Save to My DOJO
In previous articles in this series, we started with the basics of Cluster-Aware Updating and then dove into the advanced options. Now we’re going to telescope those advanced features and work with the Pre- and Post- Update Script settings. These are extremely powerful but are very poorly documented.
Part 1: The Basics on Cluster-Aware Updating and Hyper-V | Part 2: Advanced Operators
The fields themselves are deceptively easy to understand. You just enter the name and location of a PowerShell script in each of the fields.
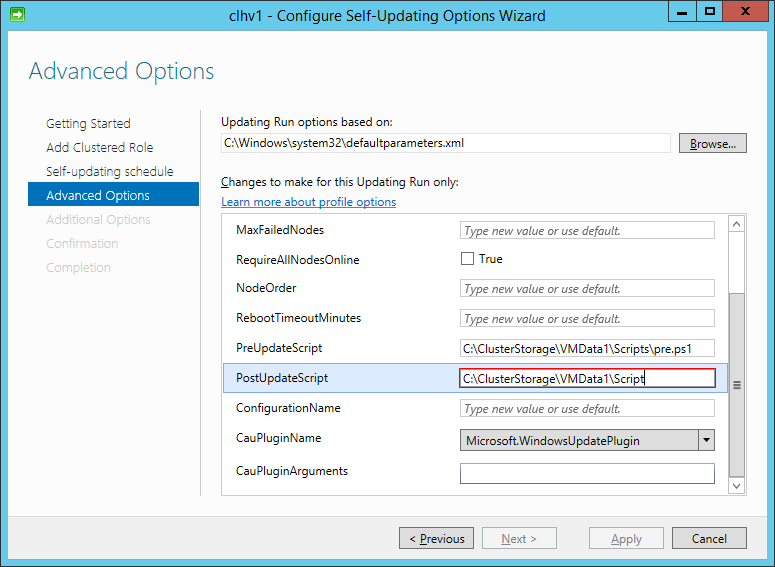
The red border around the field indicates that it’s validating the input. Interestingly, if you have an invalid script (by doing something like deleting the file later) and run Analyze cluster updating readiness from the main CAU screen, the applet will crash. It would be a little more helpful if it told you that the path was invalid, but I suppose you can’t have everything.
There are corresponding PreUpdateScript and PostUpdateScript fields on the Add-ClusterCAURole and Set-CAUClusterRole PowerShell cmdlets.
Script Location
Before you proceed happily along, be aware that script location is a really big issue. Remember how we said that CAU has two modes, the remote-updating and the self-updating modes, and that it was important to know the difference? The first reason was that you couldn’t run the remote-updating from a cluster node. The distinction really comes into play when you start talking about Pre- and Post-Update scripts.
When you perform a remote-updating (that’s when you go into the CAU GUI and select Apply cluster updates or use Invoke-CauRun in PowerShell), the script has to be visible from all nodes, and I think it also has to be accessible from the point you’re running the update from. Basically, I never got it to work right unless I had it on a share with read and execute permissions given to my administrative account, each computer node account, and the cluster node accounts (that includes the CAU account).
The self-updating mode is different. It can also work from a share point, but you can do more. The first thing I tried was putting it on a CSV, since the remote location no longer needed to see it, and that worked. The next thing I tried was having a script with the same name and the same location on the C: drive of each node… and that also worked… sort of. Please don’t walk away from the article at this point because you might be in for a nasty surprise.
When I first discovered the differences, I thought it meant that I’d be able to run a customized pre- and post-update script for each node in my cluster by placing a script with the same name and in the same location on each node’s local drive. Of course, I can also run the same script on each node, and that’s OK too. I was playing around with triggering off of the $env:COMPUTERNAME variable inside the single script when I started writing this blog post, and that’s when I started discovering some things I didn’t necessarily expect.
During testing, I put the following inside a script on my system named SVHV1:
$LogData += "Running on SVHV1 from $env:COMPUTERNAME"
When I opened up the log file, it contained this line: “Running on SVHV1 from SVHV2”.
What this means is that even though you can put a script on the local drive, it’s not going to run against the system that it is run from. So, no using a local script to work with local resources. In a cluster with greater than two nodes, you won’t even be able to guarantee which node will be the node that’s running the script.
