents a look-over to familiarize yourself.
- cgi.cfg: As it says in the text, this is the primary configuration file. I have not changed anything in it.
- htpasswd.users: This is the file that Apache will check when loading objects. Use the instructions at the top of this article to modify it.
- nagios.cfg: This file contains a number of configuration elements for how Nagios interacts with the system. We are going to modify the OBJECT CONFIGURATION FILE(S) portion momentarily.
- resource.cfg: This file holds customizable macros that you create, like the ones for e-mail.
Now, open up /usr/local/nagios/etc/objects. This is where the real work is done.
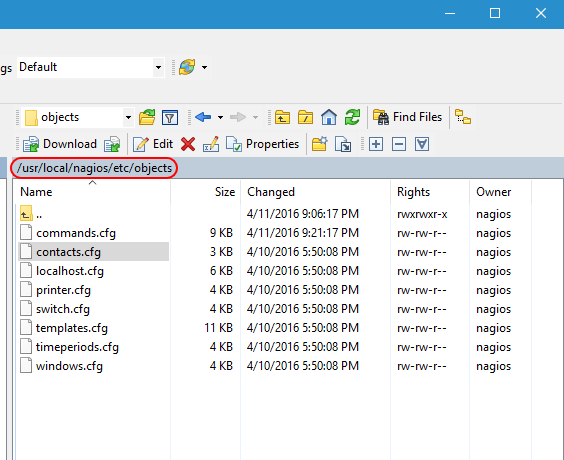
Nagios Configuration Folder in WinSCP
The file names are for your convenience only. Nagios reads them all the same way. So, don’t get agitated if you feel like a host template definition would be better in some file other than templates.cfg; Nagios doesn’t care as long as everything is formatted properly. This is what the files generally mean:
- commands.cfg: This contains the commands that constitute the actual checks. For instance, check_ping is defined here.
- contacts.cfg: When Nagios needs to tell somebody something, this is where those somebodies’ information is stored. It’s also where you connect users to time periods. For example, I have my administrative account in the business hours time period because I don’t really want to be woken up in the middle of the night because my test lab is unhappy.
- localhost.cfg: Contains checks for the Linux system that runs Nagios.
- printer.cfg: Define printer objects and checks here.
- switch.cfg: Physical switches and their check definitions are in this file.
- templates.cfg: Basic definitions that other definitions can inherit from are contained within.
- timeperiods.cfg: You probably don’t want to be notified in the middle of the night when a switch misses a single ping, but you might want to know about it during normal work hours. Define what “normal work hours” and “leave me alone” time is in this file.
- windows.cfg: Basic definitions for Windows hosts and checks.
Poke through these and get a feel for how Nagios is configured.
Nagios Objects and Their Uses
Nagios uses a few species of objects. Getting these right is important. Use the template file to guide you. The most pertinent objects are listed below:
- contact: A target for notifications — usually an individual.
- host: A host is any endpoint that can be checked. A computer, a switch, a printer, and a network-enabled refrigerator all qualify as a host.
- command: Nagios checks things by running commands. The command files live in its plugins folder. The command definitions explain to Nagios how to call those plugins.
- service: A “service” in Nagios is anything that Nagios can check with a command, and is a much more vague term than it is in Windows. In Nagios, services belong to hosts. So, if you want to know if a switch is alive by pinging it, the switch is a “host” and the ping is a “service” that calls a “command” called check_ping. You might call these “sensors” to compare to other products.
- host group: Multiple hosts that are logically lumped together constitute a host group. Use them to apply one service to lots of hosts at once.
- time period: This object is fairly well-explained by its name. They’re probably best understood by looking in the timeperiods.cfg file.
Nagios Templates
I’d say that the best place to start looking at Nagios objects is in the templates file. This is a copy/paste of the Contact template:
# Generic contact definition template - This is NOT a real contact, just a template!
define contact{
name generic-contact ; The name of this contact template
service_notification_period 24x7 ; service notifications can be sent anytime
host_notification_period 24x7 ; host notifications can be sent anytime
service_notification_options w,u,c,r,f,s ; send notifications for all service states, flapping events, and scheduled downtime events
host_notification_options d,u,r,f,s ; send notifications for all host states, flapping events, and scheduled downtime events
service_notification_commands notify-service-by-email ; send service notifications via email
host_notification_commands notify-host-by-email ; send host notifications via email
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL CONTACT, JUST A TEMPLATE!
