Save to My DOJO
In part 3, I showed you a diagram of a couple of switches that were connected together using a single port. I mentioned then that I would likely use link aggregation to connect those switches in a production environment. Windows Server introduced the ability to team adapters natively starting with the 2012 version. Hyper-V can benefit from this ability.
- Part 1 – Mapping the OSI Model
- Part 2 – VLANs
- Part 3 – IP Routing
- Part 4 – Link Aggregation and Teaming
- Part 5 – DNS
- Part 6 – Ports, Sockets, and Applications
- Part 7 – Bindings
- Part 8 – Load-Balancing Algorithms
To save you from needing to click back to part 2, here is the visualization again:
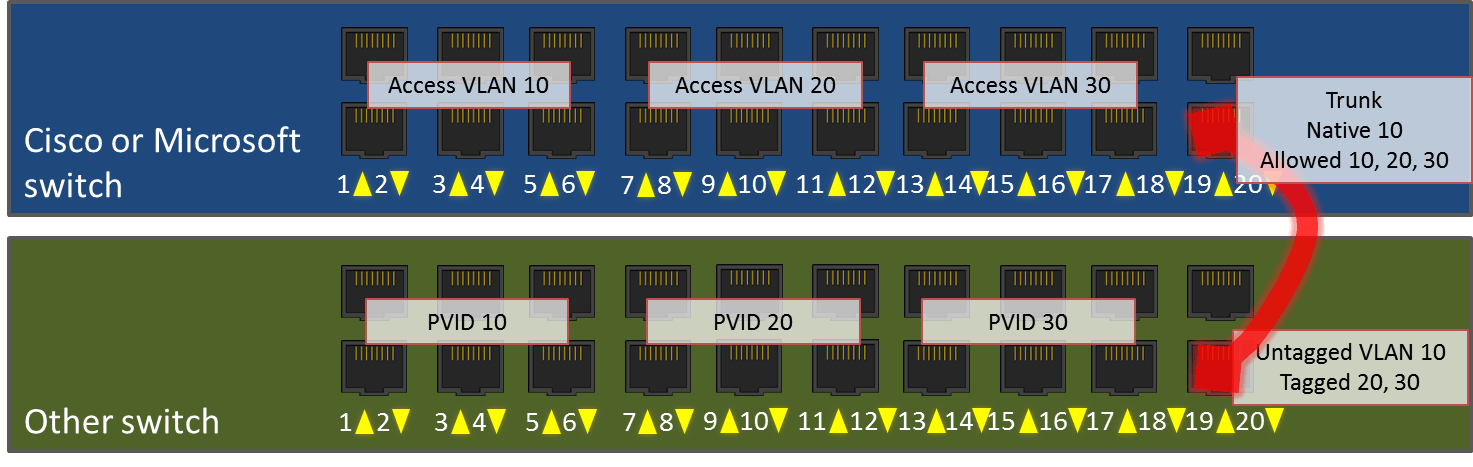 Port 19 is empty on each of these switches. That’s not a good use of our resources. But, we can’t just go blindly plugging in a wire between them, either. Even if we configure ports 19 just like we have ports 20 configured, it still won’t work. In fact, either of these approaches will fail with fairly catastrophic effects. That’s because we’ll have created a loop.
Port 19 is empty on each of these switches. That’s not a good use of our resources. But, we can’t just go blindly plugging in a wire between them, either. Even if we configure ports 19 just like we have ports 20 configured, it still won’t work. In fact, either of these approaches will fail with fairly catastrophic effects. That’s because we’ll have created a loop.
Imagine that we have configured ports 19 and 20 on each switch identically and wired them together. Then, switch port 1 on switch 1 sends out a broadcast frame. Switch 1 will know that it needs to deliver that frame to every port that’s a member of VLAN 10. So, it will go to ports 2-6 and, because they are trunk ports with a native VLAN of 10, it will also deliver it to 19 and 20. Ports 19 and 20 will carry the packet over to switch 2. When it comes out on port 19, it will try to deliver it to ports 1-6 and 20. When it comes out on port 20, it will try to deliver it to ports 1-6 and port 19. So, the frame will go back to ports 19 and 20 on switch 1, where it will repeat the process. Because Ethernet doesn’t have a time to live like TCP/IP does (at least, as far as I know, it doesn’t), this process will repeat infinitely. That’s a loop.
