Save to My DOJO

Anyone who has ever had to replace a hard disk because their old disk was simply too small to accommodate all of their data understands that there is a direct cost associated with data storage. In an effort to reduce storage costs, many organizations turn to data reduction technologies such as deduplication and compression.
What is Deduplication?
Data deduplication is a technology for decreasing physical storage requirements through the removal of redundant data. Although deduplication comes in several forms, the technology is most commonly associated with backup applications and associated storage.
Storage volumes are made up of individual storage blocks containing data (although it is possible for a block to be empty). Deduplication works by identifying blocks containing identical data and then using that information to eliminate redundancy within the backup.
Imagine for a moment that you needed to back up a volume containing lots of redundant storage blocks. It does not make sense to back up what is essentially the same block over and over again. Not only would the duplicate blocks consume space on the backup target, but backing up redundant blocks increases the duration of the backup operation, as well as the amount of bandwidth consumed by the backup process (which is an especially important consideration if you are backing up to a remote target). Rather than backing up duplicate copies of a storage block, the block can be backed up once, and pointers can be used to link data to the block on an as-needed basis.
There are three main ways in which the deduplication process occurs. First, deduplication can occur inline. Inline deduplication is a process in which data is deduplicated in real-time as the backup is running. When inline deduplication is used, only non-redundant storage blocks are sent to the backup target.
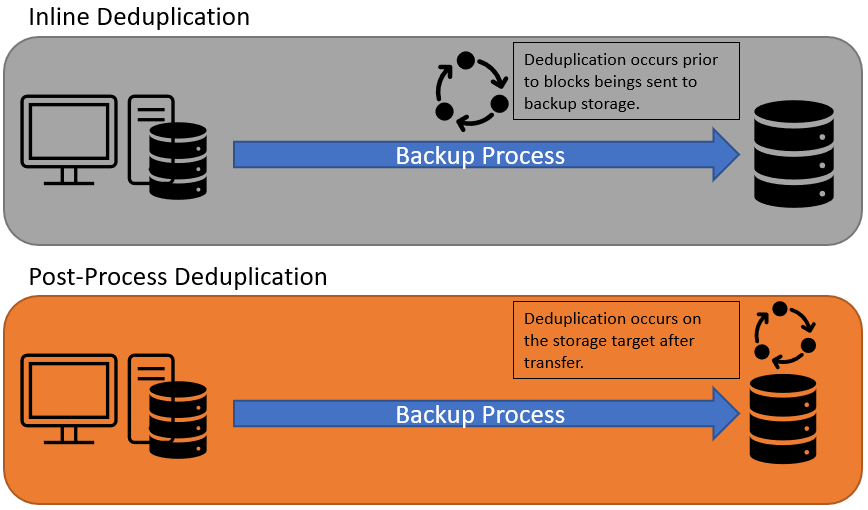
The second form of deduplication is post-process deduplication. When post-process deduplication is used, all storage blocks are backed up, regardless of whether they are unique or not. Later, a scheduled process deduplicates the data that has been backed up. Post-process deduplication is effective, but it requires the backup target to have sufficient capacity to accommodate all of the data that is being backed up at its original size. Furthermore, data is not deduplicated prior to being sent to the backup target, which means that bandwidth consumption is higher than it would be with inline deduplication.
The third main type of deduplication is global deduplication. Global deduplication is essentially a combination of inline and post-process deduplication. Imagine, for example, that you needed to back up a dozen different servers, and you use inline deduplication to reduce the volume of data that is being sent to the backup target. Even though deduplication has been used, redundancy may still exist on the backup target because there may be data that exists on multiple servers. If, for example, all of the servers are running the same operating system, then the operating system files will be identical from one server to the next. Because redundancy could exist within the backup target, post-process deduplication is used as a secondary means of eliminating redundancy from the backup target.
Disadvantages of Deduplication
Deduplication can be a highly effective way to reduce the backup footprint. However, deduplication only works if redundancy exists. If every storage block is unique, then there is nothing to deduplicate (although some deduplication algorithms work on the sub-block level).
A secondary disadvantage to deduplication is that the deduplication process tends to be resource-intensive. Inline deduplication, for instance, usually requires a significant amount of memory and CPU time, whereas post-process deduplication requires memory and CPU time, and also creates significant storage I/O. As such, it is necessary to ensure that you have sufficient hardware resources to support the use of deduplication.
What is Compression?
Like data deduplication, compression is a technique that is used to reduce the storage footprint of data. Whereas deduplication commonly occurs at the block level, however, compression generally occurs at the file level.
Data compression can be classified as being either lossy or lossless. Lossy compression is used in the creation of digital media files. The MP3 format, for example, allows an entire song to be stored in just a few MB of space but does so at the cost of audio fidelity. The lossy conversion process reduces the recording’s bitrate to save storage space, but the resulting audio file may not sound quite as good as the original recording.
In contrast, compression is also used in some data backup or data archiving applications. Because data loss is undesirable in such use cases, lossless compression is used.
Like lossy compression, lossless compression reduces a file’s size by removing information from the file. The difference is that the information removal is done in such a way that allows the file to be reconstructed to its original state.
There are numerous lossless file compression algorithms in existence, and each one works in a slightly different way. Generally speaking, however, most lossless file compression algorithms work by replacing recurring data within the file with a much smaller placeholder.
How Does Compression Work?
Compression can be used to reduce the size of a binary file, but for the sake of example, let’s pretend that we have a text file that contains the following text:
“Like lossy compression, lossless compression reduces a file’s size by removing information from the file. The difference is that the information removal is done in such a way that allows the file to be reconstructed to its original state.”
The first step in compressing this text file would be to use an algorithm to identify redundancy within the file. There are several ways of doing this. One option might be to identify words that are used more than once. For example, the word ‘compression’ appears twice, and the word ‘the’ appears four times.
Another option might be to look at groups of characters that commonly appear together. In the case of the word compression, for example, a space appears both before and after the word, and those spaces can be included in the redundant information. Similarly, the block of text uses the word lossy and the word lossless. Even though these words are different from one another, they both contain a leading space and the letters l, o, s, and s. Hence “ loss” could be considered to be part of the redundant data within the text block.
There are many different ways of identifying redundancy within a file, which is why there are so many different compression algorithms.
Generally speaking, once the redundancy is identified, the redundant data is replaced by a placeholder. An index is also used to keep track of the data that is associated with each placeholder. To give you a simple example, let’s pretend that we wanted to compress the previously referenced block of text by eliminating redundant words and word fragments (I won’t worry about spaces). Normally the placeholders would consist of an obscure binary string, but since this block of text does not include any numbers, let’s use numbers as placeholders for the sake of simplicity. So here is what the compressed text block might look like:
“Like 8y 1, 8less 1 reduces a 2’s size by 9ing 6 from 32. 3 difference 45369al 4 done in such a way 5 allows 327 be reconstructed 7 its original state.”
By compressing the data in this way, we have reduced its size from 237 bytes to a mere 157 bytes. That’s a huge reduction, even though I used a super simple compression technique. Real-life compression algorithms are far more efficient.
Of course, in reducing the data’s footprint, I have also rendered the text unreadable. But remember that one of the requirements of lossless compression is that there must be a way to reconstruct the data to its original state. For that, we need a reference table that maps the removed data to the placeholder values that were inserted in place of the data. Here is a very simple example of such a table:
1 = compression
2 = file
3 = the
4 = is
5 = that
6 = information
7 = to
8 = loss
9 = remove
Keep in mind that the index also has to be stored, and the overhead of storing the index slightly reduces the compression’s efficiency.
Disadvantages of Compression
Even though compression can significantly reduce a file’s size, there are two main disadvantages to its use. First, compressing a file puts the file into an unusable state, as you saw with the compressed text block above. Second, not all data can be compressed.
A file can only be compressed if there is redundancy within the file. A compressed media file such as an MP3 or an MP4 file is already compressed and usually cannot be further compressed. Similarly, a file containing random data may not contain a significant amount of redundancy and may therefore not be significantly uncompressible.
These Technologies in Action
We’ve discussed how these technologies work and have also discussed some disadvantages to plan for, but we haven’t really talked about the real-world benefit of deduplication and compression. As mentioned earlier, the main place you see these technologies in use is in the realm of backup. Backup, being an archival type service, aims to keep large amounts of data for long periods of time. The more efficient you can utilize the storage, the lower the cost.
For example, let’s say we have a working data set of 50TBs, with a similarity of data of roughly 20%. The like blocks are first deduped, bringing in our data set to 40TBs. Then let’s say we get a compression ratio of 30%. Combined, this would bring the storage requirements for the base set of data down to 28TBs as opposed to 50+.
It’s important to keep in mind that all data dedupes and compresses differently. On top of that, certain kinds of deduplication technologies work better in certain situations. For example, when you’re sending data to an offsite location, in-line deduplication is far superior because only the blocks that need to go are actually going across the wire.
It’s important to remember that your mileage may vary depending on your particular organization, but in all cases, both technologies will provide cost savings in terms of storage needed.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Brien Posey