}
Start with the define line that indicates what type of object this block is describing. Most importantly, it signals to Nagios which properties should exist. Within this particular block, all properties for a contact are present with specific settings for each. If you use this template with a new object, then these will be its default settings. Next, notice the register line. By setting it to 0, you make it unavailable for Nagios to use directly, which is what makes this definition a template.. Now, look at an implementation of the above template:
# Just one contact defined by default - the Nagios admin (that's you)
# This contact definition inherits a lot of default values from the 'generic-contact'
# template which is defined elsewhere.
define contact{
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Eric ; Full name of user
service_notification_period workhours
email [email protected] ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}
It is also defined as a contact. First, notice the use line. Its name matches that of the template. That means that you don’t need to provide every setting for this contact, only the ones that you want to differ from the template. It is not necessary for an object to use a template. You can fill out all details for an object. A live object cannot use another live object, though, but one template can use another.
I often make backups of my configuration files before tinkering with them. WinSCP makes this simple with the Duplicate command. I also tend to copy my live configuration files to a safe place. Even though this whole thing seems easy to understand, you will make mistakes. Some of your mistakes are going to seem very stupid in retrospect. Always, always, always run sudo service nagios checkconfig before applying any new changes!
Nagios Hosts
A host in Nagios is an endpoint. It’s an easy definition in my case because I am going to specifically talk about Hyper-V hosts. The following is a host template definition that I created for my environment:
###############################################################################
###############################################################################
#
# HYPER-V HOST DEFINITIONS
#
###############################################################################
###############################################################################
define host{
use hyper-v-server
host_name svhv1
alias Hyper-V Host 1
address 192.168.25.10
}
define host{
use hyper-v-server
host_name svhv2
alias Hyper-V Host 2
address 192.168.25.11
}
These hosts use a template that I created:
###############################################################################
###############################################################################
#
# HYPER-V HOST TEMPLATE DEFINITION
#
###############################################################################
###############################################################################
define host{
use windows-server
name hyper-v-server
hostgroups hyper-v-servers
register 0
}
You’ll notice that this template uses the base windows-server template, but really makes no changes. I’m not overriding much in the windows-server template, so I could have all of my hosts use that one directly. However, creating a template to set up an inheritance hierarchy now is an inexpensive step that gives me flexibility later.
Nagios Groups
Most of the singular objects, like contacts and hosts, also have a corresponding group object. You might have noticed in my Hyper-V host template that it has a hostgroups property. Every host object that uses this template will be a member of the hyper-v-servers host group. Groups have very simple definitions:
###############################################################################
###############################################################################
#
# HYPER-V HOSTGROUP DEFINITION
#
###############################################################################
###############################################################################
define hostgroup{
hostgroup_name hyper-v-servers
alias Hyper-V Servers
}
I could also have used a members property within the host group definition or a hostgroups property within my Hyper-V host definitions to accomplish the same thing. This is less typing.
Host groups are very useful. First, they get their own organization on the Host Groups menu item in the Nagios web interface:

Nagios Host Groups Display
Second, you can define services at the host group level. That’s important, because otherwise, you’d have to define services for each and every host that you want to check, even if they’re all using the same check!
Nagios Services
Don’t let the term service confuse you with the same thing in a Windows environment. In Nagios, a service has a broader, although still perfectly correct definition. Anything that we can check is a service, whether that’s a ping response, Apache returning valid information on port 80, or even the output of a customized script like I have created for Hyper-V items.
The following is a service that I have created to monitor a Windows service — the Hyper-V Virtual Machine Manager service, to be exact:
# check that VMMS is running
define service{
use generic-service
hostgroup_name hyper-v-servers
service_description Service: Virtual Machine Management
check_command check_nt!SERVICESTATE!-d SHOWALL -l vmms
}
Notice my use of hostgroup_name so that I only have to create this service one time. If I were creating a service for a specific host, I would use host_name instead.
