Save to My DOJO
Update: Atlaro Backup Software now comes with full 24/7 support across all our products at no extra cost! Our support promise is to be available for all our customer needs round the clock, with a guaranteed 24/7 call response of less than 30 seconds direct to a product expert – no entry-level agents or passing you around. Find out more about our outstanding customer support
Update: Altaro Backup v8 has now been released – find out about the newest features
It’s a new year, and with it comes a new version of Altaro VM Backup! As mentioned in our launch blog post, we have just released version 7 of our flagship backup and recovery software for Hyper-V and VMware, which includes several enhancements and new features such as Boot from Backup and support for Windows Server 2016.
One feature however that we felt deserving of its own blog post was our new Augmented Inline Deduplication technology.
That’s what I’ll be talking about in this post today.
Quick Intro to Deduplication
Deduplication is a technology that is often synonymous with backup and DR software. For those that aren’t aware, the basic premise of deduplication is that no block of data is stored more than once. For example, if I have two copies of an application dataset on a file server, without deduplication there are two copies of that data contained within my backup repository as well.
I only need one copy of it to successfully recover the file, why should I store it twice in my backup repository?
This is where deduplication technology comes into place.
If you take a look at backup vendors throughout the industry, you’ll find deduplication to be a fairly common thing. However, with deduplication you’ll find that the details and the underlying mechanics are important and play a role as to how well the feature works. Before I get into how Altaro’s new Augmented Inline Deduplication technology works, let’s talk briefly about where we’ve been.
Reverse Delta
Pre-version 7, we used technology within our product stack called Reverse Delta, and while not specifically named deduplication, it served the same purpose. Every time a backup would occur, we would place the most recent data set in the most recent backup file, while compressing and deduping older data for that server into smaller delta files for historical backups. (Below)

While this worked well, there were some drawbacks. The main one being, we could only remove like copies of data on a per VM basis. So, let’s go back to our example above in that you have two copies of an application dataset, but instead of them being on the same file server, let’s say they’re on different servers that are both being backed up.
Our pre-version 7 reverse delta technology would have stored two copies of that data in the backup repository. This not only increased the amount of time needed to complete a backup, it consumed more storage.
This one of the key reasons for developing a better solution for our customers and Partners!
Augmented Inline Deduplication
We’re proud and happy to be able to bring to you this new Augmented Inline Deduplication technology built into Altaro VM Backup.
Not only is it quicker for backup operations, it is far more efficient for storage as well in that it will dedupe data across all your backed-up workloads. Whereas before with Reverse Delta, we were completing this process on a per VM basis, with our new Augmented Inline Deduplication feature, we’re storing backups in a central repository and using a hash database to keep track of the deduped blocks. (Below)
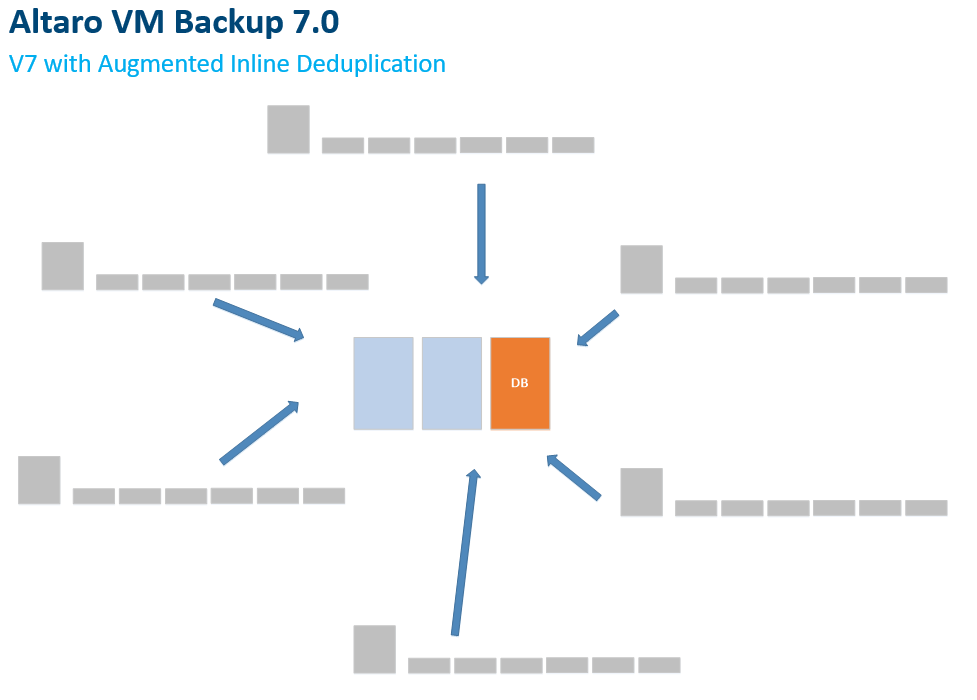
Not only does this method make it so you’re only storing one copy of each block, it also becomes more efficient with each new workload you add to the solution! Remember, there are similar files and data within the operating system of each server. If you have 10 Windows Server 2012 R2 machines, you’ll only have to backup 1 copy of the similar OS related files for all the protected VMs.
It’s also worth noting that this process occurs inline, and does NOT happen as a post process job. However, before I go too much further on that, maybe a small definition is in order to further show the differences between inline deduplication and post-process deduplication:
- Post-Process Deduplication – All data is backed up and sent to the backup repository. Once the job is complete, and new deduplication job occurs that looks at the data in the backup repository and removes like blocks.
- Inline Deduplication – Data is analyzed and compared to the backup repository prior to the backup process to ensure that identical blocks are not sent to the backup repository to begin with. This is the type of deduplication that our new Augmented Inline Deduplication technology is based off of.
If you compare these two types of deduplication technologies, it will quickly become apparent that post-process is the least efficient of the two.
Not only are you sending data over the wire that doesn’t need to be sent, you’re also having to parse and analyze the data after the fact as a second job to remove the like blocks. Talk about creating more work than what is needed!
As a result, using the inline method on our Augmented Inline Deduplication technology, Altaro VM Backup customers benefit from:
- Blazing fast backups
- The best backup storage savings in the industry

