Proceeding from a deep dive on the graphical tools, the logical next step is to become acquainted with the capabilities of the much more versatile PowerShell in interacting with and controlling Hyper-V.
During the tours of Hyper-V Manager and Failover Cluster Manager, you saw nearly every single control and screen that they have; there isn’t much left that they can do. Conversely, the extent of PowerShell’s domination of both Hyper-V and Failover Clustering is so vast that no single book could come anywhere near covering it all.
Rather than chasing the unattainable, this article will aim for two much more realistic goals:
- It will explain the value proposition of PowerShell with an emphasis on when it is a superior choice to the graphical tools.
- It will guide you to a position from which you can easily expand your own knowledge with only minimal external assistance.
The Case for PowerShell and Hyper-V
PowerShell was introduced to the world in late 2006. It struggled to gain acceptance among the administrative community. It was unfamiliar to everyone, and, as a text-based tool, was especially foreign in the Windows world where the mouse reigned supreme. Its applicability was something of an unknown, which made it difficult for many to understand what it offered that wasn’t already available.
Despite these barriers, PowerShell enjoyed very vocal supporters and a development team that rapidly expanded its scope and capabilities. The PowerShell that’s available today is both robust and approachable. Many technologies, even those by entities other than Microsoft, have thoroughly integrated it. If you’re not certain how to do something, there’s a good chance that someone else has published a solution that’s no more than an Internet search away.
Of course, all of that is in a generic sense. Hyper-V and PowerShell have their own special relationship. With that comes a number of selling points for PowerShell that Hyper-V administrators cannot afford to ignore.
1. PowerShell is How It’s Done
Hyper-V is a technology that simply cannot be fully exploited without using PowerShell. Hyper-V Manager, while certainly capable, just doesn’t expose all of the hypervisor’s functionality. The networking components are a perfect example.
Only PowerShell can create more than one virtual adapter for the management operating system. Only PowerShell can configure Hyper-V’s networking Quality of Service. Only PowerShell can set a virtual adapter in trunk mode or work with private VLANs.
2. PowerShell Makes It Easier
When you’re performing a new or an uncommon task, the GUI is usually superior. It’s much easier to find things when they’re right in front of you and GUIs are better at notifying the operator when something isn’t quite right, especially when he or she wasn’t specifically looking for a problem.
As you become more familiar with Hyper-V and Failover Clustering, their GUIs can quickly become restrictive. You may find yourself performing the exact same tasks on a routine basis. That wizard that once seemed so nice and friendly becomes an interminable parade of clicks when you are faced with the task of making a similar change to twenty virtual machines. Some items are buried deep in nested windows. There are others that you almost remember the location of, but have to spend a bit of time looking in the wrong places. It becomes annoying to create a virtual machine with default settings and then override those default settings.
PowerShell solves all of these problems. Procedures can be saved in .PS1 files and kicked off quickly. Scripts can be scheduled. Cmdlets can be discovered using wildcards. Parameters exploit tab completion. Lists of virtual machines can be fed through a command like an assembly line. Someone out there has likely already written a script to do what you want to do, so it’s just a matter of finding it.
Following the work of others is easier in PowerShell as well. When you first encounter a few lines of script, they can be intimidating. As familiarity increases, scrolling past dozens of screenshots of dialog boxes and wizard pages that you can’t copy and paste from quickly becomes less appealing.
3. PowerShell Is Everywhere
Microsoft rolled PowerShell into all server products quite some time ago, and each new version expands its capabilities. Many graphical server management tools send everything through PowerShell; notable members of this group are the Microsoft Exchange Management Console and System Center Virtual Machine Manager. Anything that can be done in the interface can be done in PowerShell, and can often be done more quickly.
4. PowerShell from Anywhere
If you haven’t already jumped on the PowerShell bandwagon, how are you managing your servers now? Do you use Remote Desktop? Are you connecting the graphical tools remotely? How well do those things work? Did you run into firewall problems? Do you have to use a version of Windows that you don’t especially like just because the Remote Server Administration Tools have to be the same level as the target or higher in order to fully manage it? Do you struggle with performance issues when you’re trying to work on your servers across a slow off-site link?
PowerShell has an extremely powerful feature with an equally extremely boring name: “Remoting”. What the name lacks in zing it more than makes up for in capability.
- Standards-based: PowerShell Remoting utilizes web services management, commonly known as “WS-Man”, for communications. This is a standard that’s defined and managed by the Distributed Management Task Force (DMTF). You can read more about WS-Man and DMTF at the official site.
- Security: PowerShell Remoting traffic is always encrypted by default. If you believe that the built-in encryption is insufficient, you can further encapsulate it in an SSL tunnel. Furthermore, both the client and the server in a PowerShell Remoting conversation must authenticate to each other.
- Version independence: The client and the server must both be running at least PowerShell 2.0 as that was the version that introduced Remoting. They do not need to be running the same version.
- Network-friendly: For the average session, very little data traverses the wire.
- Durability: A session that’s disconnected remains active. If you’re connected to your VPN over an unstable remote link, your work won’t be lost when the line drops.
- Remote object manipulation: You can bring the objects that you’re working with on the server down to your local computer for processing or storing. As a very simple example, you can retrieve a list of settings from a remote computer and filter them through a process on your local system to populate an Excel spreadsheet, all without leaving the PowerShell prompt.
- One-to-many: A single PowerShell session on the computer you’re sitting at can be used to remote to several systems simultaneously. Issue a single command to all the hosts in your datacenter quickly and easily.
5. Reusability
The focus in this article is going to be using PowerShell interactively, which means that you’ll give PowerShell an instruction, get some feedback, use that feedback to formulate another instruction, and so on.
Of course, PowerShell is also a complete scripting language, so you can quickly save a .PS1 file with a set of instructions and re-use it at any time. As Jeff Hicks, PowerShell MVP, has been known to say, “Those who forget to script are doomed to repeat their work.” If the odds are that you’ll ever need to perform a specific task again, it’s probably worth scripting at least some of it.
If you just have small little one-liners that you use on a regular basis, you can save them in OneNote and paste them into the PowerShell prompt. As you become more proficient, you can turn to more powerful tools.
The first that you’re likely to use is the PowerShell Integrated Scripting Environment (ISE) which is included on all graphical editions of Windows and Windows Server. It grants you the ability to save your scripts, auto—complete key words, “snippets” to automatically insert common pre-fabricated script, and other valuable features. It is highly extensible through add-ons; a collated list is maintained on a TechNet wiki. Visual Studio Community Edition 2015 includes a PowerShell Tools add-in and can be downloaded at no charge. As a full development environment, it grants more capabilities than the ISE and integrates with version control systems. You can directly save your scripts online and work on them with up to four other people at no charge on Visual Studio Online.
How to Get Started with PowerShell and Hyper-V
If you’ve never run PowerShell before, the first thing to do is learn how to kick it off. Starting with Server 2008 R2, there’s been an icon included on the taskbar. Clicking it will open it as the current user. If you want to run it with elevated privileges, you have to right-click on it and choose Run as Administrator.
If you’re running Server Core or Hyper-V Server, then you just have to type PowerShell at the command prompt and press Enter. Of course, this works just as well from a standard command prompt and the Run dialog in GUI editions as well.
If you haven’t got the PowerShell module for Hyper-V loaded (2012+), then the first thing you’ll want to enter is the following:
Add-WindowsFeature -Name RSAT-Hyper-V-Tools
This installs the Hyper-V PowerShell module. Use the following for the Failover Clustering module:
Add-WindowsFeature Name RSAT-Clustering-PowerShell
Using PowerShell to Learn About PowerShell
PowerShell has an extremely robust help system that became even more powerful in version 3. Starting with that version, you have access to an impressive array of built-in options using nothing but your Internet connection. Enter the following:
Update-Help
Every registered module and cmdlet on your system that has been designed with an update URL will retrieve the most recent help information and place it on your system. All it takes from there is a simple:
Get-Help
PowerShell help has a number of entries that can help you learn about PowerShell’s innate capabilities. Enter the following:
Get-Help about_
Press Tab after the underscore, and you’ll cycle through all the available entries. Read about anything that interests you.
Get-Help can be used with literally any function or cmdlet. At the very least, it will show you acceptable syntax and usage, even if there was no downloadable help. For those that do have detailed information, there is much more to be discovered.
Learning More About a Cmdlet
All of the built-in cmdlets have their own help that’s easily retrieved.
Get-Help Get-VM
This shows a short listing of help that is usually good enough to give you a quick idea of what the function does and its usage. If you want more information, you can use:
Get-Help Get-VM -Full
Let’s look at a shortened syntax output for Get-VM:
SYNTAX Get-VM [[-Name] <String[]>] [-ComputerName <String[]>] [<CommonParameters>] Get-VM [-ClusterObject] <PSObject> [<CommonParameters>] Get-VM [[-Id] <Guid>] [-ComputerName <String[]>] [<CommonParameters>]
What you see here are three different parameter sets for the Get-VM cmdlet. What that means is that there are three mutually exclusive ways you can use this cmdlet.
Brackets around an object mean that it is optional. In the first parameter set, everything is optional. That means if you run the cmdlet all by itself, it will attempt to do something. The parameters modify how it takes that action. When the brackets are around the parameter name itself, that means that it is positional.
