Save to My DOJO
One of my very first jobs performing server support on a regular basis was heavily focused on backup. I witnessed several heart-wrenching tragedies of permanent data loss but, fortunately, played the role of data savior much more frequently. I know that most, if not all, of the calamities, could have at least been lessened had the data owners been more educated on the subject of backup. I believe very firmly in the value of a solid backup strategy, which I also believe can only be built on the basis of a solid education in the art. This article’s overarching goal is to give you that education by serving a number of purposes:
- Explain industry-standard terminology and how to apply it to your situation
- Address and wipe away 1990s-style approaches to backup
- Clearly illustrate backup from a Hyper-V perspective
Backup Terminology
Whenever possible, I avoid speaking in jargon and TLAs/FLAs (three-/four-letter acronyms) unless I’m talking to a peer that I’m certain has the experience to understand what I mean. When you start exploring backup solutions, you will have these tossed at you rapid-fire with, at most, brief explanations. If you don’t understand each and every one of the following, stop and read those sections before proceeding. If you’re lucky enough to be working with an honest salesperson, it’s easy for them to forget that their target audience may not be completely following along. If you’re less fortunate, it’s simple for a dishonest salesperson to ridiculously oversell backup products through scare tactics that rely heavily on your incomplete understanding.
- Backup
- Full/incremental/differential backup
- Delta
- Deduplication
- Inconsistent/crash-consistent/application-consistent
- Bare-metal backup/restore (BMB/BMR)
- Disaster Recovery/Business Continuity
- Recovery point objective (RPO)
- Recovery time objective (RTO)
- Retention
- Rotation — includes terms such as Grandfather-Father-Son (GFS)
There are a number of other terms that you might encounter, although these are the most important for our discussion. If you encounter a vendor making up their own TLAs/FLAs, take a moment to investigate their meaning in comparison to the above. Most are just marketing tactics — inherently harmless attempts by a business entity trying to turn a coin by promoting its products. Some are more nefarious — attempts to invent a nail for which the company just conveniently happens to provide the only perfectly matching hammer (with an extra “value-added” price, of course).
Backup
This heading might seem pointless — doesn’t everyone know what a backup is? In my experience, no. In order to qualify as a backup, you must have a distinct, independent copy of data. A backup cannot have any reliance on the health or well-being of its source data or the media that contains that data. Otherwise, it is not a true backup.
Full/Incremental/Differential Backups
Recent technology changes and their attendant strategies have made this terminology somewhat less popular than in past decades, but it is still important to understand because it is still in widespread use. They are presented in a package because they make the most sense when compared to each other. So, I’ll give you a brief explanation of each and then launch into a discussion.
- Full Backups: Full backups are the easiest to understand. They are a point-in-time copy of all target data.
- Differential Backups: A differential backup is a point-in-time copy of all data that is different from the last full backup that is its parent.
- Incremental Backups: An incremental backup is a point-in-time copy of all data that is different from the backup that is its parent.
The full backup is the safest type because it is the only one of the three that can stand alone in any circumstances. It is a complete copy of whatever data has been selected.