I encourage you to look at the documentation for services. You may want to change the frequency of when checks occur. You may also want to redefine how long a service can be in a trouble state before you are notified.
Useful Nagios Objects Documentation
I’ve spent a little bit of time going over the objects within Nagios, but there is already a wealth of documentation on them. You will, no doubt, want to configure Nagios items on your own. NSClient++ also has a great deal more capability than what I’ve shown. These links helped me more than anything else:
Dealing with Problems Reported by Nagios
The web display is nice, and everyone enjoys seeing a screen-full of happy green monitor reports, but that’s not why we set up Nagios installations. Things break, and we want to know before users start calling. With the configuration that you have, you’ll have the ability to start getting notifications as soon as you set yourself up as a contact with valid information. When a problem occurs, Nagios will mark it as being in a SOFT warning or critical state, then it will wait to see if the problem persists for a total of three check periods (configurable). One the third check, it will mark the service as being in a HARD warning or critical state and send a notification.
If you fix a problem quickly, or if it resolves on its own, you’ll get a Recovery e-mail to let you know that all is well again. If the problem persists, you’ll continue getting an e-mail every few minutes (configurable). If one host has many services in a critical state, or if many separate hosts have issues, you’re going to be looking at a lot of e-mails.
The following screenshot shows what a service looks like in a critical state. You can see it on the Services menu item, the Services submenu under the Problems menu, and on the (Unhandled) link that is next to it.

Nagios Critical Service
If you click the link for the name of the service, in this case, Service: DNS, it will take you to the following details screen:
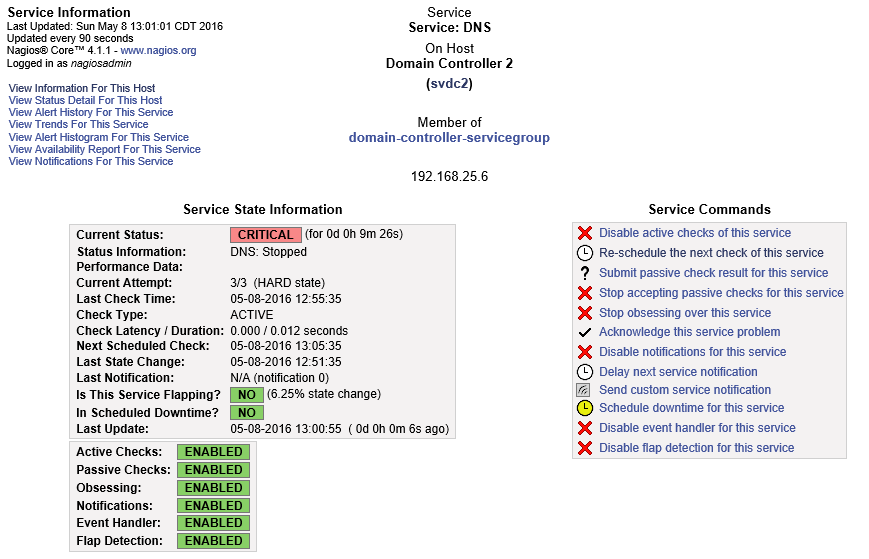
Nagios Service Detail
Take some time to familiarize yourself with this screen. I’m not going to discuss every option, but they are all useful. For now, I want you to look at Acknowledge this service problem.
Acknowledging Problems in Nagios
“Acknowledging” means that you are aware that the service is down. Once acknowledged, an acknowledgement notification will be sent out, but then no further notifications until the service is recovered. Basically, you’re telling Nagios, “Yes, yes, I know it’s down, leave me alone!” Click the Acknowledge this service problem link as shown in the previous screen shot and you’ll be taken to the following screen:

Nagios Acknowledgement
You can read the Command Description for an extended explanation of what Acknowledgement does and what your options are. I tend to fill out the comments field, but it’s up to you. Upon pressing Commit, the notification message is sent out and Nagios stops alerting until the service recovers (sometimes you get one more problem notification first).