Most switches can identify a loop long before any frames get caught up. The way Cisco switches will handle it is by cutting off the offending loop ports. So, if it’s the only connection that switch has with the outside world, all its endpoints will effectively go out. I’ve never put any other manufacturer into a loop, so I’m not sure how the various other vendors will deal with it. No matter what, you can’t just connect switches to each other using multiple cables without some configuration work.
Port Channels and Link Aggregation
The answer to the above problem is found in Port Channels or Link Aggregation. A port channel is Cisco’s version. Everyone else calls it link aggregation. Cisco does have some proprietary technology wrapped up in theirs, but it’s not necessary to understand that for this discussion. So, to make the above problem go away, we would assign ports 19 and 20 on the Cisco switch into a port channel. On any other hardware vendor, we would assign them to a link aggregation group (LAG). Once that’s done, the port channel or LAG is then configured just like a single port would be, as in trunk/(un)tagged or access/PVID. What’s really important to understand here is that the MAC addresses that the switch assigned to the individual ports are gone. The MAC address now belongs to the port channel/LAG. MAC addresses that it knows about on the connecting switch are delivered to the port channel, not to a switch port.
LAG Modes
It’s been quite a while since I worked on a Cisco environment, but as I recall, a port channel is just a port channel. You don’t need to do a lot of configuration once it’s set up. For other vendors, you have to set up the mode. We’re going to see these modes again with the Windows NIC team, so we’ll get acquainted with that first.
NIC Teaming
Now we look at how this translates into the Windows and Hyper-V environment. For a number of years, we’ve been using NIC teaming in our data centers to provide a measure of redundancy for servers. This uses multiple connections as well, but the most common types don’t include the same sort of cooperation between server and switch that you saw above between switches. Part of it is that a normal server doesn’t usually host multiple endpoints the way a switch does, so it doesn’t really need a trunk mode. A server is typically not concerned with VLANs. So, usually a teamed interface on a server isn’t maintaining two active connections. Instead, it has its MAC address registered on one of the two connected switch ports and the other is just waiting in reserve. Remember that it can’t actually be any other way, because a MAC address can only appear on a single port. So, even though a lot of people thought that they were getting aggregated bandwidth, they really weren’t. But, the nice thing about this configuration is that it doesn’t need any special configuration on the switch, except perhaps if there is a security restriction that prevents migration of MAC addresses.
New, starting in Windows/Hyper-V Server 2012, is NIC teaming built right into the operating system. Before this, all teaming schemes were handled by manufacturers’ drivers. There are three teaming modes available.
Switch Independent
This is the same mode as the traditional teaming mode. The switch doesn’t need to participate. Ordinarily, the Hyper-V switch will register all of its virtual adapters’ MAC addresses on a single port, so all inbound traffic comes through a single physical link. We’ll discuss the exceptions in another post. Outbound traffic can be sent using any of the physical links.
The great benefit of this method is that it can work with just about any switch, so small businesses don’t need to make special investments in particular hardware. You can even use it to connect to multiple switches simultaneously for redundancy. The downside, of course, is that all incoming traffic is bound to a single adapter.
Static
The Hyper-V virtual switch and many physical switches can operate in this mode. The common standard is 802.3ad, but not all implementations are equal. In this method, each member is grouped into a single unit as explained in the Port Channels and Link Aggregation section above. Both switches (whether physical or virtual) much have their matching members configured into a static mode.
MAC addresses on all sides are registered on the overall aggregated group, not on any individual port. This allows incoming and outgoing traffic to use any of the available physical links. The drawbacks are that the switches all have to support this and you lose the ability to split connections across physical switches (with some exceptions, as we’ll talk about later).