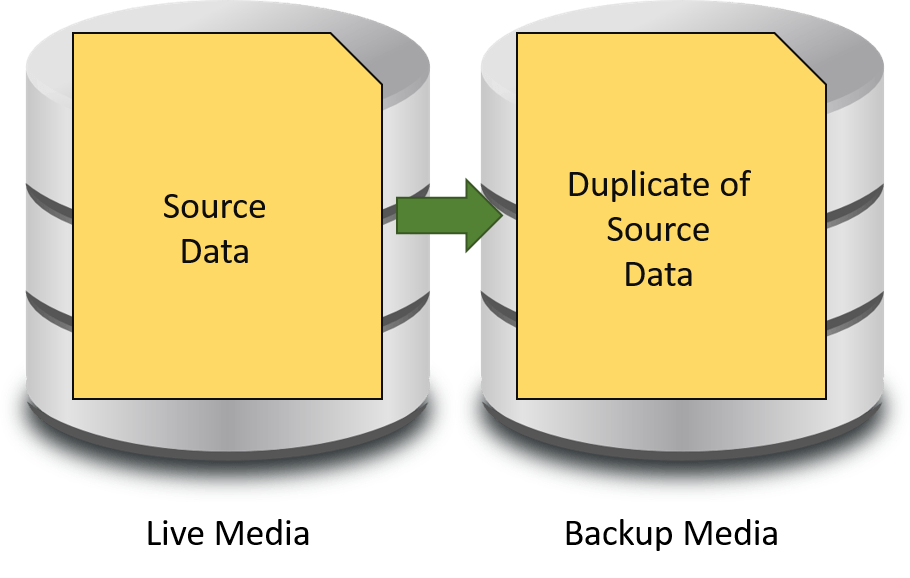
Full Backup
A differential backup is the next safest type. Remember the following:
- To fully restore the latest data, a differential backup always requires two backups: the latest full backup and the latest differential backup. Intermediary differential backups, if any exist, are not required.
- It is not necessary to restore from the most recent differential backup if an earlier version of the data is required.
- Depending on what data is required and the intelligence of the backup application, it may not be necessary to have both backups available to retrieve specific items.
The following is an illustration of what a differential backup looks like:
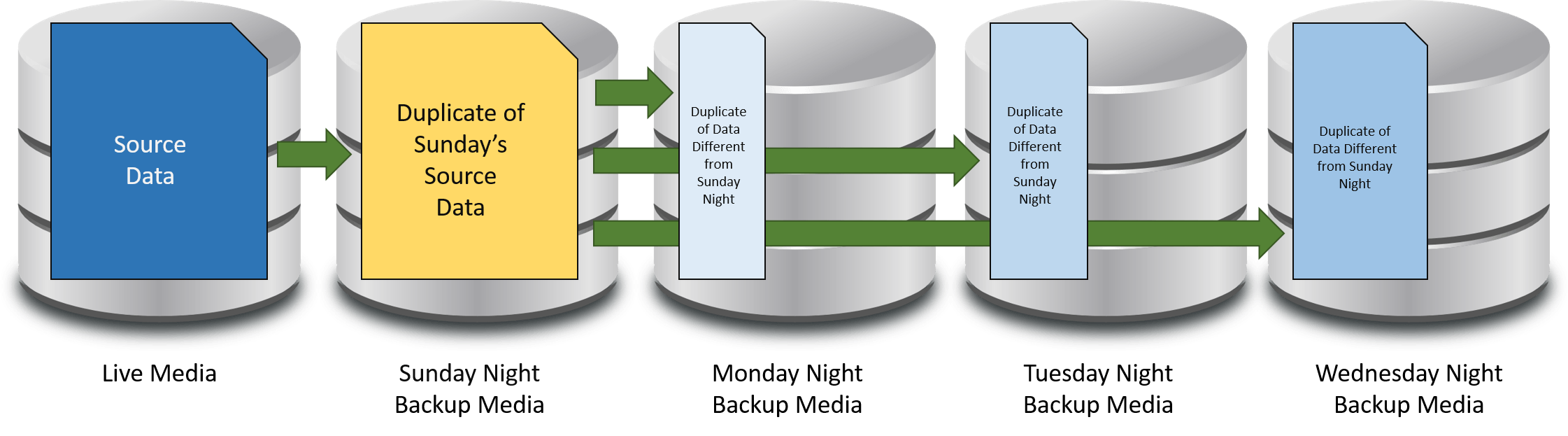
Differential Backup
Each differential backup goes all the way back to the latest full backup as its parent. Also, notice that each differential backup is slightly larger than the preceding differential backup. This phenomenon is conventional wisdom on the matter. In theory, each differential backup contains the previous backup’s changes as well as any new changes. In reality, it truly depends on the change pattern. A file backed up on Monday might have been deleted on Tuesday, so that part of the backup certainly won’t be larger. A file that changed on Tuesday might have had half its contents removed on Wednesday, which would make that part of the backup smaller. A differential backup can range anywhere from essentially empty (if nothing changed) to as large as the source data (if everything changed). Realistically, you should expect each differential backup to be slightly larger than the previous.