Rescheduling a Nagios Service Check
Nagios runs checks on its own clock. You might have a service that doesn’t need frequent checks, so you might set it to only be tested every hour. During testing, you certainly won’t want to wait that long to see if your check is going to work. You might also want that Recovery message to go out right away after fixing a problem. In the service detail screen as shown a couple of screen shots up, click the Re-schedule the next check of this service link:
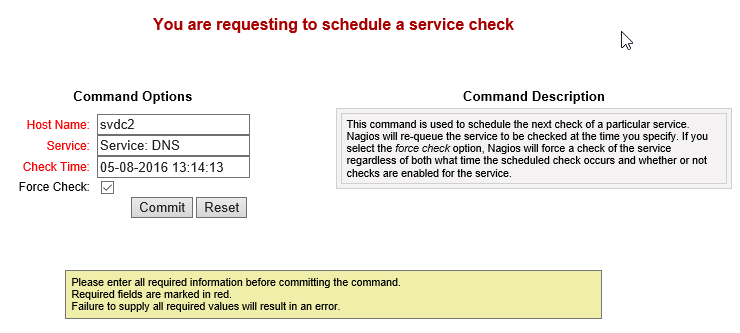
Reschedule Nagios Service Check
Of course, the time in the screen shot doesn’t mean anything to you. It’s the exact moment that I clicked the link on my system. If you then click Commit, it will immediately run the check. It might still take a few moments for the results to be returned so you won’t necessarily see any differences immediately, but the check does occur on time.
Scheduling Downtime
Smaller shops might not find it important to schedule downtime. If your Hyper-V host can reboot in less than 15 minutes, then you might not even get a downtime notification using the default settings. However, Nagios will give you the ability to start providing availability reports. Wouldn’t it be nice to show your boss and/or the company owners that your host was only ever down during scheduled maintenance windows?
From the service detail screen shot earlier, you can see the Schedule downtime for this service link. I’m assuming that you’ll be more likely to want to set downtime on a host rather than an individual service. The granularity is there for you to do either (or both) as suits your needs. A host’s detail screen (not shown) has Schedule downtime for this host and Schedule downtime for all services on this host links. You can also schedule downtime for an entire host or service group. These screens all look like this:
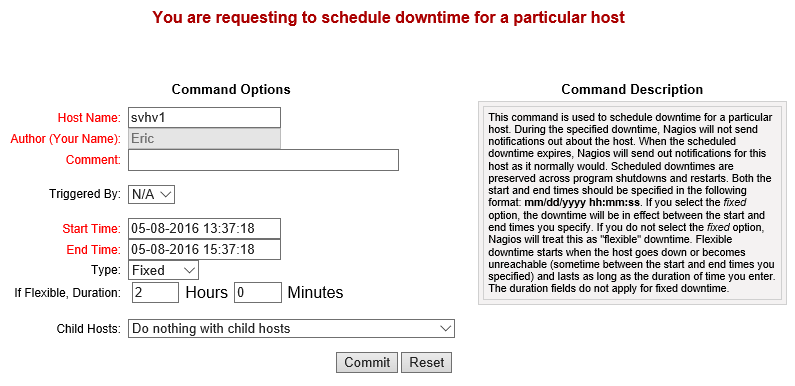
Nagios Downtime Scheduler
During scheduled downtime, notifications aren’t sent. In all reports, any outages during downtime are in the Scheduled category rather than Unscheduled.
The default Nagios Core distribution does not have a way to automatically schedule recurring downtime. There are some community-supported options.