If a connection experiences troubles but isn’t down, then the static switch will experience problems that might be difficult to troubleshoot. For instance, if you create a static team on 4 physical adapters in your Hyper-V host but only three of the switch’s ports are configured in a static trunk, then the Hyper-V system will still attempt to use all four.
LACP
LACP stands for “Link Aggregation Control Protocol”. This is defined in the 802.1ax standard, which supersedes 802.3ad. Unfortunately, there is a common myth that gives the impression that LACP provides special bandwidth consolidation capabilities over static aggregation. This is not true. An LACP group is functionally like a static group. The difference is that connected switches communicate using LACPDU packets to detect problems in the line. So, if the example setup at the end of the Static teaming section used LACP instead of Static, the switches would detect that one side was configured using only 3 of the 4 connected ports and would not attempt to use the 4th link. Other than that, LACP works just like static. The physical switch needs to be setup for it, as does the team in Windows/Hyper-V.
Bandwidth Usage in Aggregated Links
Bandwidth usage in aggregated links is a major confusion point. Unfortunately, it’s not a simple matter of all physical links being simply combined into one bigger one. It’s more likely that load-balancing will occur than bandwidth aggregation.
In most cases, the sending switch/team controls traffic flow. Specific load-balancing algorithms will be covered in another post. However it chooses to perform it, the sending system will transmit on a specific link. But, any given communication will almost exclusively use only one physical link. This is mostly because it helps ensure that the frames that make up a particular conversation arrive in order. If they were broken up and sent down separate pipes, contention and buffering would dramatically increase the probability that they would be scrambled before reaching their destination. TCP and a few other protocols have built-in ways to correct this, but this is a computationally expensive operation that usually doesn’t outweigh the restrictions of simply using a single physical link.
Another reason for the single-link restriction is simple practicality. Moving a transmission through multiple ports from Switch A to Switch B is fairly trivial. From Switch B to Switch C, it becomes less likely that enough links will be available. The longer the communications chain, the more likely a transmission won’t have the same bandwidth available as the initial hop. Also, the final endpoint is most likely on a single adapter. The available methods to deal with this are expensive and create a drag on network resources.
The implications of all this aren’t exactly clear. A quick explanation is that no matter what teaming mode you pick, when you run a network performance test across your team, the result is going to show the maximum speed of a single team member. But, if you run two such tests simultaneously, it might use two of the links. What I normally see is people trying to use a file copy to test bandwidth aggregation. Aside from the fact that file copy is a horrible way to test anything other than permissions, it’s not going to show anything more than the speed of a single physical link.
The exception to the sender-controlling rule is the switch-independent teaming mode. Inbound traffic is locked to a single physical adapter as all MAC addresses are registered in a single location. It can still load-balance outbound traffic across all ports. If used with the Hyper-V port load-balancing algorithm, then the MAC addresses for virtual adapters will be evenly distributed across available physical adapters. Each virtual adapter can still only receive at the maximum speed of a single port, though.
Stacking Switches
Some switches have the power to “stack”. What this means is that individual physical switches can be combined into a single logical unit. Then, they share a configuration and operate like a single unit. The purpose is for redundancy. If one of the switch(es) fails, the other(s) will continue to operate. What this means is that you can split a static or LACP inter-switch connection, including to a Hyper-V switch, across multiple physical switch units. It’s like having all the power of the switch independent mode with none of the drawbacks.
One concern with stacked switches is the interconnect between them. Some use a special interlink cable that provides very high data transfer speeds. With those, the only bad thing about the stack is the monetary cost. Cheaper stacking switches often just use regular Ethernet or 1gb or 2gb fiber. This could lead to bandwidth contention between the stack members. Since most networks use only a fraction of their available bandwidth at any given time, this may not be an issue. For heavily loaded core switches, a superior stacking method is definitely recommended.
Aggregation Summary
Without some understanding of load-balancing algorithms, it’s hard to get the complete picture here. These are the biggest things to understand:
- The switch independent mode is the closest to the original mode of network adapter teaming that has been in common use for years. It requires that all inbound traffic flow to a single adapter. You cannot choose this adapter. If combined with the Hyper-V switch port load-balancing algorithm, virtual switch ports are distributed evenly across the available adapters and each will use only its assigned port for inbound traffic.
- Static and LACP modes are common to the Windows/Hyper-V Server NIC team and most smart switches.
- Not all static and LACP implementations are created equally. You may encounter problems connecting to some switches.
- LACP doesn’t have any capabilities for bandwidth aggregation that the static method does not have.
- Bandwidth aggregation occurs by balancing different communications streams across available links, not by using all possible paths for each stream.
What’s Next
While it might seem logical that the next post would be about the load-balancing algorithms, that’s actually a little more advanced than where I’m ready for this series to proceed. Bandwidth aggregation using static and LACP modes is a fairly basic concept in terms of switching. I’d like to continue with the basics of traffic flow by talking about DNS and protocol bindings.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


24 thoughts on "Link Aggregation and Teaming in Hyper-V"
need more technical details on how eth working on Hyper-V. conversations between VMs & switches on teamed NICs. MAC converting and so on.
great series of posts! thank so much! read Your posts with great interest but wait for more technical information.
Hi Andrey, and thanks for reading.
We’re getting there. We just want to be sure that everyone has at least been exposed to this more fundamental information. We need to learn to walk before we can learn to fly!
need more technical details on how eth working on Hyper-V. conversations between VMs & switches on teamed NICs. MAC converting and so on.
great series of posts! thank so much! read Your posts with great interest but wait for more technical information.
Just wanted to say thanks for the clear effort you put into making all these articles understandable.
You’re welcome, and thank you for taking the time to express that!
I’ve an issue with Teaming NIC configuratin on HyperV 2012 R2.
Can I expose to you my problem
Thanks in advance
You can ask. We can try to help.
I’ve come across something quite interesting today with a client using Windows 2012 R2 and LACP Teaming. I have always read and been told that you cannot use LACP with independent switches and should use stacked switches to accomplish LACP with resiliency.
We have got a stack of switches (D-Link 1510 series) however we are doing a firmware upgrade to the stack with minimal downtime to the network. For that reason we have put another D-Link 1510 (not part of stack) in and we’re moving one cable from each of our server teams across to this other switch so we can power down the stack to upgrade. Most servers are switch independent so we weren’t worried, however a couple of servers are LACP and we have discovered that as long as we set-up LACP on the switch port we’re connecting to on the new switch, we can still have one port connected to each of the independent switches and they still work.
When I say still work they show OK within Windows NIC teaming and traffic is sent and received through both adapters. I thought this couldn’t happen. Can anyone explain? I’ve been googling and reading everything!
Thanks, Joe.
I don’t know exactly how it’s working but I’m not completely surprised, either. Is it receiving on disparate ports or only sending?
I’ve come across something quite interesting today with a client using Windows 2012 R2 and LACP Teaming. I have always read and been told that you cannot use LACP with independent switches and should use stacked switches to accomplish LACP with resiliency.
We have got a stack of switches (D-Link 1510 series) however we are doing a firmware upgrade to the stack with minimal downtime to the network. For that reason we have put another D-Link 1510 (not part of stack) in and we’re moving one cable from each of our server teams across to this other switch so we can power down the stack to upgrade. Most servers are switch independent so we weren’t worried, however a couple of servers are LACP and we have discovered that as long as we set-up LACP on the switch port we’re connecting to on the new switch, we can still have one port connected to each of the independent switches and they still work.
When I say still work they show OK within Windows NIC teaming and traffic is sent and received through both adapters. I thought this couldn’t happen. Can anyone explain? I’ve been googling and reading everything!
Thanks, Joe.
Hi there, great reading, but is missing how to do it!
Clear, helpful, correct, complete.
I see the “old guard” approach (like me).
“Bravo!”
Clear, helpful, correct, complete.
I see the “old guard” approach (like me).
“Bravo!”