The following is an illustration of an incremental backup:
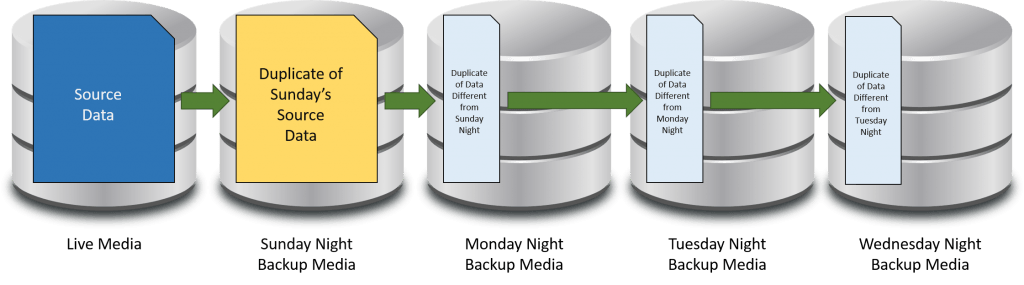
Incremental Backup
Incremental backups are best thought of as a chain. The above shows a typical daily backup in an environment that uses a weekly full with daily incrementals. If all data is lost and restoring to Wednesday’s backup is necessary, then every single night’s backup from Sunday onward will be necessary. If any one is missing or damaged, then it will likely not be possible to retrieve anything from that backup or any backup afterward. Therefore, incremental backups are the riskiest; they are also the fastest and consume the least amount of space.
Historically, full/incremental/differential backups have been facilitated by an archive bit in Windows. Anytime a file is changed, Windows sets its archive bit. The backup types operate with this behavior:
- A full backup captures all target files and clears any archive bits that it finds.
- A differential backup captures only target files that have their archive bit set and it leaves the bit in the state that it found it.
- An incremental backup captures only files with the archive bit set and clears it afterward.
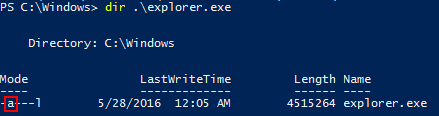
Archive Bit Example
Delta
“Delta” is probably the most overthought word in all of technology. It means “difference”. Do not analyze it beyond that. It just means “difference”. If you have $10 in your pocket and you buy an item for $8, the $8 dollars that you spent is the “delta” between the amount of money that you had before you made the purchase and the amount of money that you have now.
The way that vendors use the term “delta” sometimes changes, but usually not by a great deal. In the earliest incarnation that I am aware of “delta” as applied to backups, it meant intra-file changes. All previous backup types operated with individual files being the smallest level of granularity (not counting specialty backups such as Exchange item-level). Delta backups would analyze the blocks of individual files, making the granularity one step finer.