Nagios Availability Reports
You saw a link in the service details screen shot above to View Availability Report for This Service. Hosts and services have this link. There’s also an Availability menu in the Reports section on the left that allows you to build custom reports. The following is a simple host availability report:
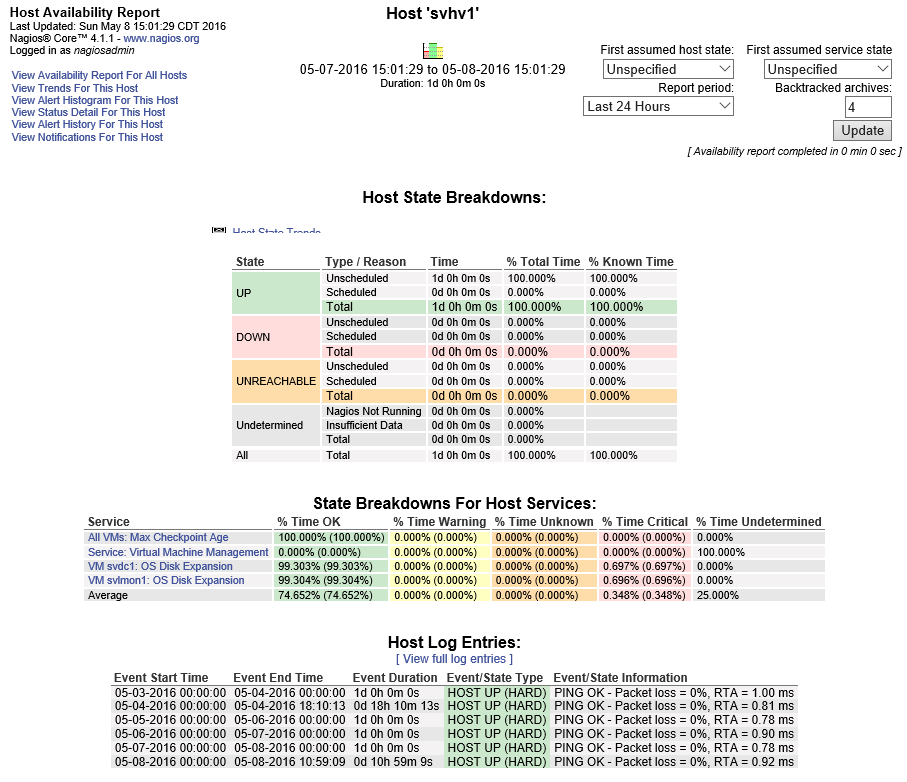
Nagios Availability
This is only for a single day. Notice the report options in the top right.
User Management for Nagios
So far, I’ve had you use the “nagiosadmin” account. As you spread out your deployment, you’re going to also set up new contacts. If you like, you can restrict those contacts to only see their own systems.
First, add a user to the nagcmd group. This will allow them to configure Nagios’ files. Be careful! If you don’t trust someone, skip this part and handle configuration for them. Optionally, you can skip the usermod parts (adds them to a group) and give them targeted access to specific configuration files.
sudo useradd -m -s /bin/bash andy sudo passwd andy # enter the user's initial password when prompted sudo usermod -aG nagios andy sudo usermod -aG nagcmd andy
Due to a difference between the Windows security model and the Windows security model, there is no secure way for Apache on Linux to be able to read the system users. So, you need to create a completely separate account for the Nagios web interface:
sudo htpasswd /usr/local/nagios/etc/htpasswd.users andy
Now, create a Nagios contact with a matching contact_name:
define contact{
contact_name andy
use generic-contact
alias Andy
email andy@localhost
}
The hosts, services, contact groups, etc. that the “andy” account is attached to will determine what Andy sees when he logs in to the Nagios web interface.
Using Nagios to Monitor Hyper-V – The real fun stuff starts here!
You now have all the tools you need to build your Hyper-V monitoring framework with Nagios. I’ve also written a few scripts and services that will get you up and running: Required Base Scripts, Monitoring the Oldest Checkpoint Age, Monitoring Dynamically Expanding VHDX Size, and more.
If you’d like to pick up these scripts and services, please register below to get access!
- www.altaro.com/hyper-v/nagios-for-hyper-v-required-base-scripts/
- www.altaro.com/hyper-v/nagios-hyper-v-monitoring-oldest-checkpoint-age/
- www.altaro.com/hyper-v/nagios-hyper-v-monitoring-dynamically-expanding-vhdx-size/


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron

