Save to My DOJO

Most modern businesses need to operate twenty-four hours a day and every day of the week to generate revenue and keep their customers happy. No matter how well these organizations plan to maintain continuous service availability, downtime is inevitable and can happen for many reasons, including security attacks, IT errors, internal sabotage, or even natural disasters that could destroy a power grid or shut down a datacenter. Having local backups within your site may not be sufficient in the event that you lose access to the entire datacenter, so having a secondary location for disaster recovery is always recommended. The IT department must be proactive in developing a plan to detect and recover from a variety of unexpected events as a part of their business continuity planning, first within the local datacenter and then across sites. The main concepts that we will discuss in this blog post are the recovery point and recovery time.
The Recovery Point Objective(RPO) can be used to quantify the amount of the data which is acceptable to lose in a disaster, while the Recovery Point Actual (RPA) measures the real data loss when this happens, which is usually based on the data lost between the failure and when the last backup was made.
The Recovery Time Objective(RTO) is a goal for how long should take from when an outage begins until it is detected and the service is restored, and the Recovery Time Actual (RTA) is the real-time that it takes to failover the service or restore a backup and bring services online after a failure. While the goal is to get both of these values as close to zero as possible, usually some data loss will happen and recovery time is generally measured in minutes or hours. Every service for every business is different, so these values will vary based on the importance of each application to that business.
The following diagram shows the recovery timeline when a failure happens. Backups are being taken at regular intervals, and the time between the failure and the last backup shows the Recovery Point Actual (RPA). The time between the failure and when the services are back online, show the Recovery Time Actual (RTA). The overall duration between the most recent recovery point and the end of the recovery time shows the overall failure impact.
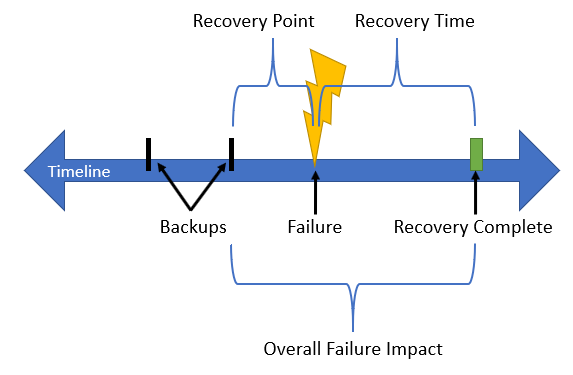
Figure 1: Understanding the Recovery Timeline after a Failure
Defining the Recovery Point Objective
Since each industry, company, and application has different needs for data availability and integrity, this impacts the RPO for that service. For example, a stock trading company would find it unacceptable to have any data loss for its financial transactions, so RPO is zero, whereas it may also have a backend service that creates monthly reports, and this may allow for a few hours of downtime, with an RPO of 4 hours.
Sometimes the RPO will vary based on the time of day, day of the week, or even the month, such as if your services are only active during weekday trading hours or if you run a seasonal business. The IT department has to collaborate with other business units to define the RPO, but remember that this is only a goal, and actually accomplishing a full recovery while losing that amount of data (or less) is measured by the Recovery Point Actual (RPA).
If no data loss is acceptable, then the organization likely has to find a solution with synchronous replication between the primary data source and a mirrored instance. This means that as soon as any data is written to the primary location, it is immediately copied to a secondary location, and an acknowledgment is returned to the primary before the data is committed to ensuring that the information is consistent at both sites. These solutions are expensive and the distance between sites is usually limited to a few miles to prevent a performance impact.
If some data loss is acceptable, then there are multiple solutions available, including asynchronous replication and traditional disk backups. Asynchronous replication means that data is sent to the secondary site at regular intervals, and some popular solutions include Microsoft’s Hyper-V Replica or VMware’s vSphere Replication. If you only have a single datacenter, do not worry, you can still back up to a secondary location by taking advantage of the public cloud using technologies like Microsoft’s Azure Site Recovery or Azure Cloud Backup.
If the solution involves taking backups, which is most common, then the frequency of the backup is the most critical component. If backups are taken every hour, then up to an hour of data could be lost, depending on when the crash happens. While you may think that you should just take backups every minute (or second) to reduce the RPO and data loss, keep in mind that there is a cost associated with taking more backups.
Each backup consumes more disk space and server resources, so your virtualization hosts may have to run fewer VMs than they could at full capacity during a backup cycle. Backup companies have developed some technologies to optimize these challenges such as deduplication to save storage space, and incremental or partial backups to minimize the performance hit when backups are taken. For example, Altaro VM Backup helps organizations optimize how their backups are taken and stored by using the very technologies mentioned above.
Defining the Recovery Time Objective
When an organization defines their RTO, they need to consider the entire duration which it takes to discover the outage and bring services back online. This includes the time to detect that the service is offline or that data is being lost, the time to begin the recovery, the time to test that the recovery worked and the data is consistent, the time to restart any services in the correct dependency order, and the time that it takes for clients to be able to reconnect.
It is a best practice to automate as many of these steps as possible, as any manual tasks performed by humans will slow down the recovery. If human intervention is required, then you must also consider the time it takes to alert the staff (including overnight, on weekends, or holidays), drive to the datacenter and execute the recovery tasks. Also, consider that datacenter access may not be possible or safe if there is a natural disaster like a hurricane or flood, so providing a remote access solution is critical in the planning.
The two most common reasons why disaster recovery plans fail is because of a lack of testing and a dependency on humans, so it is critical that you test your recovery so that you can calibrate the RTO with the Recovery Time Actual (RTA). You can optimize your RTO through a variety of infrastructure optimizations, such as having fast recovery disks, high bandwidth recovery networks that prioritize that traffic using quality of service (QoS), and trying to restore from the local site first before recovering from a remote site. Additionally, there are many software solutions to speed up recovery time through high-availability so that the software will automatically detect a crash and restart the service, such as Windows Server Failover Clustering or VMware HA.
Ongoing Recovery Management
Disaster recovery planning must be a regular task for every organization a part of their standard operating procedure to ensure that they meet their RPO and RTO. Each time you change or update your applications, servers, networks, or storage, it can impact service availability and change your RPA and RTA.
Also, make sure that the recovery process is well-documented so that the knowledge (Recovery Time Objective, Recovery Point Objective…etc) can be passed on to future staff. Some well-recognized standards to provide further guidance include the International Organization for Standardization’s ISO/IEC 27031, “Guidelines for information and communication technology readiness for business continuity” and the National Institute of Science and Technology’s Special Publication 800-34, “Contingency Planning Guide for Federal Information Systems”. Stay tuned for another Altaro blog post where we will provide you with the best practices for scheduling backups to optimize your RPO and RTO.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Symon Perriman