The following image illustrates the delta concept:
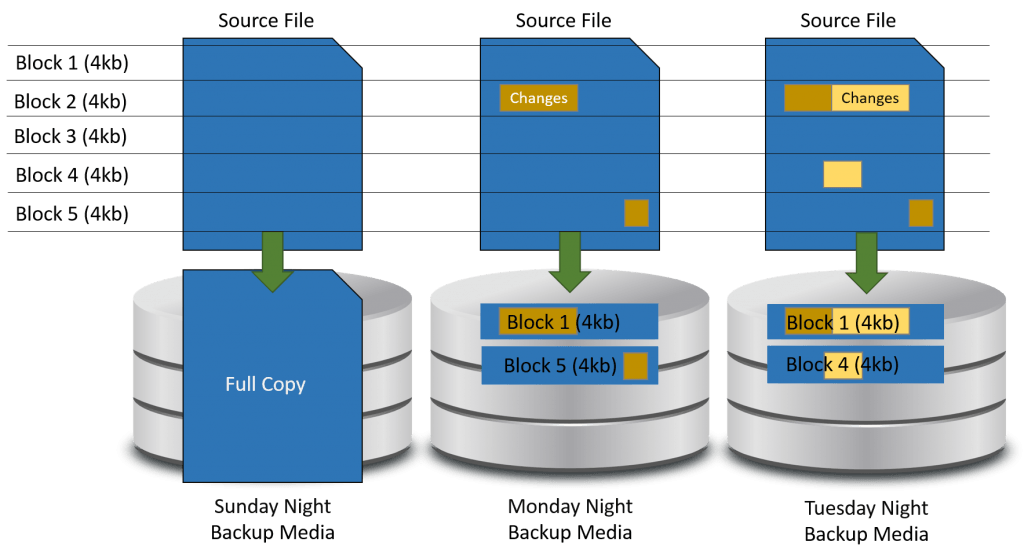
Delta Backup
A delta backup is essentially an incremental backup, but at the block level instead of the file level. Somebody got the clever idea to use the word “delta”, probably so that it wouldn’t be confused with “differential”, and the world thought it must mean something extra special because it’s Greek.
The major benefit of delta backups is that they use much less space than even incremental backups. The trade-off is in the computing power to calculate deltas. The archive bit can tell it if a file needs to be scanned, but it cannot tell it which blocks to cover. Backup systems that perform delta operations require some other method for change tracking.
Deduplication
Deduplication represents the latest iteration of backup innovation. The term explains itself quite nicely. The backup application searches for identical blocks of data and reduces them to a single copy.
Deduplication involves three major feats:
- The algorithm that discovers duplicate blocks must operate in a timely fashion
- The system that tracks the proper location of duplicated blocks must be foolproof
- The system that tracks the proper location of duplicated blocks must use significantly less storage than simply keeping the original blocks
So, while deduplication is conceptually simple, implementations can depend upon advanced computer science.
Deduplication’s primary benefit is that it can produce backups that are even smaller than delta systems. Part of that will depend on the overall scope of the deduplication engine. If you were to run fifteen new Windows Server 2016 virtual machines through even a rudimentary deduplicator, it would reduce all of them to the size of approximately a single Windows Server 2016 virtual machine — a 93% savings.
There is risk in overeager implementations, however. With all data blocks represented by a single copy, each block becomes a single point of failure. The loss of a single vital block could spell disaster for a backup set. This risk can be mitigated by employing a single pre-existing best practice: always maintain multiple backups.
Inconsistent/Crash-Consistent/Application-Consistent
We already have an article set that explores these terms in some detail. Quickly:
- Inconsistent backups would be effectively the same thing as performing a manual file copy of a directory tree.
- Crash-consistent backup captures data as it sits on the storage volume at a given point in time, but cannot touch anything passing through the CPU or waiting in memory. You could lose any in-flight I/O operations.
- Application-consistent backup coordinates with the operating system and, where possible, individual applications to ensure that in-flight I/Os are flushed to disk so that there are no active file changes at the moment that the backup is taken
I occasionally see people twisting these terms around, although I believe that’s most accidental. The definitions that I used above have been the most common, stretching back into the 90s. Be aware that there are some disagreements, so ensure that you clarify terminology with any salespeople.
Bare-Metal Backup/Restore
A so-called “bare-metal backup” and/or “bare metal restore” involves capturing the entirety of a storage unit including metadata portions such as the boot sector. These backup/restore types essentially mean that you could restore data to a completely empty physical system without needing to install an operating system and/or backup agent on it first.
Disaster Recovery/Business Continuity
The terms “Disaster Recovery” (DR) and “Business Continuity” are often used somewhat interchangeably in marketing literature. “Disaster Recovery” is the older term and more accurately reflects the nature of the involved solutions. “Business Continuity” is a newer, more exciting version that sounds more positive but mostly means the same thing. These two terms encompass not just restoring data, but restoring the organization to its pre-disaster state. “Business Continuity” is used to emphasize the notion that, with proper planning, disasters can have little to no effect on your ability to conduct normal business. Of course, the more “continuous” your solution is, the higher your costs are. That’s not necessarily a bad thing, but it must be understood and expected.