So, for Get-VM, if any string is passed in as the first parameter, it will assume that it is the name of a virtual machine and it will attempt to locate it. If a GUID is submitted, it will assume you’re using the third parameter set and process your request that way. The ClusterObject parameter in the second parameter set does not have brackets around the parameter name, so even though the parameter itself is optional, you must specify –ClusterObject if you intend to submit that type.
Doing Things Quickly
One of the biggest impediments to jumping into PowerShell is all that typing. Fortunately, you don’t have to do nearly as much as you might think just from reading others’ scripts.
Aliases
The first thing to talk about is aliases. These are shorter ways to run common functions and enter common parameters. You won’t see these as often in published scripts because they impair readability. Their purpose is to reduce typing. If you want to see a list of these, just run:
Get-Alias
One that you’ll see very commonly is “foreach”. This is an alias for “ForEach-Object”. It’s what you’ll use when you want to step through multiple objects using a single function. These are usually not simple functions, so we won’t show an example right now. If you haven’t seen one already, you will.
Other aliases you’ll see and use a lot are “fl” and “ft”. They stand for “Format-List” and “Format-Table”, respectively. These are used for controlling output. So, if you run Get-VM, you get something like this:
| Name State CPUUsage(%) MemoryAssigned(M) Uptime Status —- —– ———– —————– —— —— svdc1 Running 19 1156 15.23:02:33 Operating normally |
This is a pre-defined format. Using the format commands, you can see other properties. Normally, we want to see all properties, so you might use this:
Get-VM | Format-List -Property *
This will show everything. You’ll use this often enough that you can shorten it to just fl:
Get-VM | fl -Property *
The asterisk means “all”, but you don’t have to request all, if you don’t want to:
Get-VM | fl -Property Name, Uptime
Positional Parameters
Some parameters are used so often that it would be more convenient if you didn’t have to type them at all. Let’s start with the last example from the previous section. Most of the time when you’re formatting something, you want to look at specific properties. So, you don’t have to type –Property (as mentioned in the preceding section, this parameter’s name will have brackets around it in Get-Help). If you don’t specify a parameter name, then Format-List assumes that the first thing you give it is a list of properties that you want to retrieve. The following does exactly the same thing as the previous:
Get-VM | fl Name, Uptime
A great many functions have positional parameters. Remember to use Get-Help to discover them.
Tab Completion
The quickest way to save typing is by using tab completion. This wonderful gem is always active. Enter as many characters for a function, cmdlet, parameter, option, path, or filename, and press TAB to let PowerShell figure out what you want. If it doesn’t get it the first time, keep pressing TAB. To try it out, type in “Get-V” and press TAB a few times.
One of the most useful applications for tab completion is parameters. It’s hard to remember all of them, especially for functions you just discovered. After a function, enter a hyphen and press TAB to cycle through all available parameters. If you know part of the name, type as much as you know and press Tab.
Seeing What Commands are Available
The other issue with PowerShell is getting your head around everything that’s available to you. There’s a lot out there and the content is expanding constantly. If you really want to see it all, just run:
Get-Command
Long before it stops scrolling, you’ll have an idea for just how much there is. To trim the list a bit:
Get-Command -Module Hyper-V
Do you want to see cmdlets that are just for Hyper-V Replica?
Get-Command -Module Hyper-V -Name *replica*
This won’t always work as expected. Sometimes cmdlets don’t include a name component that’s so easy to filter against. What you can always do is see what modules are there so you can figure out how to control certain technologies:
Get-Module -ListAvailable
The Pipeline
One of the major strengths of PowerShell is its “pipeline”. It’s not exactly easy to explain or understand, especially if you don’t have a programming background. The simplest explanation is that many functions generate objects. Everything you’ve seen so far is just a single line, so the last place for an object to go is to the screen. What you’re actually looking at in that case is a formatted text view of an object.
In cases where the screen isn’t the final destination, the object from one cmdlet can be operated on by the receiving tool. For instance, Get-VM returns one or more virtual machine objects. The pipeline allows you to transfer that object directly into another function or cmdlet. If there aren’t any more, then the object is delivered to whatever output item there is. Since we’re talking about executing PowerShell inside a visible screen, then that’s where the output will go. Let’s look at a practical example:
Get-VM | Start-VM
The | is called the “pipe” character, so it makes perfect sense that it’s how you invoke the pipeline. What happened here is that Get-VM emits one or more virtual machine objects. These are passed to Start-VM. If you look at Start-VM’s help, you’ll notice that one of its syntax lines is:
Start-VM [-VM] <VirtualMachine[]> [-AsJob] [-Passthru] [<CommonParameters>]
The first item here is a “VirtualMachine” object, which is exactly what Get-VM is emitting. If you check further down in Start-VM’s help (use -Full), you’ll find the expanded description for the VM parameter, it has the entry:
Accept pipeline input? true (ByValue)
This means that it accepts piped objects. The “ByValue” portion means that it will automatically match on a piped “VirtualMachine” object. Piped parameters can also be matched by name, although that is less accurate.