Wrap-Up
If you’re interested in seeing what our Augmented Inline Deduplication technology can do for your organization, feel free to download our full-featured 30-day trial. There is no obligation and it’s simple to setup and test within your environment. This will give you a good idea of how the solution will stack up in your environment and even give you a little bit of a feel for how much more efficiency you can gain from our new deduplication technology.
As always, if you have any questions or comments, feel free to submit them below, and don’t forget, we’ll be providing a highly detailed whitepaper on this feature soon for more detail!
Thanks for reading!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Andy Syrewicze


10 thoughts on "New in Altaro VM Backup v7 – Augmented Inline Deduplication"
Andy,
What happens if you have an offsite copy defined for only one of a number of backed up servers? Presumably you get that de-duplicated data in the offsite location, do you only get the data relevant to that server or is it part of a whole ‘database’?
What if there is a bad block on the media where you have that de-duplicated data stored? If it is the OS files that get affected by that bad media presumably you now have multiple servers that you can’t recover?
Sorry to be negative as it sounds like a great technology, but I would like to understand if there are any limitations, I’m sure you have got this covered.
Thanks
Hi Jonathan!
No worries at all, happy to help answer any questions!
There are different Dedupe repositories on the local and offsite backup locations. So all the needed data to facilitate full
recovery of a VM will be sent to the offsite location, and a different dedupe process will be conducted during the offsiting
process. This is useful in that if you have multiple sites offsiting to a single offsite location, all those workloads
are deduped in the offsite location as well.
As for your question on bad blocks… you are correct, if a deduped block turns sour for whatever reason, you could lose the
ability to recover several VMs, however in the near future we will be introducing automatic scheduled verifications jobs to help
catch this ASAP, and we’ll also be adding automatic recovery from drive corruption as well. In the meantime we highly recommend
you:
1. Have an offsite backup
2. Run scheduled sandbox restores once a week
3. Make sure you use reputable storage for your backup location with fault tolerant RAID if possible.
If you want more info on this stuff, we’ll be coming out with a very detailed whitepaper on the dedupe topic in the coming weeks.
Hi Andy, first let me notice that we use and resell Altaro VM Backup (ex-Hyper-V Backup) since v4. We’ve started using v7 and we’re amazed by the global performance of each backup job and by the savings (bandwidth, storage), but also by the low consumption of ressources on the hosts. I’m very curious about technical details about what’s under the hood. Is this “very detailed whitepaper on the dedupe topic” white paper already available to read? One more question: is there any chance to have in the future the ability to run parallel backup jobs on a single host? Thanks and what a great job has been achieved by Altaro!
Hi Alexis! Sorry for the late response on this.
First off, I’m glad you’re a long time user and that the software is working well for you!
The whitepaper regarding the detailed architecture of our deduplication engine is still pending as we’ve been quite busy with v7 and further improvements. With that in mind, regarding your other question. Concurrent backups is something that our devs have been actively working on, and is in our roadmap. Expect to see it in an update in the very near future!
Stay tuned for the dedupe whitepaper!
The prior version of Altaro would have a reverse Delta that would be saved at least every X number of days (default 30 days). I believe what this meant was that a full backup would be needed at every point in which the limit was set to. This would also contribute to large backup sizes especially if you keep backups for a long period of time. How does the new backup mechanism handle this? I don’t see a configuration option to set this sort of limit within the new interface. Thanks.
Hi Bill! Apologies for the late response!
We’ve actually got a whitepaper in the works that will address some of these questions in the coming weeks and provide a nice in depth look at how the new dedupe engine works. Stay tuned for that!
Is the automatic scheduled verification feature in the product yet ?
I am paranoid about having bad sectors on my backup storage drives.
In previous versions I could change how frequently Altaro did a FULL backup -> default was 31 days. I often changed it to 2 weeks at most of my sites. I no longer see this feature to alter the interval when a FULL occurs. If I set my retention policy to 6-9-12 months, that is a helluvalot of faith to put into a lone FULL backup. So much backup history could be unavailable if something happened to the FULL. This a big omission in v7 in my opinion, so much so that I will cease upgrading my v6 sites until I am comfortable with how v7 operates on the 2 sites I have currently on v7.
Hi Andy! Sorry for the late response on this.
We haven’t seen any major corruption issues with our new deduplication methodology, but as you mentioned it’s best to be as safe as possible and we totally get it that people want extra assurances. With that said, Automatic Scheduled Verification is something our devs have been working on. It’s on our roadmap and should be coming in an update in the very near future.
Hope that Helps!
Is your inline de-duplication source side? Or target side?
Hi Mike,
The inline deduplication happens on the source side to minimize the amount of data which is transferred over the network to the source. This works the same way when backing up to Microsoft Azure in the latest release.
Best,
Symon Perriman
Altaro Editor