One thing that I really want to make very clear about disaster recovery and/or business continuity is that these terms extend far beyond just backing up and restoring your data. DR plans need to include downtime procedures, phone trees, alternative working sites, and a great deal more. You need to think all the way through a disaster from the moment that one occurs to the moment that everything is back to some semblance of normal.
Recovery Point Objective
The maximum acceptable span of time between the latest backup and a data loss event is called a recovery point objective (RPO). If the words don’t sound very much like their definition, that’s because someone worked really hard to couch a bad situation within a somewhat neutral term. If it helps, the “point” in RPO means “point in time.” Of all data adds and changes, anything that happens between backup events has the highest potential of being lost. Many technologies have some sort of fault tolerance built in; for instance, if your domain controller crashes and it isn’t due to a completely failed storage subsystem, you’re probably not going to need to go to backup. Most other databases can tell a similar story. RPOs mostly address human error and disaster. More common failures should be addressed by technology branches other than backup, such as RAID.
A long RPO means that you are willing to lose a greater span of time. A daily backup gives you a 24-hour RPO. Taking backups every two hours results in a 2-hour RPO. Remember that an RPO represents a maximum. It is highly unlikely that a failure will occur immediately prior to the next backup operation.
Recovery Time Objective
Recovery time objective (RTO) represents the maximum amount of time that you are willing to wait for systems to be restored to a functional state. This term sounds much more like its actual meaning than RPO. You need to take extra care when talking with backup vendors about RTO. They will tend to only talk about RTO in terms of restoring data to a replacement system. If your primary site is your only site and you don’t have a contingency plan for complete building loss, your RTO is however long it takes to replace that building, fill it with replacement systems, and restore data to those systems. Somehow, I suspect that a six-month or longer RTO is unacceptable for most institutions. That is one reason that DR planning must extend beyond taking backups.
In more conventional usage, RTOs will be explained as though there is always a target system ready to receive the restored data. So, if your backup drives are taken offsite to a safety deposit box by the bookkeeper when she comes in at 8 AM, your actual recovery time is essentially however long it takes someone to retrieve the backup drive plus the time needed to perform a restore in your backup application.
Retention
Retention is the desired amount of time that a backup should be kept. This deceptively simple description hides some complexity. Consider the following:
- Legislation mandates a ten-year retention policy on customer data for your industry. A customer was added in 2007. Their address changed in 2009. Must the customer’s data be kept until 2017 or 2019?
- Corporate policy mandates that all customer information be retained for a minimum of five years. The line-of-business application that you use to record customer information never deletes any information that was placed into it and you have a copy of last night’s data. Do you need to keep the backup copy from five years ago or is having a recent copy of the database that contains five-year-old data sufficient?
Questions such as these can plague you. Historically, monthly and annual backup tapes were simply kept for a specific minimum number of years and then discarded, which more or less answered the question for you. Tape is an expensive solution, however, and many modern small businesses do not use it. Furthermore, laws and policies only dictate that the data be kept; nothing forced anyone to ensure that the backup tapes were readable after any specific amount of time. One lesson that many people learn the hard way is that tapes stored flat can lose data after a few years. We used to joke with customers that their bits were sliding down the side of the tape. I don’t actually understand the governing electromagnetic phenomenon, but I can verify that it does exist.
With disk-based backups, the possibilities are changed somewhat. People typically do not keep stacks of backup disks lying around, and their ability to hold data for long periods of time is not the same as backup tape. The rules are different — some disks will outlive tape, others will not.
Rotation
Backup rotations deal with the media used to hold backup information. This has historically meant tape, and tape rotations often came in some very grandiose schemes. One of the most widely used rotations is called “Grandfather-Father-Son” (GFS):
- One full backup is taken monthly. The media it is taken on is kept for an extended period of time, usually one year. One of these is often considered an annual and kept longer. This backup is called the “Grandfather”.