How to Enable Your System to Run PowerShell Scripts
By default, you can’t operate any script files (.PS1). In order to modify this behavior, you’ll need to change the execution policy for the system. The purpose of preventing script execution is based around the idea of security; if you can’t run a script, it can’t harm your system. There are numerous policy settings, and all of them besides the default of Restricted lower the overall security of your system. These are your choices:
- Restricted: You can only operate PowerShell from the command line and you can only use compiled modules.
- AllSigned: You can operate scripts that have been digitally signed by a trusted publisher.
-
RemoteSigned: You can operate unsigned scripts that are not marked as being from another computer. You might recognize this indicator when you see the following display in Windows Explorer:
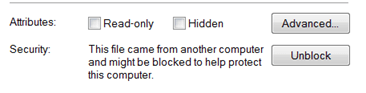
If you unblock the file, it will run.
- Unrestricted: All scripts will run, but you’ll be prompted if you run a file that’s marked as blocked.
- Bypass: All scripts will run without prompting.
There is currently a debate over the efficacy and value of these security restrictions. The simplicity involved with removing the “remote” block from a file lowers its usefulness. Regardless of the execution policy, a script can only operate within the security context of the user that initiated it. Even if the user is an administrator, the prompt must be run in elevated mode to carry out functions that require such elevation. A good middle ground to choose is RemoteSigned. This will prevent you from accidentally operating scripts that you haven’t at least had an opportunity to look at.
To set the execution policy for a system:
Set-ExecutionPolicy Policy RemoteSigned
How to Allow Remote PowerShell Sessions
By default, you must be working at the local system to operate in PowerShell at all. PowerShell has a “Remoting” mode in which you can use PowerShell on one system to connect into PowerShell on another and operate mostly as if your presence was local. As with script execution, this feature is disabled by default. To turn it on, run the following on the remote and the controlling machines:
Enable-PSRemoting -Force
Next Steps
Out of necessity, this introduction has been nothing more than a very basic primer. Taking you through a detailed tour of every single Hyper-V and Failover Clustering cmdlet in the same fashion as the GUI tools would take substantially more time and would not leave you with a significant amount of functional knowledge that you couldn’t attain on your own.
The very first thing to do is get a list of the cmdlets in each module and start learning how to map what you know about the GUI to PowerShell:
Get-Command –Module Hyper-V, FailoverClusters
You can copy and paste the output into a text or Excel file, if you like. You can even create self-documenting output with the following:
Get-Command -Module FailoverClusters, HyperV | select Name | ExportCsv Path C:\temp\PSCommands.txt NoTypeInformation
With this handy reference, start using Get-Help, or if you’re feeling brave, the actual cmdlets with tab completion. As a general rule, Get- cmdlets don’t hurt anything on their own, so feel free to explore. See how well you can match what you saw in the GUI articles to what PowerShell can do.
The next thing to do is review Jeff Hick’s “10 Awesome Hyper-V Cmdlets” article on this blog. It shows a number of very common, practical cmdlets you can use in day-to-day operations. Play around with your newfound knowledge. For instance, Jeff shows you how to use Get-VMNetworkAdapter using parameters. Try piping in virtual machine objects instead.
In later articles in this series, PowerShell will be presented without much preamble. Scripts won’t be overly complicated, but they’ll be the first choice over GUI instructions, especially in situations that are likely to be repetitive or tedious. It’s worth your time to get a head start here by centering yourself based on the material shown here.
More PowerShell Resources
As promised, we’ll be focusing on the short and simple of PowerShell. It can certainly become quite complicated, as PowerShell is a complete language in its own right and could certainly be used to develop an entire script-based application, if one were so inclined. If you’re interested in gaining that level of knowledge, there are a number of fantastic resources available. Here are a few:
- Learn Windows PowerShell in a Month of Lunches, 2nd Edition by Don Jones and Jeff Hicks.
- PowerShell in Depth, 2nd Edition by Don Jones, Jeff Hicks, and Richard Siddaway.
- MSDN has published an online tutorial.
- Use your favorite RSS client and add the Scripting Guy’s blog. There are a combination of long articles and really quick solutions.
- Investigate online communities and resources such as PowerShell.org and PowerShell Magazine.
PowerShell is a technology that is not going away. For Hyper-V especially, it’s not possible to build anything more than the simplest deployments without it.
If you use Hyper-V: Here are 25 Free Scripts for you to get started with PowerShell
If you use VMware: Here are 25 Free Scripts for you to get started with PowerCLI