That’s not all. This line:
$LogData += "PSScriptRoot is $PSScriptRoot"
This produced: “PSScriptRoot is ”
The problem here is that things like dot-sourcing are going to be troublesome. You’ll have to hard-code fully-qualified locations for everything. It’s not just $PSScriptRoot that’s not there. Most of the PowerShell entities, like $MyInvocation, that are usually available when a script is running aren’t going to be there. The script is being remotely invoked, so it behaves more like each line is running from the prompt.
In case you’re curious:
$LogData += ("Location is " + (Get-Location).Path)
Returned: “Location is C:UsersCLHV1-CAU$Documents”
I also like to write things to the event log. It’s always there and there’s no concern about running into anything weird like file system permissions. If you choose to do that in a CAU script, it will appear in the log of the node where the script is targeted. So, in my two node cluster, SVHV1 is the coordinator and it is running the script. It executes in the context of SVHV2. Anything sent to the Event Log (with Write-Event) will appear in SVHV2’s log.
Environment Data
You can’t use $MyInvocation etc., but you can get some data about the running environment. Get-CauRun can be called at any time during an update run. It emits a CauRun object with a number of properties. Of particular interest is NodeStatusNotifications. This contains a number of useful properties of its own, such as Status. Possible conditions of this property are:
- Waiting
- Scanning
- Staging
- RunningPreUpdateScript
- Suspending
- Installing
- Restarting
- Resuming
- RunningPostUpdateScript
NodeStatusNotifications also contains a Node property. So, if you have a node-specific action to perform in the pre-update script, then you execute this cmdlet and watch for the combination of the particular node and a status of RunningPreUpdateScript.
Dissecting the Results of Get-CauRun
Scripting against Get-CAURun isn’t the most intuitive thing I’ve ever done. Let me save you some headaches by showing you some run-throughs and the output.
We’ll start with a basic run:
PS C:> Get-CauRun -ClusterName clhv1
RunInProgress
RunId : 2b524a42-c190-4c5e-87e7-795fdf7d0356
RunStartTime : 5/17/2014 1:52:58 PM
CurrentOrchestrator : SVHV2
NodeStatusNotifications : {
Node : svhv1
Status : RunningPreUpdateScript
Timestamp : 5/17/2014 1:53:34 PM
}
NodeResults : {
Node : svhv2
Status : Succeeded
ErrorRecordData :
NumberOfSucceededUpdates : 0
NumberOfFailedUpdates : 0
InstallResults : Microsoft.ClusterAwareUpdating.UpdateInstallResult[]
}
Next, a look at only the notifications section:
PS C:> Get-CauRun -ClusterName clhv1 | select -Property NodeStatusNotifications | fl *
NodeStatusNotifications :
NodeStatusNotifications : {
Node : svhv1
Status : Waiting
Timestamp : 5/17/2014 1:57:30 PM
}
Retrieval of only the node property. Take special note of the double-dive into NodeStatusNotifications to get to the level that we need:
PS C:> Get-CauRun -ClusterName clhv1 | select -Property NodeStatusNotifications | select -ExpandProperty NodeStatusNotifications | select -Property Node Node ---- svhv1
Retrieval of the node object out of the node property. This could be used to assign the node to a variable:
(Get-CauRun -ClusterName clhv1 | select -Property NodeStatusNotifications | select -ExpandProperty NodeStatusNotifications | select -Property Node).Node ClusterName ClusterId NodeName NodeId ----------- --------- -------- ------ clhv1 ddcd4875-0a14-465d-9ece-fc... svhv1 00000000-0000-0000-0000-00...
Retrieval of the node name in its string format:
(Get-CauRun -ClusterName clhv1 | select -Property NodeStatusNotifications | select -ExpandProperty NodeStatusNotifications | select -Property Node).Node.NodeName svhv1
There seems to be a bit of a quicker way although it’s also a bit trickier.