- Each week thereafter, on the same day, another full backup is taken. This media is usually rotated so that it is re-used once per month. This backup is known as the “Father”.
- On every day between full backups, an incremental backup is taken. Each day’s media is rotated so that it is re-used on the same day each week. This backup is known as the “Son”.
The purpose of rotation is to have enough backups to provide sufficient possible restore points to guard against a myriad of possible data loss instances without using so much media that you bankrupt yourself and run out of physical storage room. Grandfathers are taken offsite and placed in long-term storage. Fathers are taken offsite, but perhaps not placed in long-term storage so that they are more readily accessible. Sons are often left onsite, at least for a day or two, to facilitate rapid restore operations.
Replacing Old Concepts with New Best Practices
Some backup concepts are simply outdated, especially for the small business. Tape used to be the only feasible mass storage device that could be written and rewritten on a daily basis and were sufficiently portable. I recall being chastised by a vendor representative in 2004 because I was “still” using tape when I “should” be backing up to his expensive SAN. I asked him, “Oh, do employees tend to react well when someone says, ‘The building is on fire! Grab the SAN and get out!’?” He suddenly didn’t want talk to me anymore.
The other somewhat outdated issue is that backups used to take a very, very long time. Tape was not very fast, disks were not very fast, networks were not very fast. Differential and incremental backups were partly the answer to that problem, and partly to the problem that tape capacity was an issue. Today, we have gigantic and relatively speedy portable hard drives, networks that can move at least many hundreds of megabits per second, and external buses like USB 3 that outrun both of those things. We no longer need all weekend and an entire media library to perform a full backup.
One thing that has not changed is the need for backups to exist offsite. You cannot protect against a loss of a building if all of your data stays in that building. Solutions have evolved, though. You can now afford to purchase large amounts of bandwidth and transmit your data offsite to your alternative business location(s) each night. If you haven’t got an alternative business location, there are an uncountable number of vendors that would be happy to store your data each night in exchange for a modest (or not so modest) sum of money. I still counsel periodically taking an offline offsite backup copy, as that is a solid way to protect your organization against malicious attacks (some of which can be by disgruntled staff).
These are the approaches that I would take today that would not have been available to me a few short years ago:
- Favor full backups whenever possible — incremental, differential, delta, and deduplicated backups are wonderful, but they are incomplete by nature. It must never be forgotten that the strength of backup lies in the fact that it creates duplicates of data. Any backup technique that reduces duplication dilutes the purpose of backup. I won’t argue against anyone saying that there are many perfectly valid reasons for doing so, but such usage must be balanced. Backup systems are larger and faster than ever before; if you can afford the space and time for full copies, get full copies.
- Steer away from complicated rotation schemes like GFS whenever possible. Untrained staff will not understand them and you cannot rely on the availability of trained staff in a crisis.
- Encrypt every backup every time.
- Spend the time to develop truly meaningful retention policies. You can easily throw a tape in a drawer for ten years. You’ll find that more difficult with a portable disk drive. Then again, have you ever tried restoring from a ten-year-old tape?
- Be open to the idea of using multiple backup solutions simultaneously. If using a combination of applications and media types solves your problem and it’s not too much overhead, go for it.
There are a few best practices that are just as applicable now as ever:
- Periodically test your backups to ensure that data is recoverable
- Periodically review what you are backing up and what your rotation and retention policies are to ensure that you are neither shorting yourself on vital data nor wasting backup media space on dead information
- Backup media must be treated as vitally sensitive mission-critical information and guarded against theft, espionage, and damage
- Magnetic media must be kept away from electromagnetic fields
- Tapes must be stored upright on their edges
- Optical media must be kept in dark storage
- All media must be kept in a cool environment with a constant temperature and low humidity
- Never rely on a single backup copy. Media can fail, get lost, or be stolen. Backup jobs don’t always complete.
Hyper-V-Specific Backup Best Practices
I want to dive into the nuances of backup and Hyper-V more thoroughly in later articles, but I won’t leave you here without at least bringing them up.
- Virtual-machine-level backups are a good thing. That might seem a bit self-serving since I’m writing for Altaro and they have a virtual-machine-level backup application, but I fit well here because of shared philosophy. A virtual-machine-level backup gives you the following:
- No agent installed inside the guest operating system
- Backups are automatically coordinated for all guests, meaning that you don’t need to set up some complicated staggered schedule to prevent overlaps
- No need to reinstall guest operating systems separately from restoring their data
- Hyper-V versions prior to 2016 do not have a native changed block tracking mechanism, so virtual-machine-level backup applications that perform delta and/or deduplication operations must perform a substantial amount of processing. Keep that in mind as you are developing your rotations and scheduling.
- Hyper-V will coordinate between backup applications that run at the virtual-machine-level (like Altaro VM) and the VSS writer(s) within guest Windows operating systems and the integration components within Linux guest operating systems. This enables application-consistent backups without doing anything special other than ensuring that the integration components/services are up-to-date and activated.
- For physical installations, no application can perform a bare metal restore operation any more quickly than you can perform a fresh Windows Server/Hyper-V Server installation from media (or better yet, a WDS system). Such a physical server should only have very basic configuration and only backup/management software installed. Therefore, backing up the management operating system is typically a completely pointless endeavor. If you feel otherwise, I want to know what you installed in the management operating system that would make a bare-metal restore worth your time, as I’m betting that such an application or configuration should not be in the management operating system at all.
- Use your backup application’s ability to restore a virtual machine next to its original so that you can test data integrity
Follow-Up Articles
With the foundational material supplied in this article, I intend to work on further posts that expand on these thoughts in greater detail. If you have any questions or concerns about backing up Hyper-V, let me know. Anything that I can’t answer quickly in comments might find its way into an article.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


47 thoughts on "Hyper-V Backup Best Practices: Terminology and Basics"
I might be wrong here but I think your terminology is backwards for incremental vs differential. Differential includes all that is different from the last FULL backup. Incremental includes all that is different from the last backup of any kind… Thus the “increments” are assembled during restore.
So, I just experienced that wonderful moment when you realize that one tiny mistake in your notes has more or less ruined an entire article. I knew better, of course, but, “I wouldn’t lie to myself in my own notes, would I?” Apparently, yes, I would.
You are right, I am wrong, and I’ll fix my article.
Thank you!
“If you feel otherwise, I want to know what you installed in the management operating system that would make a bare-metal restore worth your time, as I’m betting that such an application or configuration should not be in the management operating system at all.”
I’ve got one for you 🙂
Network UPS Tools’ (NUT) USB driver can’t work from within a Hyper-V VM, so it must be installed and configured on the host. This isn’t a severe enough scenario that it requires a backup of the OS, but it is at least a process that must run on the host.
However, I’m currently investigating the possibility of doing this within a Docker container (new technology w/2016). If successful, this would ease the setup task significantly.
Thanks,
Jeff Bowman
Fairbanks, Alaska
I don’t know of any physical hosts that can be deployed without a process. The line isn’t drawn there. The line is best drawn at level of effort. If I’m looking at, say, 5 Hyper-V hosts and decide that it’s easier for me to maintain 5x BMR backup processes than a single WIM with injected drivers and install files, then I need to take a hard look at simplifying something.
Sorry man, but your description of incremental/differential backups is straight opposite to the industry embraced terminology meaning. From my view, this dramatically lessens the value of your whole story. Personally, I just stopped reading the article remainder after I have carefully re-read the incremental/differential part several times thinking that it might be just my own understanding issue.
I saved your article for later reading, and haven’t seen that another backup knight already pointed you to the terminology confusion and you have already corrected the article. Thanks, and sorry for the above comment.
Hyper-V restore may fail if the VM was created on a CSV and the CSV is a reparse point on the destination drive