Get the short status of nodes in a run:
PS C:> Get-CauRun -ClusterName clhv1 -ShowClusterNodeState CurrentOrchestratorId WmiObjectType NodeName --------------------- ------------- -------- 1ed5ce68-8396-4293-b092-065f1ad50dd7 MSFT_CAURun svhv1 1ed5ce68-8396-4293-b092-065f1ad50dd7 MSFT_CAURun svhv2 1ed5ce68-8396-4293-b092-065f1ad50dd7 MSFT_CAUNode svhv1
From the above, if you wanted to know which node was currently being updated, you could trap that like this (make sure to keep reading after the break for the but):
PS C:> Get-CauRun -ClusterName clhv1 -ShowClusterNodeState | where -Property WmiObjectType -eq "MSFT_CAUNode" | select -Property NodeName NodeName -------- svhv1
The problem with using this to trap the current node is that there are times during the run when there isn’t a target node, as in while downloads are occurring. Know what the above script gets you when that’s going on? A blank line. Or, if in a script, nothing. Know what you get when you run the above and there’s no CAU run going at all? A blank line. Or, if in a script, nothing. So, unlike calling Get-CauRun without -ShowClusterNodeState, you’d need a secondary call to find out if CAU is running at all. Of course, if you’re polling this from inside a pre- or post- update script, then there should always be an active node. In that case, this warning won’t apply.
Timing of CAU Pre- and Post- Scripts
Keep in mind that CAU runs the pre-update scripts before it puts the node into maintenance mode. Why does that matter? Well, because it lets you do all sorts of nifty things. For one thing, my attempts at using this blog to passively-aggressively convince Microsoft that real people in real situations use immobile virtual machines on clusters have, thus far, completely failed. So, if a cluster node reboots and it can’t move a VM due to Possible Owners restrictions, it saves it. Every time. No matter what. Don’t bother setting the Cluster-Controlled Action; it’s mostly just window-dressing now. Well, what if you don’t want your VMs to save? You can’t do anything about it on a regular reboot, but you can with a customized CAU script. You can’t just use CAU on its own; you must use a custom script because the CAU run doesn’t work like a standard node reboot. Not being able to drain a node causes the entire CAU run to fail.
Having the ability to automatically and pre-emptively deal with the problem in an update script lets you have your cake and eat it too. In case you’re curious, what we do is have the pre-shutdown script perform whatever steps are necessary to prepare the restricted VM for shutdown, then have it remove the node restrictions. The post-startup script returns the restrictions.
As an aside, I don’t know how common our use case is. We run some applications in our virtual machines that aren’t supported with virtual machine migrations of any kind, but we want them in the cluster so that in case of a node failure, bringing them up on another system is just a matter of changing the Possible Owners checkbox and turning them on. Even though it seems pretty logical to us, it’s apparently 22nd century thinking because we don’t get much support for it.
Will They or Won’t They?
Pop quiz question #1: I start a CAU cycle manually. Does the script run? Are you sure? How do you know?
If there are no updates for a node, the scripts don’t run on that node. If node one has a patch available and node two doesn’t, then node one will run its scripts and node two won’t. Nodes should usually be in sync on patches, but sometimes they aren’t for various reasons. The takeaway is that you can’t ever guarantee that all nodes will run scripts. This can make script testing difficult, which is an important thing to be aware of because a script that doesn’t throw an error but doesn’t work exactly the way you want could quickly run you out of patches to test with. While I was testing, I used a special WSUS computer group and only approved one patch at a time.
Pop quiz question #2: I start a CAU cycle manually. This month’s patches don’t require a reboot. Do the pre- and post- scripts run?
CAU doesn’t, and can’t, distinguish between a patch that needs a reboot and one that doesn’t. So, you could have patch cycles in which a node is never rebooted but all the scripts will run anyway. In our case, this is a little inconvenient as the processes we have to perform to shut some of these virtual machines down is tedious, but you still can’t have everything.
Retries
If a script fails, it will trigger the retry counter. As you’ll recall from the last post, CAU tries, then it retries. So if CAU is configured for 2 retries, your script will run up to three times.
Script errors are logged at Applications and Services Logs->Microsoft->Windows->ClusterAwareUpdating-Management as errors with event ID 1013. You can check on any node.
Conclusion
This ends our series on Cluster-Aware Updating for Hyper-V. I did some fairly intensive pre- and post- scripting for my employer, but, unfortunately I can’t share them due to a variety of restrictions. Once I figured out the ins-and-outs of the process, the scripting itself wasn’t that difficult. Rest assured, if I learn any other valuable lessons about CAU in my ventures, they’ll find their way onto this blog.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron

